 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Power of Combining Data and Knowledge: GPT-4o is an Effective Interpreter of Machine Learning Models in Predicting Lymph Node Metastasis of Lung Cancer
Jul 29, 2024Lymph node metastasis (LNM) is a crucial factor in determining the initial treatment for patients with lung cancer, yet accurate preoperative diagnosis of LNM remains challenging. Recently, large language models (LLMs) have garnered significant attention due to their remarkable text generation capabilities. Leveraging the extensive medical knowledge learned from vast corpora, LLMs can estimate probabilities for clinical problems, though their performance has historically been inferior to data-driven machine learning models. In this paper, we propose a novel ensemble method that combines the medical knowledge acquired by LLMs with the latent patterns identified by machine learning models to enhance LNM prediction performance. Initially, we developed machine learning models using patient data. We then designed a prompt template to integrate the patient data with the predicted probability from the machine learning model. Subsequently, we instructed GPT-4o, the most advanced LLM developed by OpenAI, to estimate the likelihood of LNM based on patient data and then adjust the estimate using the machine learning output. Finally, we collected three outputs from the GPT-4o using the same prompt and ensembled these results as the final prediction. Using the proposed method, our models achieved an AUC value of 0.765 and an AP value of 0.415 for LNM prediction, significantly improving predictive performance compared to baseline machine learning models. The experimental results indicate that GPT-4o can effectively leverage its medical knowledge and the probabilities predicted by machine learning models to achieve more accurate LNM predictions. These findings demonstrate that LLMs can perform well in clinical risk prediction tasks, offering a new paradigm for integrating medical knowledge and patient data in clinical predictions.
Boundary Detection Algorithm Inspired by Locally Linear Embedding
Jun 26, 2024



In the study of high-dimensional data, it is often assumed that the data set possesses an underlying lower-dimensional structure. A practical model for this structure is an embedded compact manifold with boundary. Since the underlying manifold structure is typically unknown, identifying boundary points from the data distributed on the manifold is crucial for various applications. In this work, we propose a method for detecting boundary points inspired by the widely used locally linear embedding algorithm. We implement this method using two nearest neighborhood search schemes: the $\epsilon$-radius ball scheme and the $K$-nearest neighbor scheme. This algorithm incorporates the geometric information of the data structure, particularly through its close relation with the local covariance matrix. We discuss the selection the key parameter and analyze the algorithm through our exploration of the spectral properties of the local covariance matrix in both neighborhood search schemes. Furthermore, we demonstrate the algorithm's performance with simulated examples.
Zero-shot information extraction from radiological reports using ChatGPT
Sep 07, 2023



Electronic health records contain an enormous amount of valuable information, but many are recorded in free text. Information extraction is the strategy to transform the sequence of characters into structured data, which can be employed for secondary analysis. However, the traditional information extraction components, such as named entity recognition and relation extraction, require annotated data to optimize the model parameters, which has become one of the major bottlenecks in building information extraction systems. With the large language models achieving good performances on various downstream NLP tasks without parameter tuning, it becomes possible to use large language models for zero-shot information extraction. In this study, we aim to explore whether the most popular large language model, ChatGPT, can extract useful information from the radiological reports. We first design the prompt template for the interested information in the CT reports. Then, we generate the prompts by combining the prompt template with the CT reports as the inputs of ChatGPT to obtain the responses. A post-processing module is developed to transform the responses into structured extraction results. We conducted the experiments with 847 CT reports collected from Peking University Cancer Hospital. The experimental results indicate that ChatGPT can achieve competitive performances for some extraction tasks compared with the baseline information extraction system, but some limitations need to be further improved.
Sensing Aided Covert Communications: Turning Interference into Allies
Jul 21, 2023



In this paper, we investigate the realization of covert communication in a general radar-communication cooperation system, which includes integrated sensing and communications as a special example. We explore the possibility of utilizing the sensing ability of radar to track and jam the aerial adversary target attempting to detect the transmission. Based on the echoes from the target, the extended Kalman filtering technique is employed to predict its trajectory as well as the corresponding channels. Depending on the maneuvering altitude of adversary target, two channel models are considered, with the aim of maximizing the covert transmission rate by jointly designing the radar waveform and communication transmit beamforming vector based on the constructed channels. For the free-space propagation model, by decoupling the joint design, we propose an efficient algorithm to guarantee that the target cannot detect the transmission. For the Rician fading model, since the multi-path components cannot be estimated, a robust joint transmission scheme is proposed based on the property of the Kullback-Leibler divergence. The convergence behaviour, tracking MSE, false alarm and missed detection probabilities, and covert transmission rate are evaluated. Simulation results show that the proposed algorithms achieve accurate tracking. For both channel models, the proposed sensing-assisted covert transmission design is able to guarantee the covertness, and significantly outperforms the conventional schemes.
Air-Ground Integrated Sensing and Communications: Opportunities and Challenges
Feb 13, 2023



The air-ground integrated sensing and communications (AG-ISAC) network, which consists of unmanned aerial vehicles (UAVs) and ground terrestrial networks, offers unique capabilities and demands special design techniques. In this article, we provide a review on AG-ISAC, by introducing UAVs as ``relay'' nodes for both communications and sensing to resolve the power and computation constraints on UAVs. We first introduce an AG-ISAC framework, including the system architecture and protocol. Four potential use cases are then discussed, with the analysis on the characteristics and merits of AG-ISAC networks. The research on several critical techniques for AG-ISAC is then discussed. Finally, we present our vision of the challenges and future research directions for AG-ISAC, to facilitate the advancement of the technology.
Improving Accuracy of Zero-Shot Action Recognition with Handcrafted Features
Jan 21, 2023With the development of machine learning, datasets for models are getting increasingly larger. This leads to increased data annotation costs and training time, which undoubtedly hinders the development of machine learning. To solve this problem, zero-shot learning is gaining considerable attention. With zero-shot learning, objects can be recognized or classified, even without having been seen before. Nevertheless, the accuracy of this method is still low, thus limiting its practical application. To solve this problem, we propose a video-text matching model, which can learn from handcrafted features. Our model can be used alone to predict the action classes and can also be added to any other model to improve its accuracy. Moreover, our model can be continuously optimized to improve its accuracy. We only need to manually annotate some features, which incurs some labor costs; in many situations, the costs are worth it. The results with UCF101 and HMDB51 show that our model achieves the best accuracy and also improves the accuracies of other models.
Privacy-Preserving Record Linkage for Cardinality Counting
Jan 09, 2023



Several applications require counting the number of distinct items in the data, which is known as the cardinality counting problem. Example applications include health applications such as rare disease patients counting for adequate awareness and funding, and counting the number of cases of a new disease for outbreak detection, marketing applications such as counting the visibility reached for a new product, and cybersecurity applications such as tracking the number of unique views of social media posts. The data needed for the counting is however often personal and sensitive, and need to be processed using privacy-preserving techniques. The quality of data in different databases, for example typos, errors and variations, poses additional challenges for accurate cardinality estimation. While privacy-preserving cardinality counting has gained much attention in the recent times and a few privacy-preserving algorithms have been developed for cardinality estimation, no work has so far been done on privacy-preserving cardinality counting using record linkage techniques with fuzzy matching and provable privacy guarantees. We propose a novel privacy-preserving record linkage algorithm using unsupervised clustering techniques to link and count the cardinality of individuals in multiple datasets without compromising their privacy or identity. In addition, existing Elbow methods to find the optimal number of clusters as the cardinality are far from accurate as they do not take into account the purity and completeness of generated clusters. We propose a novel method to find the optimal number of clusters in unsupervised learning. Our experimental results on real and synthetic datasets are highly promising in terms of significantly smaller error rate of less than 0.1 with a privacy budget {\epsilon} = 1.0 compared to the state-of-the-art fuzzy matching and clustering method.
GReS: Graphical Cross-domain Recommendation for Supply Chain Platform
Sep 02, 2022
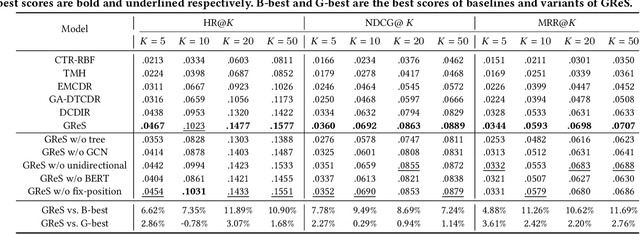
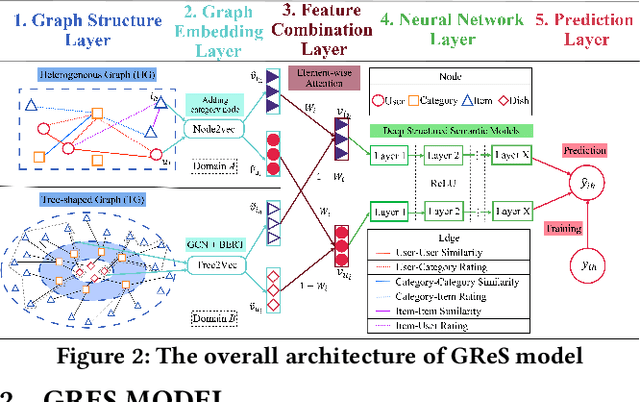
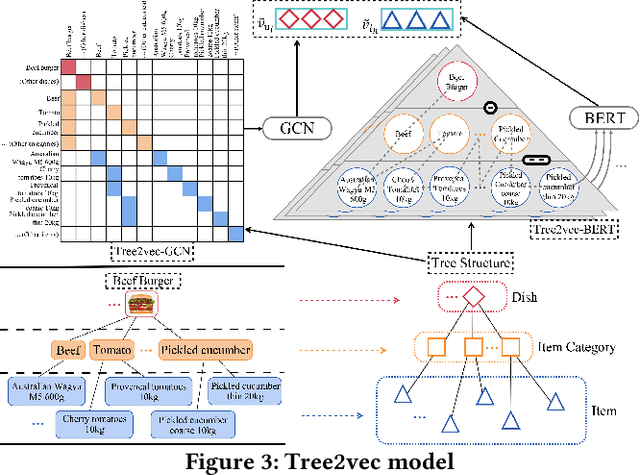
Supply Chain Platforms (SCPs) provide downstream industries with numerous raw materials. Compared with traditional e-commerce platforms, data in SCPs is more sparse due to limited user interests. To tackle the data sparsity problem, one can apply Cross-Domain Recommendation (CDR) which improves the recommendation performance of the target domain with the source domain information. However, applying CDR to SCPs directly ignores the hierarchical structure of commodities in SCPs, which reduce the recommendation performance. To leverage this feature, in this paper, we take the catering platform as an example and propose GReS, a graphical cross-domain recommendation model. The model first constructs a tree-shaped graph to represent the hierarchy of different nodes of dishes and ingredients, and then applies our proposed Tree2vec method combining GCN and BERT models to embed the graph for recommendations. Experimental results on a commercial dataset show that GReS significantly outperforms state-of-the-art methods in Cross-Domain Recommendation for Supply Chain Platforms.
Heterogeneous Graph Tree Networks
Sep 01, 2022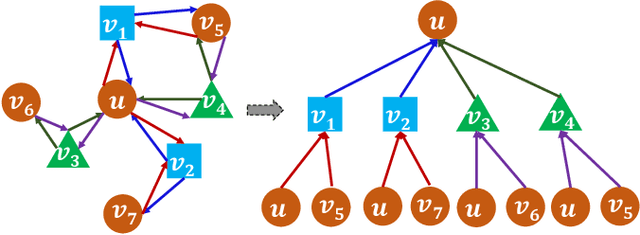
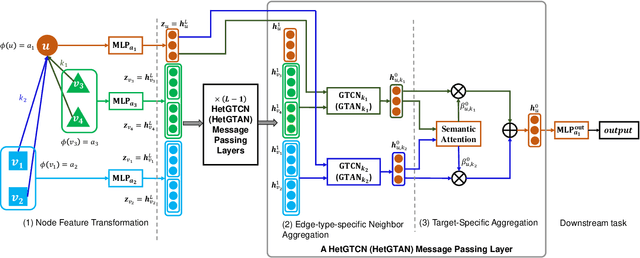
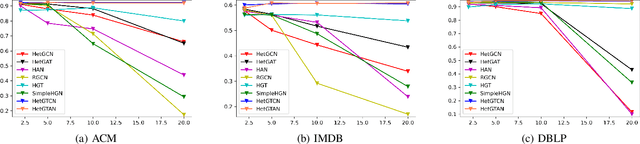
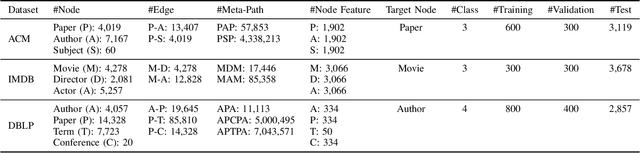
Heterogeneous graph neural networks (HGNNs) have attracted increasing research interest in recent three years. Most existing HGNNs fall into two classes. One class is meta-path-based HGNNs which either require domain knowledge to handcraft meta-paths or consume huge amount of time and memory to automatically construct meta-paths. The other class does not rely on meta-path construction. It takes homogeneous convolutional graph neural networks (Conv-GNNs) as backbones and extend them to heterogeneous graphs by introducing node-type- and edge-type-dependent parameters. Regardless of the meta-path dependency, most existing HGNNs employ shallow Conv-GNNs such as GCN and GAT to aggregate neighborhood information, and may have limited capability to capture information from high-order neighborhood. In this work, we propose two heterogeneous graph tree network models: Heterogeneous Graph Tree Convolutional Network (HetGTCN) and Heterogeneous Graph Tree Attention Network (HetGTAN), which do not rely on meta-paths to encode heterogeneity in both node features and graph structure. Extensive experiments on three real-world heterogeneous graph data demonstrate that the proposed HetGTCN and HetGTAN are efficient and consistently outperform all state-of-the-art HGNN baselines on semi-supervised node classification tasks, and can go deep without compromising performance.
Unsupervised Learning for Combinatorial Optimization with Principled Objective Relaxation
Jul 14, 2022


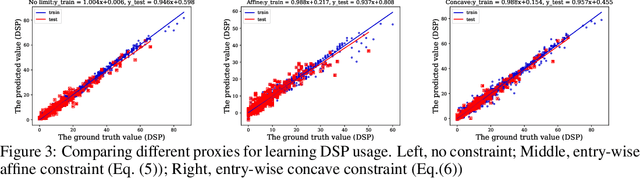
Using machine learning to solve combinatorial optimization (CO) problems is challenging, especially when the data is unlabeled. This work proposes an unsupervised learning framework for CO problems. Our framework follows a standard relaxation-plus-rounding approach and adopts neural networks to parameterize the relaxed solutions so that simple back-propagation can train the model end-to-end. Our key contribution is the observation that if the relaxed objective satisfies entry-wise concavity, a low optimization loss guarantees the quality of the final integral solutions. This observation significantly broadens the applicability of the previous framework inspired by Erdos' probabilistic method. In particular, this observation can guide the design of objective models in applications where the objectives are not given explicitly while requiring being modeled in prior. We evaluate our framework by solving a synthetic graph optimization problem, and two real-world applications including resource allocation in circuit design and approximate computing. Our framework largely outperforms the baselines based on na\"{i}ve relaxation, reinforcement learning, and Gumbel-softmax tricks.