 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCircles are like Ellipses, or Ellipses are like Circles? Measuring the Degree of Asymmetry of Static and Contextual Embeddings and the Implications to Representation Learning
Dec 03, 2020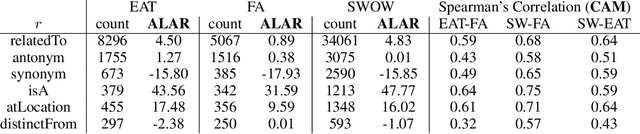
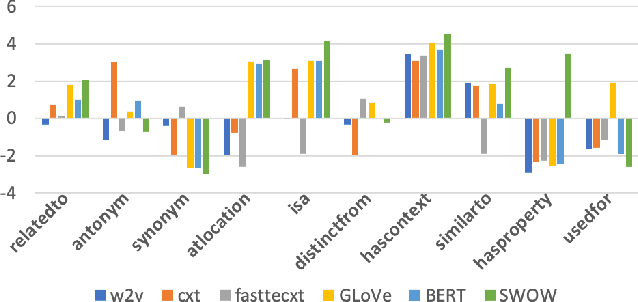
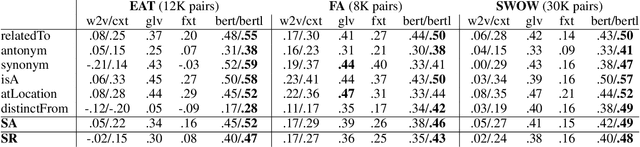
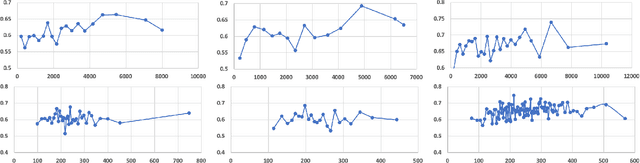
Human judgments of word similarity have been a popular method of evaluating the quality of word embedding. But it fails to measure the geometry properties such as asymmetry. For example, it is more natural to say "Ellipses are like Circles" than "Circles are like Ellipses". Such asymmetry has been observed from a psychoanalysis test called word evocation experiment, where one word is used to recall another. Although useful, such experimental data have been significantly understudied for measuring embedding quality. In this paper, we use three well-known evocation datasets to gain insights into asymmetry encoding of embedding. We study both static embedding as well as contextual embedding, such as BERT. Evaluating asymmetry for BERT is generally hard due to the dynamic nature of embedding. Thus, we probe BERT's conditional probabilities (as a language model) using a large number of Wikipedia contexts to derive a theoretically justifiable Bayesian asymmetry score. The result shows that contextual embedding shows randomness than static embedding on similarity judgments while performing well on asymmetry judgment, which aligns with its strong performance on "extrinsic evaluations" such as text classification. The asymmetry judgment and the Bayesian approach provides a new perspective to evaluate contextual embedding on intrinsic evaluation, and its comparison to similarity evaluation concludes our work with a discussion on the current state and the future of representation learning.
Continual learning with direction-constrained optimization
Nov 25, 2020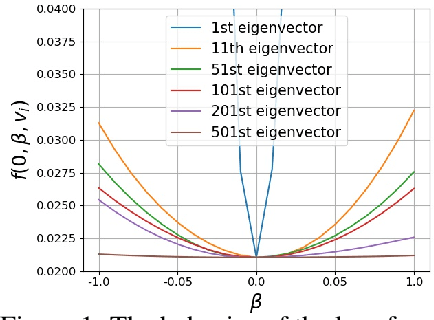
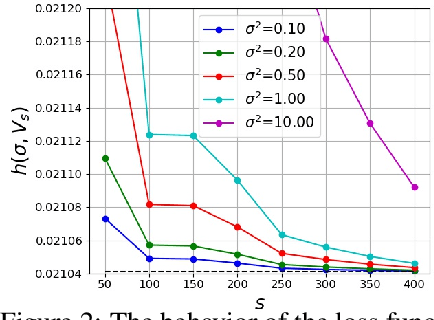

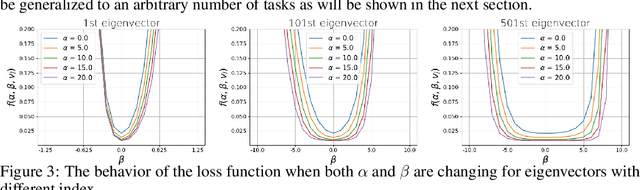
This paper studies a new design of the optimization algorithm for training deep learning models with a fixed architecture of the classification network in a continual learning framework, where the training data is non-stationary and the non-stationarity is imposed by a sequence of distinct tasks. This setting implies the existence of a manifold of network parameters that correspond to good performance of the network on all tasks. Our algorithm is derived from the geometrical properties of this manifold. We first analyze a deep model trained on only one learning task in isolation and identify a region in network parameter space, where the model performance is close to the recovered optimum. We provide empirical evidence that this region resembles a cone that expands along the convergence direction. We study the principal directions of the trajectory of the optimizer after convergence and show that traveling along a few top principal directions can quickly bring the parameters outside the cone but this is not the case for the remaining directions. We argue that catastrophic forgetting in a continual learning setting can be alleviated when the parameters are constrained to stay within the intersection of the plausible cones of individual tasks that were so far encountered during training. Enforcing this is equivalent to preventing the parameters from moving along the top principal directions of convergence corresponding to the past tasks. For each task we introduce a new linear autoencoder to approximate its corresponding top forbidden principal directions. They are then incorporated into the loss function in the form of a regularization term for the purpose of learning the coming tasks without forgetting. We empirically demonstrate that our algorithm performs favorably compared to other state-of-art regularization-based continual learning methods, including EWC and SI.
Deriving Commonsense Inference Tasks from Interactive Fictions
Oct 19, 2020

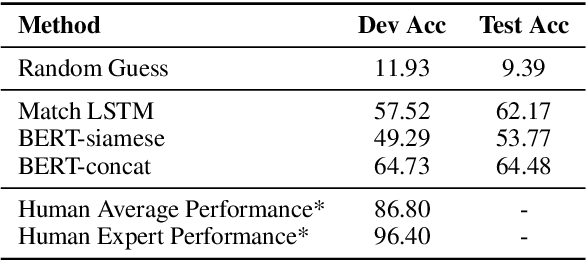
Commonsense reasoning simulates the human ability to make presumptions about our physical world, and it is an indispensable cornerstone in building general AI systems. We propose a new commonsense reasoning dataset based on human's interactive fiction game playings as human players demonstrate plentiful and diverse commonsense reasoning. The new dataset mitigates several limitations of the prior art. Experiments show that our task is solvable to human experts with sufficient commonsense knowledge but poses challenges to existing machine reading models, with a big performance gap of more than 30%.
Text-based RL Agents with Commonsense Knowledge: New Challenges, Environments and Baselines
Oct 08, 2020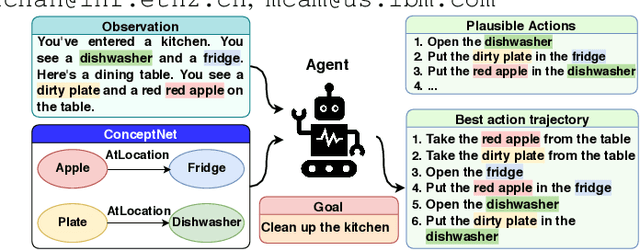


Text-based games have emerged as an important test-bed for Reinforcement Learning (RL) research, requiring RL agents to combine grounded language understanding with sequential decision making. In this paper, we examine the problem of infusing RL agents with commonsense knowledge. Such knowledge would allow agents to efficiently act in the world by pruning out implausible actions, and to perform look-ahead planning to determine how current actions might affect future world states. We design a new text-based gaming environment called TextWorld Commonsense (TWC) for training and evaluating RL agents with a specific kind of commonsense knowledge about objects, their attributes, and affordances. We also introduce several baseline RL agents which track the sequential context and dynamically retrieve the relevant commonsense knowledge from ConceptNet. We show that agents which incorporate commonsense knowledge in TWC perform better, while acting more efficiently. We conduct user-studies to estimate human performance on TWC and show that there is ample room for future improvement.
Interactive Fiction Game Playing as Multi-Paragraph Reading Comprehension with Reinforcement Learning
Oct 05, 2020
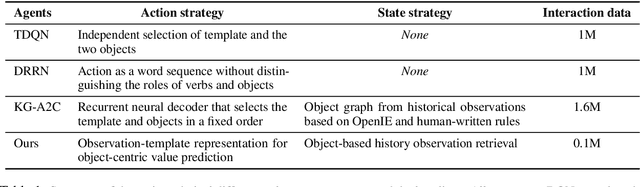
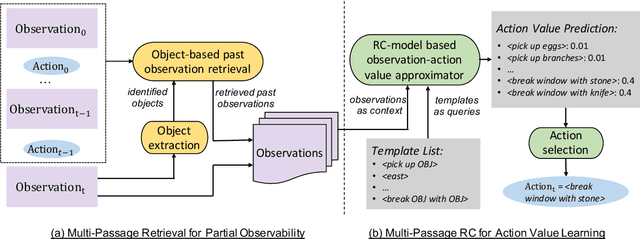
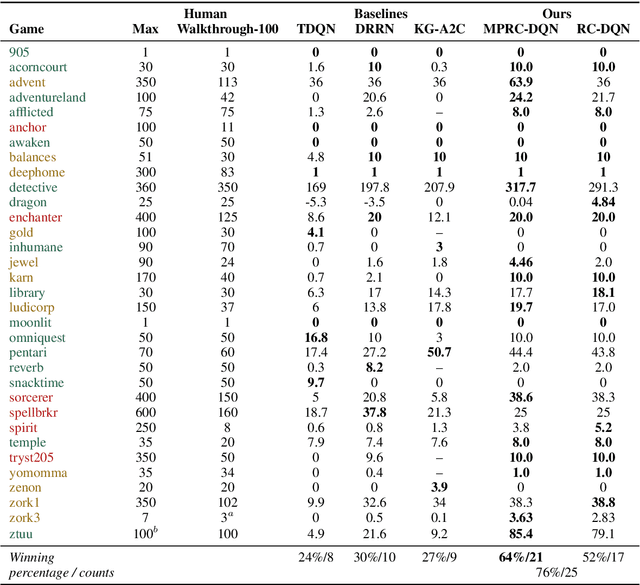
Interactive Fiction (IF) games with real human-written natural language texts provide a new natural evaluation for language understanding techniques. In contrast to previous text games with mostly synthetic texts, IF games pose language understanding challenges on the human-written textual descriptions of diverse and sophisticated game worlds and language generation challenges on the action command generation from less restricted combinatorial space. We take a novel perspective of IF game solving and re-formulate it as Multi-Passage Reading Comprehension (MPRC) tasks. Our approaches utilize the context-query attention mechanisms and the structured prediction in MPRC to efficiently generate and evaluate action outputs and apply an object-centric historical observation retrieval strategy to mitigate the partial observability of the textual observations. Extensive experiments on the recent IF benchmark (Jericho) demonstrate clear advantages of our approaches achieving high winning rates and low data requirements compared to all previous approaches. Our source code is available at: https://github.com/XiaoxiaoGuo/rcdqn.
A Study of Compositional Generalization in Neural Models
Jul 08, 2020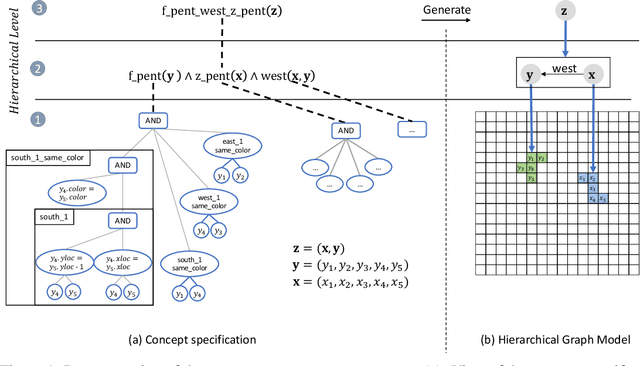
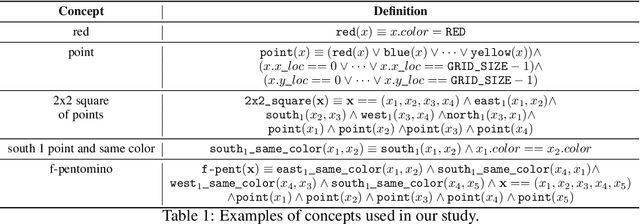
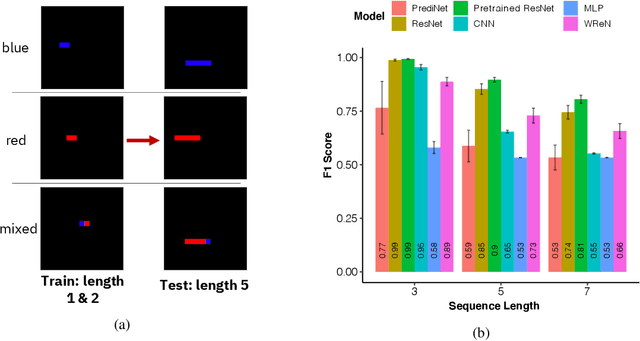
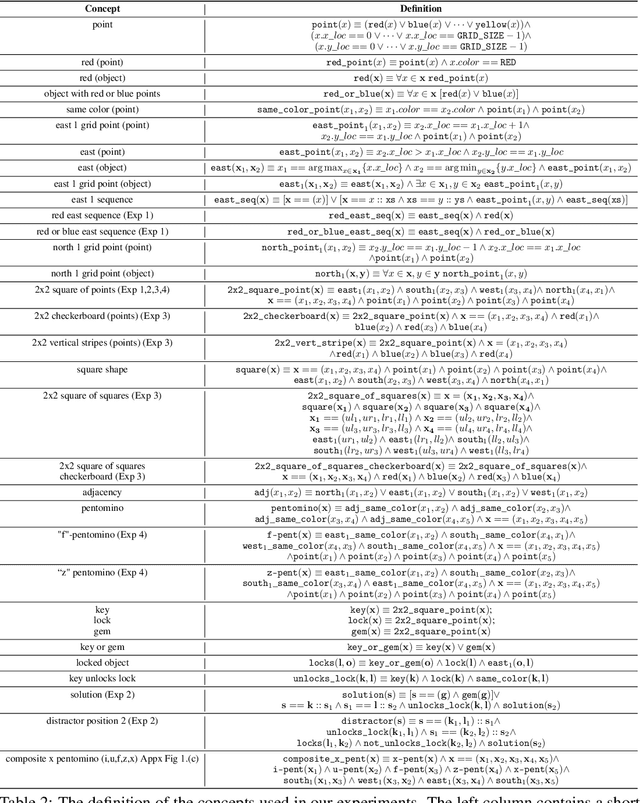
Compositional and relational learning is a hallmark of human intelligence, but one which presents challenges for neural models. One difficulty in the development of such models is the lack of benchmarks with clear compositional and relational task structure on which to systematically evaluate them. In this paper, we introduce an environment called ConceptWorld, which enables the generation of images from compositional and relational concepts, defined using a logical domain specific language. We use it to generate images for a variety of compositional structures: 2x2 squares, pentominoes, sequences, scenes involving these objects, and other more complex concepts. We perform experiments to test the ability of standard neural architectures to generalize on relations with compositional arguments as the compositional depth of those arguments increases and under substitution. We compare standard neural networks such as MLP, CNN and ResNet, as well as state-of-the-art relational networks including WReN and PrediNet in a multi-class image classification setting. For simple problems, all models generalize well to close concepts but struggle with longer compositional chains. For more complex tests involving substitutivity, all models struggle, even with short chains. In highlighting these difficulties and providing an environment for further experimentation, we hope to encourage the development of models which are able to generalize effectively in compositional, relational domains.
Learning to Recover Reasoning Chains for Multi-Hop Question Answering via Cooperative Games
Apr 06, 2020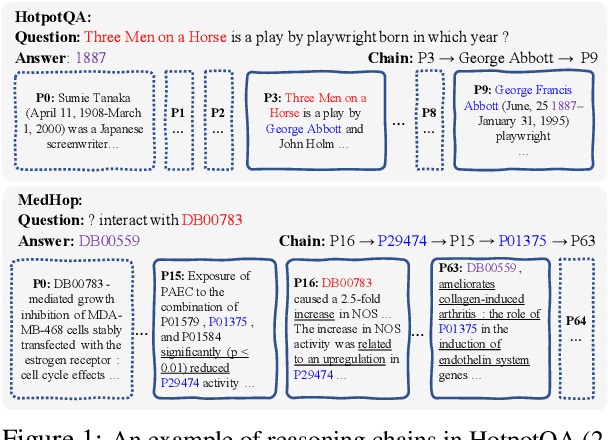
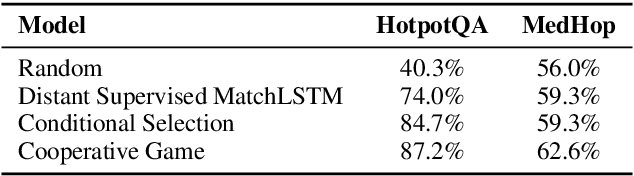
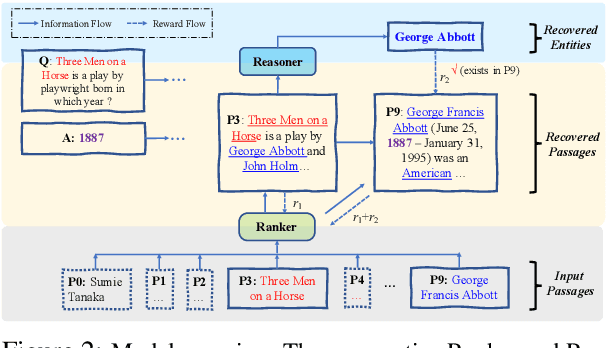

We propose the new problem of learning to recover reasoning chains from weakly supervised signals, i.e., the question-answer pairs. We propose a cooperative game approach to deal with this problem, in which how the evidence passages are selected and how the selected passages are connected are handled by two models that cooperate to select the most confident chains from a large set of candidates (from distant supervision). For evaluation, we created benchmarks based on two multi-hop QA datasets, HotpotQA and MedHop; and hand-labeled reasoning chains for the latter. The experimental results demonstrate the effectiveness of our proposed approach.
Simple yet Effective Bridge Reasoning for Open-Domain Multi-Hop Question Answering
Sep 17, 2019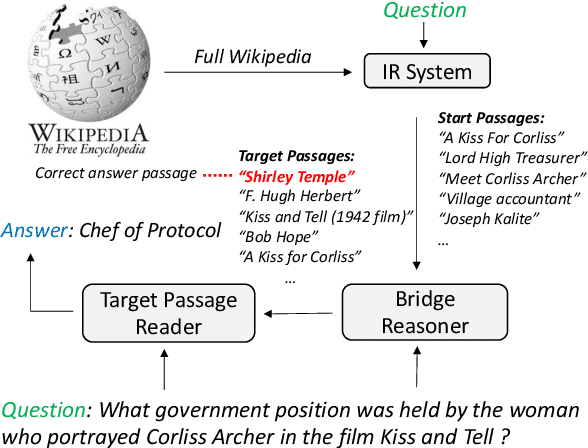

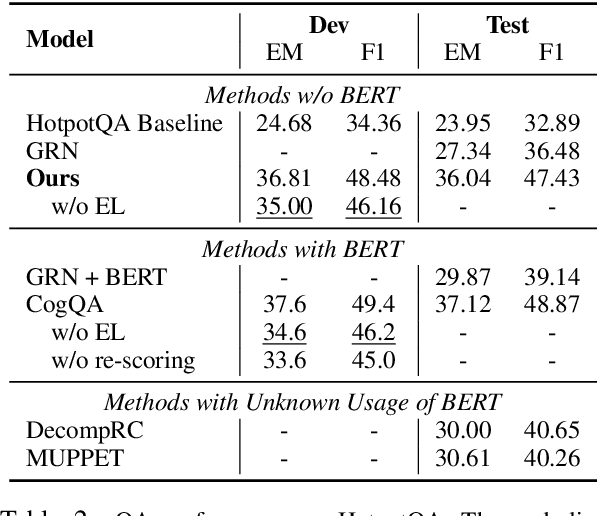
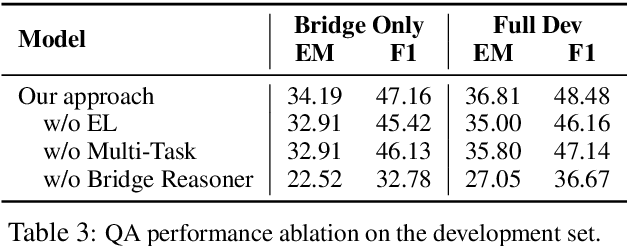
A key challenge of multi-hop question answering (QA) in the open-domain setting is to accurately retrieve the supporting passages from a large corpus. Existing work on open-domain QA typically relies on off-the-shelf information retrieval (IR) techniques to retrieve \textbf{answer passages}, i.e., the passages containing the groundtruth answers. However, IR-based approaches are insufficient for multi-hop questions, as the topic of the second or further hops is not explicitly covered by the question. To resolve this issue, we introduce a new sub-problem of open-domain multi-hop QA, which aims to recognize the bridge (\emph{i.e.}, the anchor that links to the answer passage) from the context of a set of start passages with a reading comprehension model. This model, the \textbf{bridge reasoner}, is trained with a weakly supervised signal and produces the candidate answer passages for the \textbf{passage reader} to extract the answer. On the full-wiki HotpotQA benchmark, we significantly improve the baseline method by 14 point F1. Without using any memory-inefficient contextual embeddings, our result is also competitive with the state-of-the-art that applies BERT in multiple modules.
Teaching AI to Explain its Decisions Using Embeddings and Multi-Task Learning
Jun 05, 2019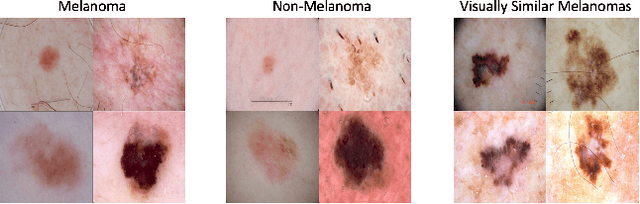
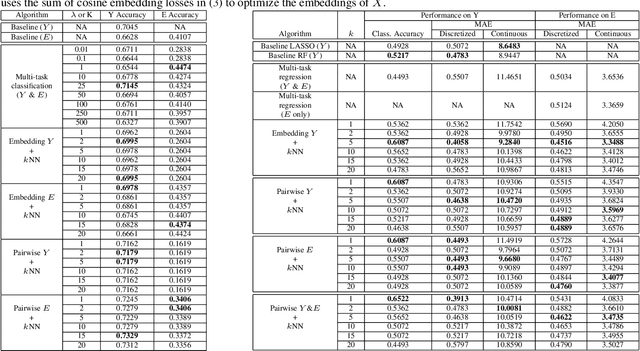
Using machine learning in high-stakes applications often requires predictions to be accompanied by explanations comprehensible to the domain user, who has ultimate responsibility for decisions and outcomes. Recently, a new framework for providing explanations, called TED, has been proposed to provide meaningful explanations for predictions. This framework augments training data to include explanations elicited from domain users, in addition to features and labels. This approach ensures that explanations for predictions are tailored to the complexity expectations and domain knowledge of the consumer. In this paper, we build on this foundational work, by exploring more sophisticated instantiations of the TED framework and empirically evaluate their effectiveness in two diverse domains, chemical odor and skin cancer prediction. Results demonstrate that meaningful explanations can be reliably taught to machine learning algorithms, and in some cases, improving modeling accuracy.
Hybrid Reinforcement Learning with Expert State Sequences
Mar 11, 2019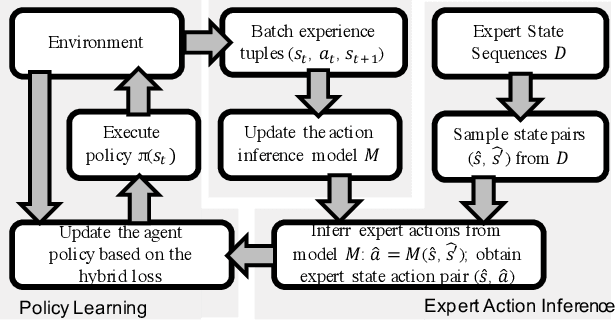
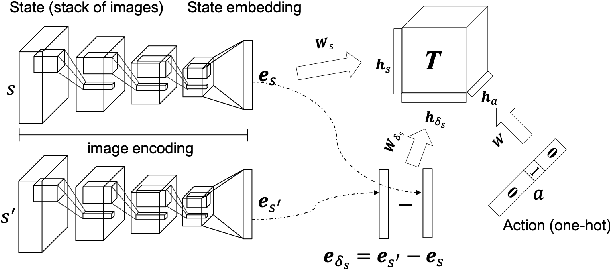
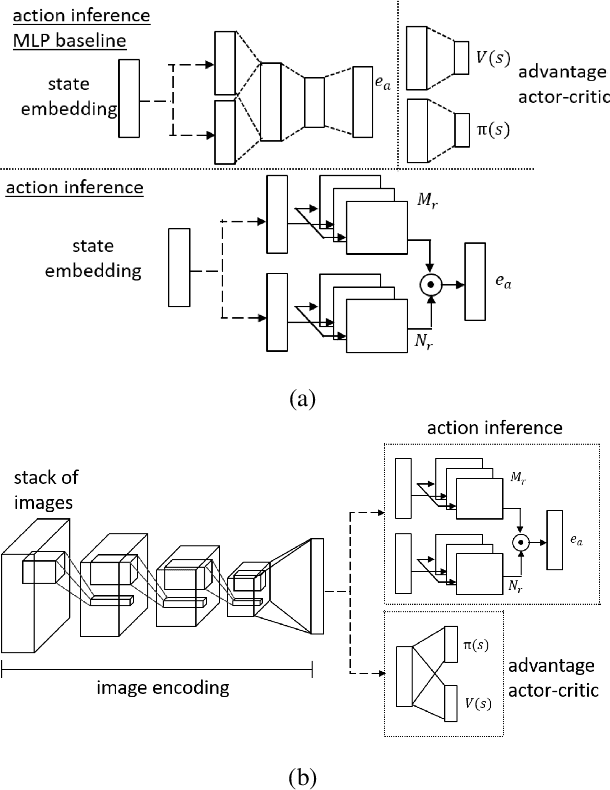
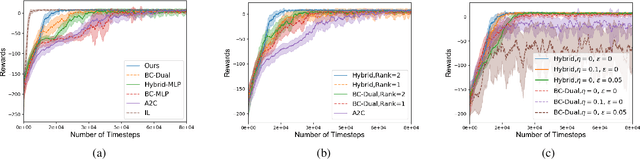
Existing imitation learning approaches often require that the complete demonstration data, including sequences of actions and states, are available. In this paper, we consider a more realistic and difficult scenario where a reinforcement learning agent only has access to the state sequences of an expert, while the expert actions are unobserved. We propose a novel tensor-based model to infer the unobserved actions of the expert state sequences. The policy of the agent is then optimized via a hybrid objective combining reinforcement learning and imitation learning. We evaluated our hybrid approach on an illustrative domain and Atari games. The empirical results show that (1) the agents are able to leverage state expert sequences to learn faster than pure reinforcement learning baselines, (2) our tensor-based action inference model is advantageous compared to standard deep neural networks in inferring expert actions, and (3) the hybrid policy optimization objective is robust against noise in expert state sequences.