 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised Scale-consistent Depth Learning from Video
May 25, 2021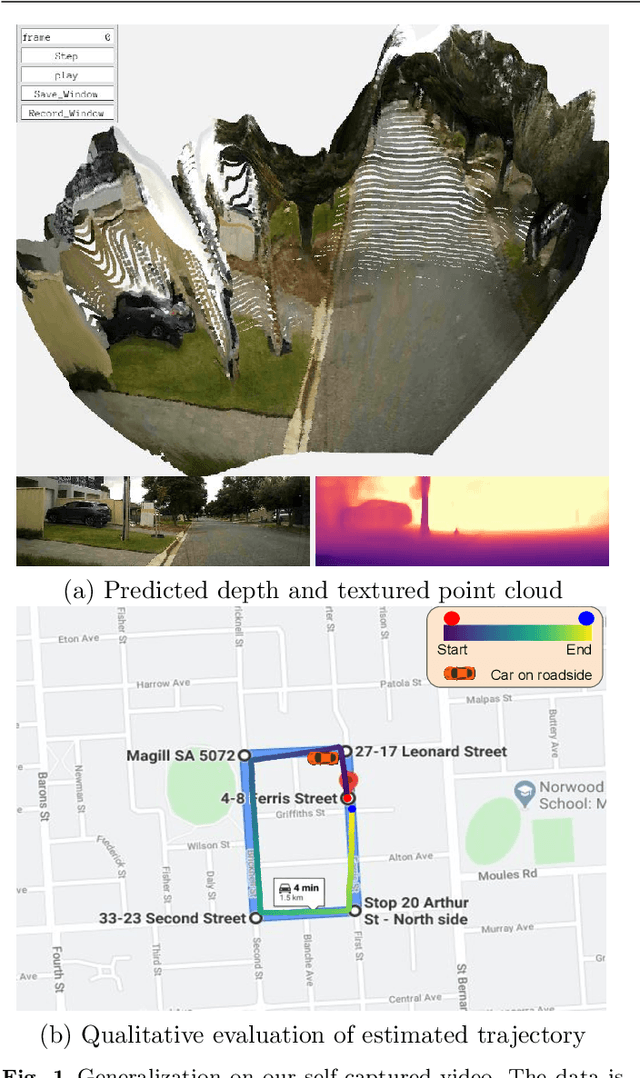
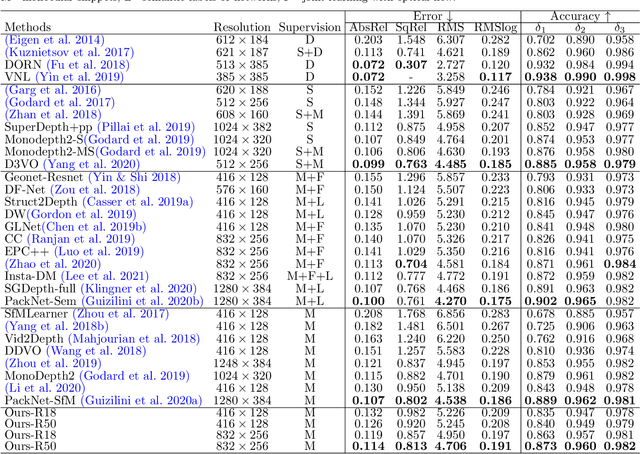
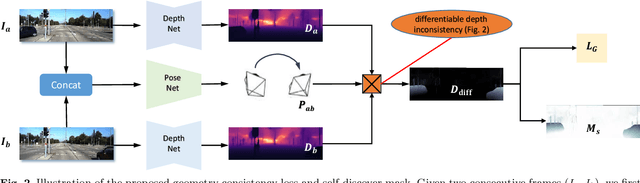
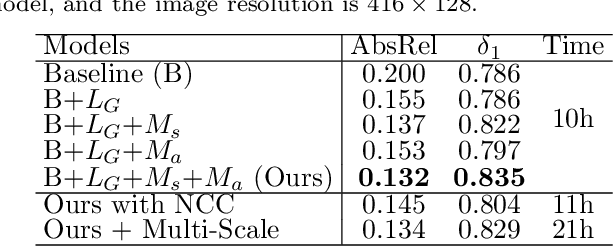
We propose a monocular depth estimator SC-Depth, which requires only unlabelled videos for training and enables the scale-consistent prediction at inference time. Our contributions include: (i) we propose a geometry consistency loss, which penalizes the inconsistency of predicted depths between adjacent views; (ii) we propose a self-discovered mask to automatically localize moving objects that violate the underlying static scene assumption and cause noisy signals during training; (iii) we demonstrate the efficacy of each component with a detailed ablation study and show high-quality depth estimation results in both KITTI and NYUv2 datasets. Moreover, thanks to the capability of scale-consistent prediction, we show that our monocular-trained deep networks are readily integrated into the ORB-SLAM2 system for more robust and accurate tracking. The proposed hybrid Pseudo-RGBD SLAM shows compelling results in KITTI, and it generalizes well to the KAIST dataset without additional training. Finally, we provide several demos for qualitative evaluation.
Direct Differentiable Augmentation Search
Apr 09, 2021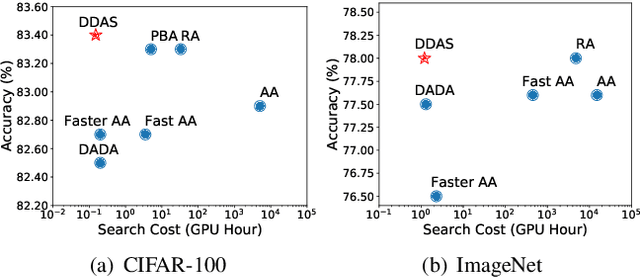

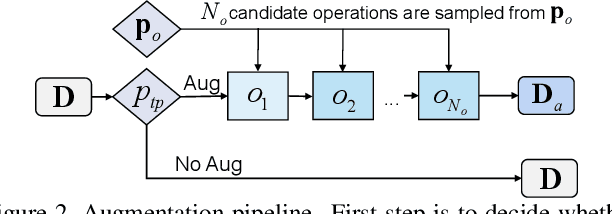
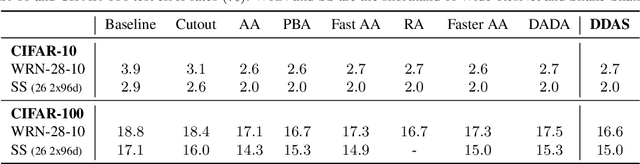
Data augmentation has been an indispensable tool to improve the performance of deep neural networks, however the augmentation can hardly transfer among different tasks and datasets. Consequently, a recent trend is to adopt AutoML technique to learn proper augmentation policy without extensive hand-crafted tuning. In this paper, we propose an efficient differentiable search algorithm called Direct Differentiable Augmentation Search (DDAS). It exploits meta-learning with one-step gradient update and continuous relaxation to the expected training loss for efficient search. Our DDAS can achieve efficient augmentation search without relying on approximations such as Gumbel Softmax or second order gradient approximation. To further reduce the adverse effect of improper augmentations, we organize the search space into a two level hierarchy, in which we first decide whether to apply augmentation, and then determine the specific augmentation policy. On standard image classification benchmarks, our DDAS achieves state-of-the-art performance and efficiency tradeoff while reducing the search cost dramatically, e.g. 0.15 GPU hours for CIFAR-10. In addition, we also use DDAS to search augmentation for object detection task and achieve comparable performance with AutoAugment, while being 1000x faster.
Learnable Graph Matching: Incorporating Graph Partitioning with Deep Feature Learning for Multiple Object Tracking
Mar 30, 2021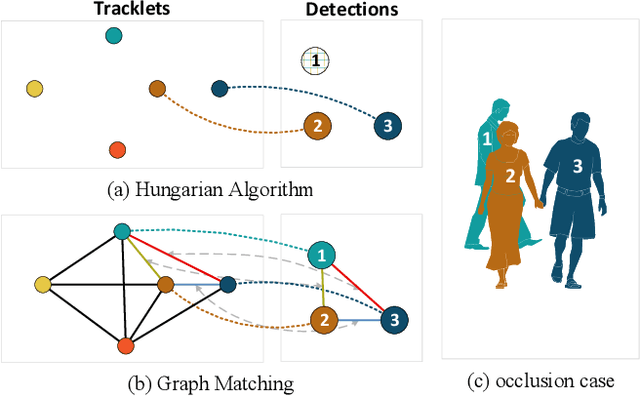
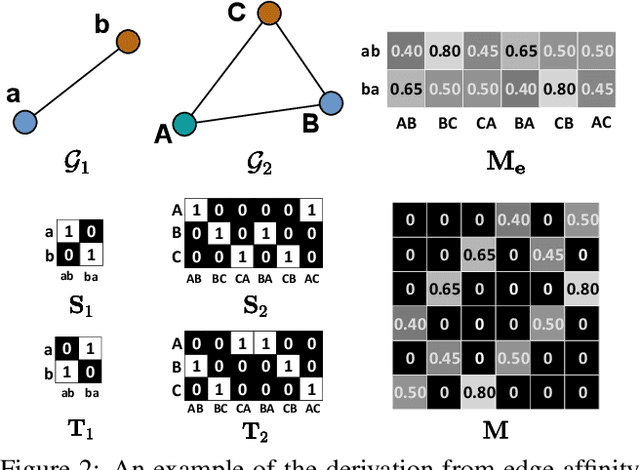

Data association across frames is at the core of Multiple Object Tracking (MOT) task. This problem is usually solved by a traditional graph-based optimization or directly learned via deep learning. Despite their popularity, we find some points worth studying in current paradigm: 1) Existing methods mostly ignore the context information among tracklets and intra-frame detections, which makes the tracker hard to survive in challenging cases like severe occlusion. 2) The end-to-end association methods solely rely on the data fitting power of deep neural networks, while they hardly utilize the advantage of optimization-based assignment methods. 3) The graph-based optimization methods mostly utilize a separate neural network to extract features, which brings the inconsistency between training and inference. Therefore, in this paper we propose a novel learnable graph matching method to address these issues. Briefly speaking, we model the relationships between tracklets and the intra-frame detections as a general undirected graph. Then the association problem turns into a general graph matching between tracklet graph and detection graph. Furthermore, to make the optimization end-to-end differentiable, we relax the original graph matching into continuous quadratic programming and then incorporate the training of it into a deep graph network with the help of the implicit function theorem. Lastly, our method GMTracker, achieves state-of-the-art performance on several standard MOT datasets. Our code will be available at https://github.com/jiaweihe1996/GMTracker .
LiDAR R-CNN: An Efficient and Universal 3D Object Detector
Mar 29, 2021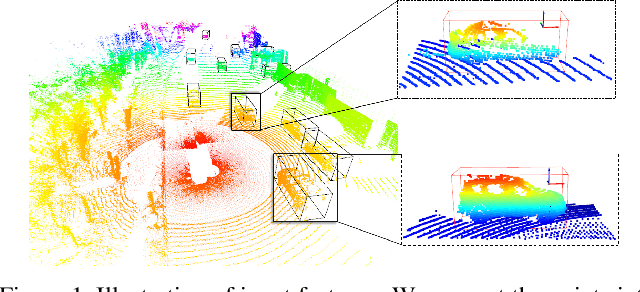
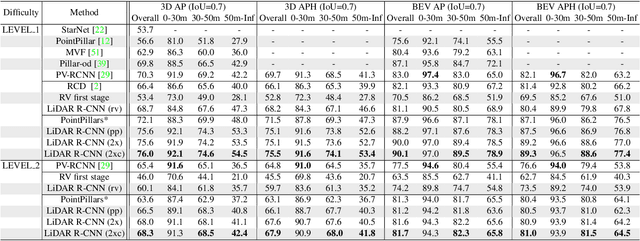
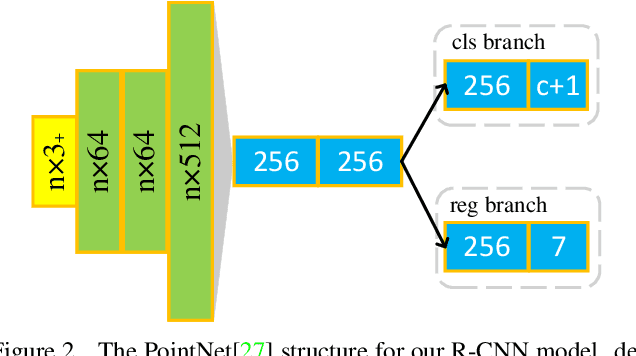
LiDAR-based 3D detection in point cloud is essential in the perception system of autonomous driving. In this paper, we present LiDAR R-CNN, a second stage detector that can generally improve any existing 3D detector. To fulfill the real-time and high precision requirement in practice, we resort to point-based approach other than the popular voxel-based approach. However, we find an overlooked issue in previous work: Naively applying point-based methods like PointNet could make the learned features ignore the size of proposals. To this end, we analyze this problem in detail and propose several methods to remedy it, which bring significant performance improvement. Comprehensive experimental results on real-world datasets like Waymo Open Dataset (WOD) and KITTI dataset with various popular detectors demonstrate the universality and superiority of our LiDAR R-CNN. In particular, based on one variant of PointPillars, our method could achieve new state-of-the-art results with minor cost. Codes will be released at https://github.com/tusimple/LiDAR_RCNN .
RangeDet:In Defense of Range View for LiDAR-based 3D Object Detection
Mar 18, 2021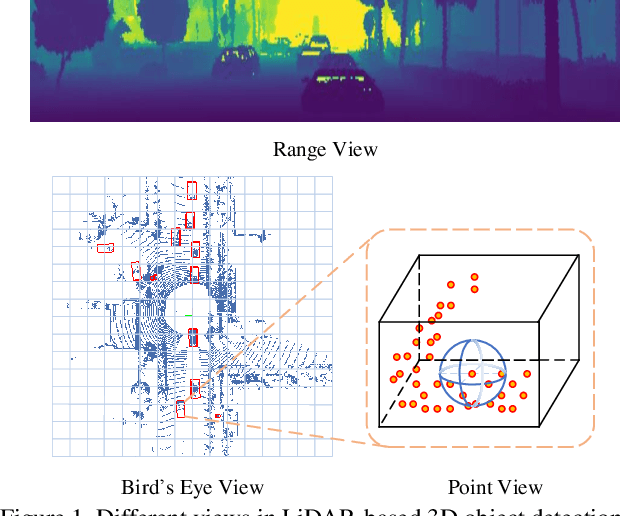
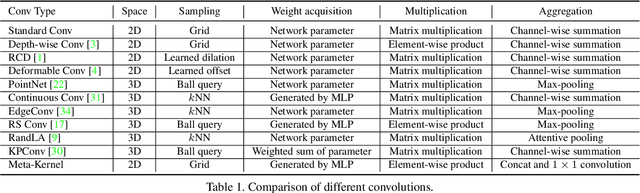
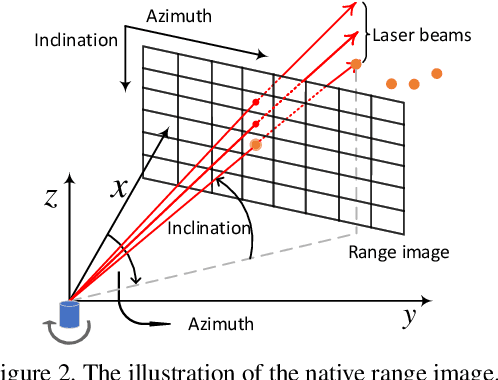
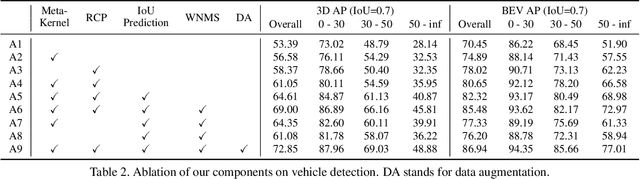
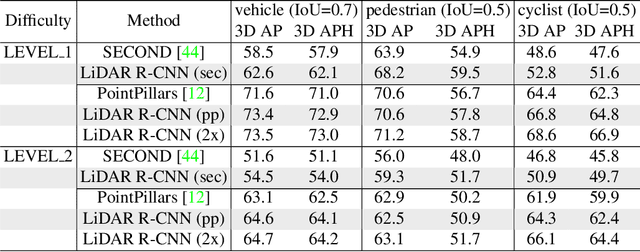
In this paper, we propose an anchor-free single-stage LiDAR-based 3D object detector -- RangeDet. The most notable difference with previous works is that our method is purely based on the range view representation. Compared with the commonly used voxelized or Bird's Eye View (BEV) representations, the range view representation is more compact and without quantization error. Although there are works adopting it for semantic segmentation, its performance in object detection is largely behind voxelized or BEV counterparts. We first analyze the existing range-view-based methods and find two issues overlooked by previous works: 1) the scale variation between nearby and far away objects; 2) the inconsistency between the 2D range image coordinates used in feature extraction and the 3D Cartesian coordinates used in output. Then we deliberately design three components to address these issues in our RangeDet. We test our RangeDet in the large-scale Waymo Open Dataset (WOD). Our best model achieves 72.9/75.9/65.8 3D AP on vehicle/pedestrian/cyclist. These results outperform other range-view-based methods by a large margin (~20 3D AP in vehicle detection), and are overall comparable with the state-of-the-art multi-view-based methods. Codes will be public.
QueryDet: Cascaded Sparse Query for Accelerating High-Resolution Small Object Detection
Mar 16, 2021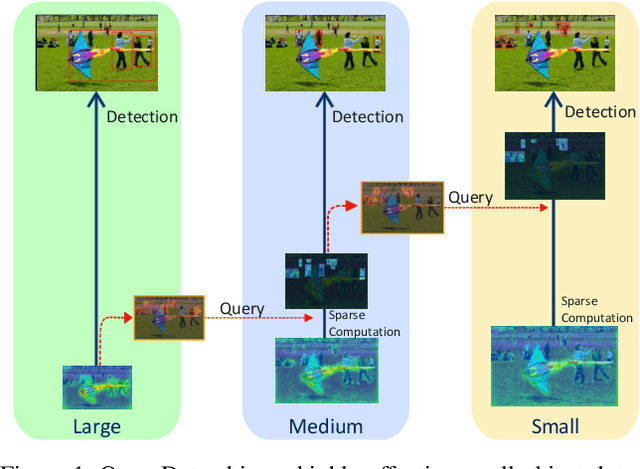
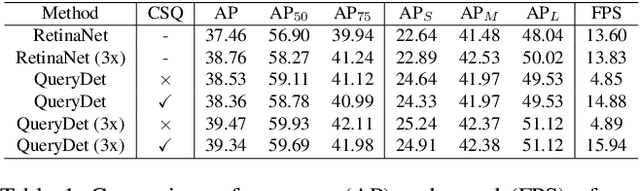
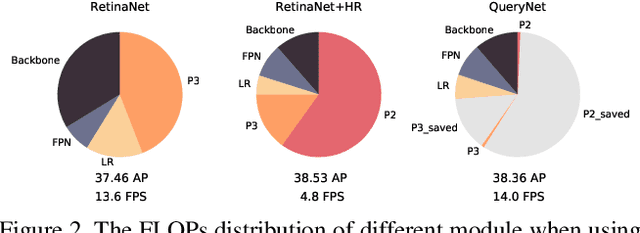
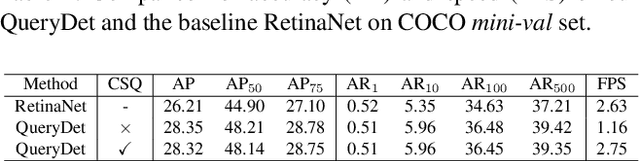
While general object detection with deep learning has achieved great success in the past few years, the performance and efficiency of detecting small objects are far from satisfactory. The most common and effective way to promote small object detection is to use high-resolution images or feature maps. However, both approaches induce costly computation since the computational cost grows squarely as the size of images and features increases. To get the best of two worlds, we propose QueryDet that uses a novel query mechanism to accelerate the inference speed of feature-pyramid based object detectors. The pipeline composes two steps: it first predicts the coarse locations of small objects on low-resolution features and then computes the accurate detection results using high-resolution features sparsely guided by those coarse positions. In this way, we can not only harvest the benefit of high-resolution feature maps but also avoid useless computation for the background area. On the popular COCO dataset, the proposed method improves the detection mAP by 1.0 and mAP-small by 2.0, and the high-resolution inference speed is improved to 3.0x on average. On VisDrone dataset, which contains more small objects, we create a new state-of-the-art while gaining a 2.3x high-resolution acceleration on average. Code is available at: https://github.com/ChenhongyiYang/QueryDet-PyTorch
Model-free Vehicle Tracking and State Estimation in Point Cloud Sequences
Mar 10, 2021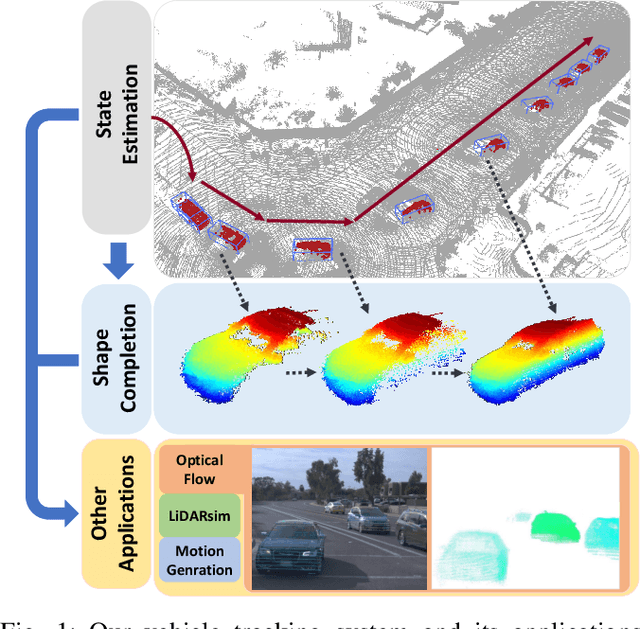
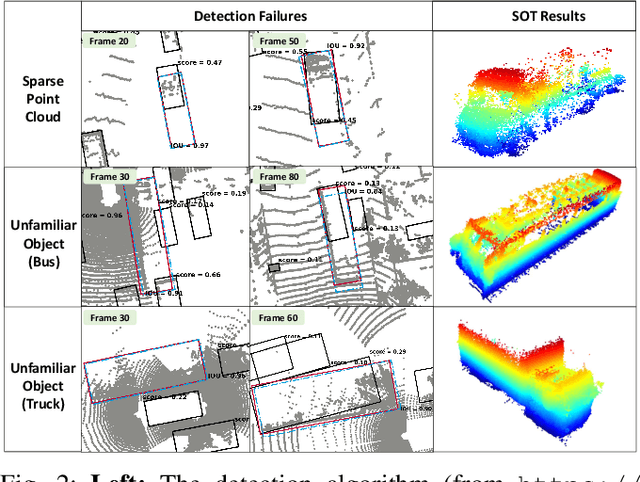
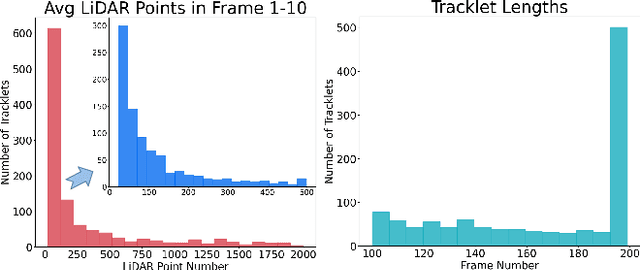
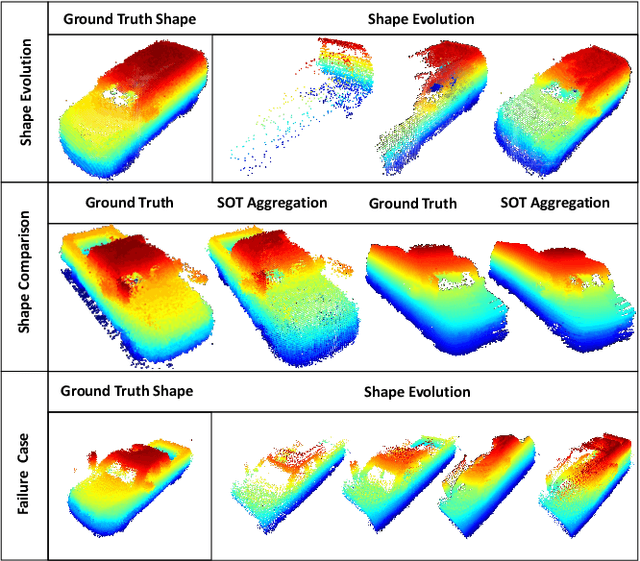
Estimating the states of surrounding traffic participants stays at the core of autonomous driving. In this paper, we study a novel setting of this problem: model-free single object tracking (SOT), which takes the object state in the first frame as input, and jointly solves state estimation and tracking in subsequent frames. The main purpose for this new setting is to break the strong limitation of the popular "detection and tracking" scheme in multi-object tracking. Moreover, we notice that shape completion by overlaying the point clouds, which is a by-product of our proposed task, not only improves the performance of state estimation but also has numerous applications. As no benchmark for this task is available so far, we construct a new dataset LiDAR-SOT and corresponding evaluation protocols based on the Waymo Open dataset. We then propose an optimization-based algorithm called SOTracker based on point cloud registration, vehicle shapes, and motion priors. Our quantitative and qualitative results prove the effectiveness of our SOTracker and reveal the challenging cases for SOT in point clouds, including the sparsity of LiDAR data, abrupt motion variation, etc. Finally, we also explore how the proposed task and algorithm may benefit other autonomous driving applications, including simulating LiDAR scans, generating motion data, and annotating optical flow. The code and protocols for our benchmark and algorithm are available at https://github.com/TuSimple/LiDAR_SOT/ . A video demonstration is at https://www.youtube.com/watch?v=BpHixKs91i8 .
1st Place Solutions of Waymo Open Dataset Challenge 2020 -- 2D Object Detection Track
Aug 04, 2020In this technical report, we present our solutions of Waymo Open Dataset (WOD) Challenge 2020 - 2D Object Track. We adopt FPN as our basic framework. Cascade RCNN, stacked PAFPN Neck and Double-Head are used for performance improvements. In order to handle the small object detection problem in WOD, we use very large image scales for both training and testing. Using our methods, our team RW-TSDet achieved the 1st place in the 2D Object Detection Track.
Unsupervised Depth Learning in Challenging Indoor Video: Weak Rectification to Rescue
Jun 04, 2020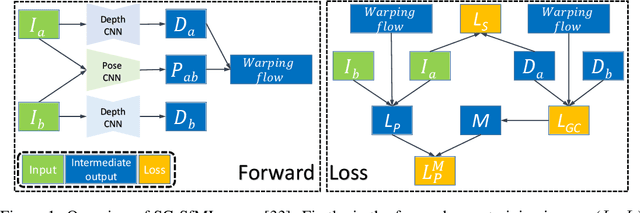
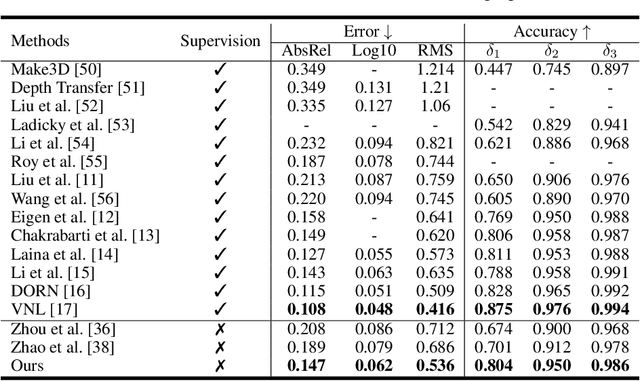
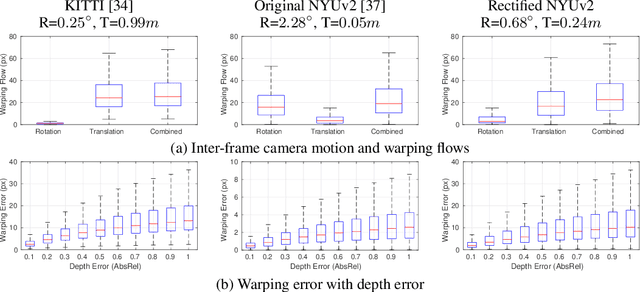
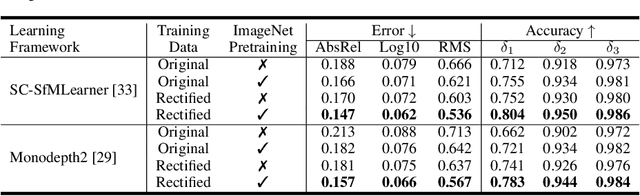
Single-view depth estimation using CNNs trained from unlabelled videos has shown significant promise. However, the excellent results have mostly been obtained in street-scene driving scenarios, and such methods often fail in other settings, particularly indoor videos taken by handheld devices, in which case the ego-motion is often degenerate, i.e., the rotation dominates the translation. In this work, we establish that the degenerate camera motions exhibited in handheld settings are a critical obstacle for unsupervised depth learning. A main contribution of our work is fundamental analysis which shows that the rotation behaves as noise during training, as opposed to the translation (baseline) which provides supervision signals. To capitalise on our findings, we propose a novel data pre-processing method for effective training, i.e., we search for image pairs with modest translation and remove their rotation via the proposed weak image rectification. With our pre-processing, existing unsupervised models can be trained well in challenging scenarios (e.g., NYUv2 dataset), and the results outperform the unsupervised SOTA by a large margin (0.147 vs. 0.189 in the AbsRel error).
UST: Unifying Spatio-Temporal Context for Trajectory Prediction in Autonomous Driving
May 06, 2020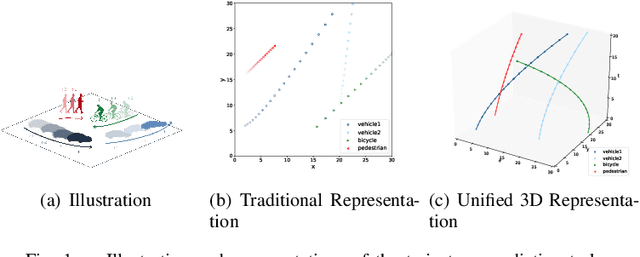
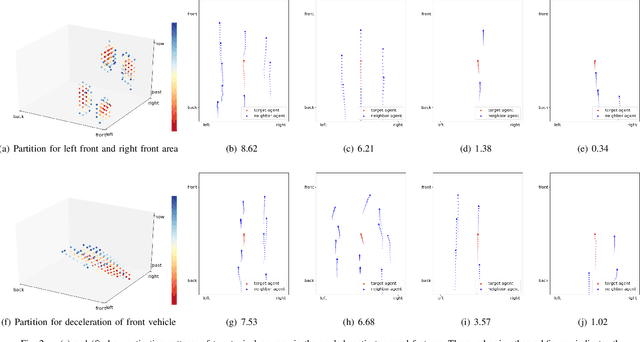

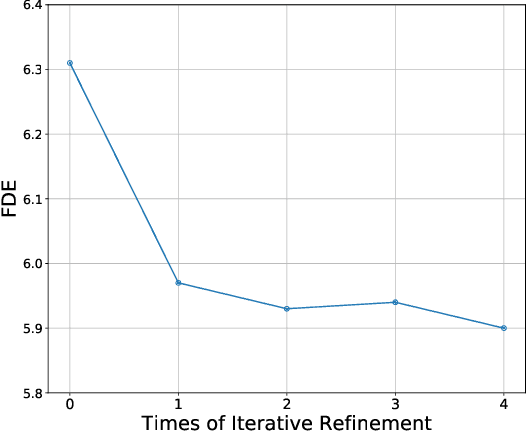
Trajectory prediction has always been a challenging problem for autonomous driving, since it needs to infer the latent intention from the behaviors and interactions from traffic participants. This problem is intrinsically hard, because each participant may behave differently under different environments and interactions. This key is to effectively model the interlaced influence from both spatial context and temporal context. Existing work usually encodes these two types of context separately, which would lead to inferior modeling of the scenarios. In this paper, we first propose a unified approach to treat time and space dimensions equally for modeling spatio-temporal context. The proposed module is simple and easy to implement within several lines of codes. In contrast to existing methods which heavily rely on recurrent neural network for temporal context and hand-crafted structure for spatial context, our method could automatically partition the spatio-temporal space to adapt the data. Lastly, we test our proposed framework on two recently proposed trajectory prediction dataset ApolloScape and Argoverse. We show that the proposed method substantially outperforms the previous state-of-the-art methods while maintaining its simplicity. These encouraging results further validate the superiority of our approach.