Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Recover Reasoning Chains for Multi-Hop Question Answering via Cooperative Games
Paper and Code
Apr 06, 2020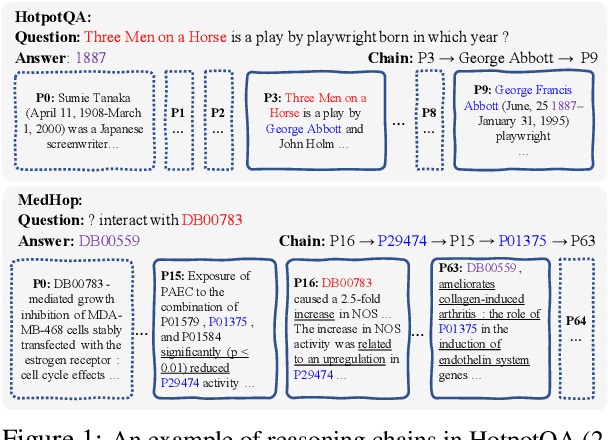
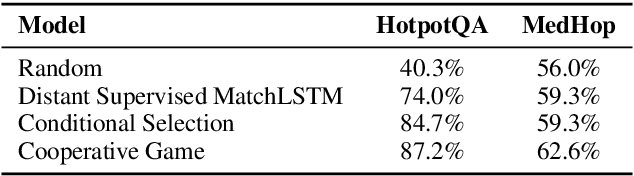
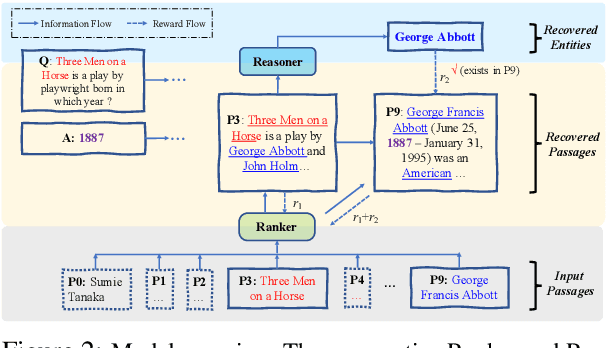

We propose the new problem of learning to recover reasoning chains from weakly supervised signals, i.e., the question-answer pairs. We propose a cooperative game approach to deal with this problem, in which how the evidence passages are selected and how the selected passages are connected are handled by two models that cooperate to select the most confident chains from a large set of candidates (from distant supervision). For evaluation, we created benchmarks based on two multi-hop QA datasets, HotpotQA and MedHop; and hand-labeled reasoning chains for the latter. The experimental results demonstrate the effectiveness of our proposed approach.
View paper on