 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInterpretable Multi-Objective Reinforcement Learning through Policy Orchestration
Paper and Code
Sep 21, 2018
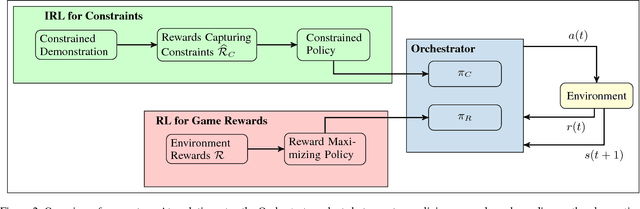
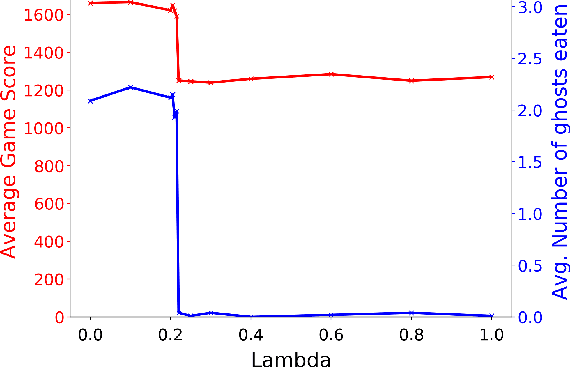
Autonomous cyber-physical agents and systems play an increasingly large role in our lives. To ensure that agents behave in ways aligned with the values of the societies in which they operate, we must develop techniques that allow these agents to not only maximize their reward in an environment, but also to learn and follow the implicit constraints of society. These constraints and norms can come from any number of sources including regulations, business process guidelines, laws, ethical principles, social norms, and moral values. We detail a novel approach that uses inverse reinforcement learning to learn a set of unspecified constraints from demonstrations of the task, and reinforcement learning to learn to maximize the environment rewards. More precisely, we assume that an agent can observe traces of behavior of members of the society but has no access to the explicit set of constraints that give rise to the observed behavior. Inverse reinforcement learning is used to learn such constraints, that are then combined with a possibly orthogonal value function through the use of a contextual bandit-based orchestrator that picks a contextually-appropriate choice between the two policies (constraint-based and environment reward-based) when taking actions. The contextual bandit orchestrator allows the agent to mix policies in novel ways, taking the best actions from either a reward maximizing or constrained policy. In addition, the orchestrator is transparent on which policy is being employed at each time step. We test our algorithms using a Pac-Man domain and show that the agent is able to learn to act optimally, act within the demonstrated constraints, and mix these two functions in complex ways.