 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Hierarchical Teaching in Cooperative Multiagent Reinforcement Learning
Paper and Code
Mar 07, 2019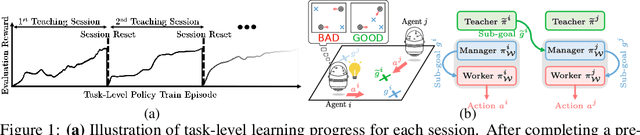
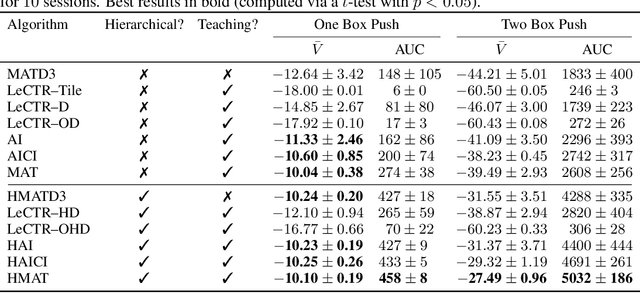
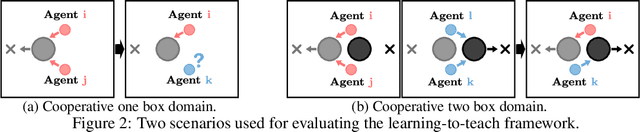

Heterogeneous knowledge naturally arises among different agents in cooperative multiagent reinforcement learning. As such, learning can be greatly improved if agents can effectively pass their knowledge on to other agents. Existing work has demonstrated that peer-to-peer knowledge transfer, a process referred to as action advising, improves team-wide learning. In contrast to previous frameworks that advise at the level of primitive actions, we aim to learn high-level teaching policies that decide when and what high-level action (e.g., sub-goal) to advise a teammate. We introduce a new learning to teach framework, called hierarchical multiagent teaching (HMAT). The proposed framework solves difficulties faced by prior work on multiagent teaching when operating in domains with long horizons, delayed rewards, and continuous states/actions by leveraging temporal abstraction and deep function approximation. Our empirical evaluations show that HMAT accelerates team-wide learning progress in difficult environments that are more complex than those explored in previous work. HMAT also learns teaching policies that can be transferred to different teammates/tasks and can even teach teammates with heterogeneous action spaces.