 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFanar 2.0: Arabic Generative AI Stack
Mar 17, 2026We present Fanar 2.0, the second generation of Qatar's Arabic-centric Generative AI platform. Sovereignty is a first-class design principle: every component, from data pipelines to deployment infrastructure, was designed and operated entirely at QCRI, Hamad Bin Khalifa University. Fanar 2.0 is a story of resource-constrained excellence: the effort ran on 256 NVIDIA H100 GPUs, with Arabic having only ~0.5% of web data despite 400 million native speakers. Fanar 2.0 adopts a disciplined strategy of data quality over quantity, targeted continual pre-training, and model merging to achieve substantial gains within these constraints. At the core is Fanar-27B, continually pre-trained from a Gemma-3-27B backbone on a curated corpus of 120 billion high-quality tokens across three data recipes. Despite using 8x fewer pre-training tokens than Fanar 1.0, it delivers substantial benchmark improvements: Arabic knowledge (+9.1 pts), language (+7.3 pts), dialects (+3.5 pts), and English capability (+7.6 pts). Beyond the core LLM, Fanar 2.0 introduces a rich stack of new capabilities. FanarGuard is a state-of-the-art 4B bilingual moderation filter for Arabic safety and cultural alignment. The speech family Aura gains a long-form ASR model for hours-long audio. Oryx vision family adds Arabic-aware image and video understanding alongside culturally grounded image generation. An agentic tool-calling framework enables multi-step workflows. Fanar-Sadiq utilizes a multi-agent architecture for Islamic content. Fanar-Diwan provides classical Arabic poetry generation. FanarShaheen delivers LLM-powered bilingual translation. A redesigned multi-layer orchestrator coordinates all components through intent-aware routing and defense-in-depth safety validation. Taken together, Fanar 2.0 demonstrates that sovereign, resource-constrained AI development can produce systems competitive with those built at far greater scale.
OMNIA: Closing the Loop by Leveraging LLMs for Knowledge Graph Completion
Mar 12, 2026Knowledge Graphs (KGs) are widely used to represent structured knowledge, yet their automatic construction, especially with Large Language Models (LLMs), often results in incomplete or noisy outputs. Knowledge Graph Completion (KGC) aims to infer and add missing triples, but most existing methods either rely on structural embeddings that overlook semantics or language models that ignore the graph's structure and depend on external sources. In this work, we present OMNIA, a two-stage approach that bridges structural and semantic reasoning for KGC. It first generates candidate triples by clustering semantically related entities and relations within the KG, then validates them through lightweight embedding filtering followed by LLM-based semantic validation. OMNIA performs on the internal KG, without external sources, and specifically targets implicit semantics that are most frequent in LLM-generated graphs. Extensive experiments on multiple datasets demonstrate that OMNIA significantly improves F1-score compared to traditional embedding-based models. These results highlight OMNIA's effectiveness and efficiency, as its clustering and filtering stages reduce both search space and validation cost while maintaining high-quality completion.
Fanar-Sadiq: A Multi-Agent Architecture for Grounded Islamic QA
Mar 10, 2026Large language models (LLMs) can answer religious knowledge queries fluently, yet they often hallucinate and misattribute sources, which is especially consequential in Islamic settings where users expect grounding in canonical texts (Qur'an and Hadith) and jurisprudential (fiqh) nuance. Retrieval-augmented generation (RAG) reduces some of these limitations by grounding generation in external evidence. However, a single ``retrieve-then-generate'' pipeline is limited to deal with the diversity of Islamic queries. Users may request verbatim scripture, fatwa-style guidance with citations or rule-constrained computations such as zakat and inheritance that require strict arithmetic and legal invariants. In this work, we present a bilingual (Arabic/English) multi-agent Islamic assistant, called Fanar-Sadiq, which is a core component of the Fanar AI platform. Fanar-Sadiq routes Islamic-related queries to specialized modules within an agentic, tool-using architecture. The system supports intent-aware routing, retrieval-grounded fiqh answers with deterministic citation normalization and verification traces, exact verse lookup with quotation validation, and deterministic calculators for Sunni zakat and inheritance with madhhab-sensitive branching. We evaluate the complete end-to-end system on public Islamic QA benchmarks and demonstrate effectiveness and efficiency. Our system is currently publicly and freely accessible through API and a Web application, and has been accessed $\approx$1.9M times in less than a year.
RetClean: Retrieval-Based Data Cleaning Using Foundation Models and Data Lakes
Mar 29, 2023


Can foundation models (such as ChatGPT) clean your data? In this proposal, we demonstrate that indeed ChatGPT can assist in data cleaning by suggesting corrections for specific cells in a data table (scenario 1). However, ChatGPT may struggle with datasets it has never encountered before (e.g., local enterprise data) or when the user requires an explanation of the source of the suggested clean values. To address these issues, we developed a retrieval-based method that complements ChatGPT's power with a user-provided data lake. The data lake is first indexed, we then retrieve the top-k relevant tuples to the user's query tuple and finally leverage ChatGPT to infer the correct value (scenario 2). Nevertheless, sharing enterprise data with ChatGPT, an externally hosted model, might not be feasible for privacy reasons. To assist with this scenario, we developed a custom RoBERTa-based foundation model that can be locally deployed. By fine-tuning it on a small number of examples, it can effectively make value inferences based on the retrieved tuples (scenario 3). Our proposed system, RetClean, seamlessly supports all three scenarios and provides a user-friendly GUI that enables the VLDB audience to explore and experiment with the system.
Relational Pretrained Transformers towards Democratizing Data Preparation [Vision]
Dec 04, 2020![Figure 1 for Relational Pretrained Transformers towards Democratizing Data Preparation [Vision]](/_next/image?url=https%3A%2F%2Fai2-s2-public.s3.amazonaws.com%2Ffigures%2F2017-08-08%2Fd51bec1426494f23de57b2c4184c7e26583eda53%2F1-Figure1-1.png&w=640&q=75)
![Figure 2 for Relational Pretrained Transformers towards Democratizing Data Preparation [Vision]](/_next/image?url=https%3A%2F%2Fai2-s2-public.s3.amazonaws.com%2Ffigures%2F2017-08-08%2Fd51bec1426494f23de57b2c4184c7e26583eda53%2F4-Table1-1.png&w=640&q=75)
![Figure 3 for Relational Pretrained Transformers towards Democratizing Data Preparation [Vision]](/_next/image?url=https%3A%2F%2Fai2-s2-public.s3.amazonaws.com%2Ffigures%2F2017-08-08%2Fd51bec1426494f23de57b2c4184c7e26583eda53%2F3-Figure2-1.png&w=640&q=75)
![Figure 4 for Relational Pretrained Transformers towards Democratizing Data Preparation [Vision]](/_next/image?url=https%3A%2F%2Fai2-s2-public.s3.amazonaws.com%2Ffigures%2F2017-08-08%2Fd51bec1426494f23de57b2c4184c7e26583eda53%2F6-Table2-1.png&w=640&q=75)
Can AI help automate human-easy but computer-hard data preparation tasks (for example, data cleaning, data integration, and information extraction), which currently heavily involve data scientists, practitioners, and crowd workers? We envision that human-easy data preparation for relational data can be automated. To this end, we first identify the desiderata for computers to achieve near-human intelligence for data preparation: computers need a deep-learning architecture (or model) that can read and understand millions of tables; computers require unsupervised learning to perform self-learning without labeled data, and can gain knowledge from existing tasks and previous experience; and computers desire few-shot learn-ing that can adjust to new tasks with a few examples. Our proposal is called Relational Pretrained Transformers (RPTs), a general frame-work for various data preparation tasks, which typically consists of the following models/methods: (1) transformer, a general and powerful deep-learning model, that can read tables/texts/images;(2) masked language model for self-learning and collaborative train-ing for transferring knowledge and experience; and (3) pattern-exploiting training that better interprets a task from a few examples.We further present concrete RPT architectures for three classical data preparation tasks, namely data cleaning, entity resolution, and information extraction. We demonstrate RPTs with some initial yet promising results. Last but not least, we identify activities that will unleash a series of research opportunities to push forward the field of data preparation.
Reuse and Adaptation for Entity Resolution through Transfer Learning
Sep 28, 2018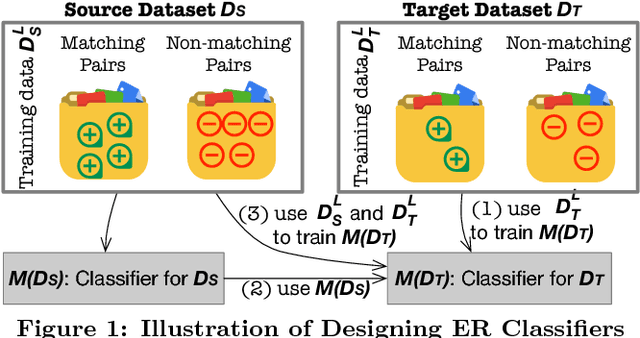
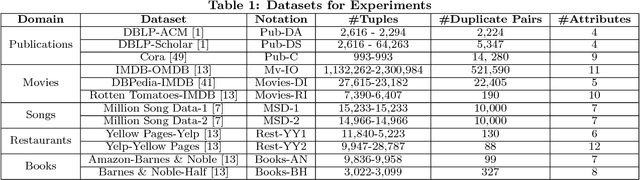
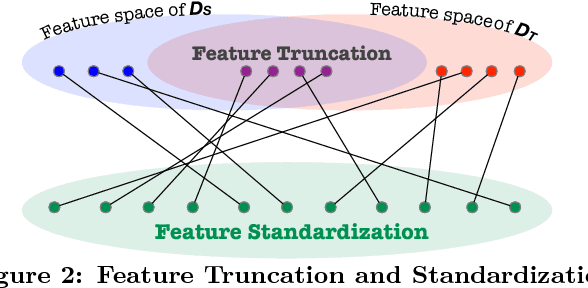

Entity resolution (ER) is one of the fundamental problems in data integration, where machine learning (ML) based classifiers often provide the state-of-the-art results. Considerable human effort goes into feature engineering and training data creation. In this paper, we investigate a new problem: Given a dataset D_T for ER with limited or no training data, is it possible to train a good ML classifier on D_T by reusing and adapting the training data of dataset D_S from same or related domain? Our major contributions include (1) a distributed representation based approach to encode each tuple from diverse datasets into a standard feature space; (2) identification of common scenarios where the reuse of training data can be beneficial; and (3) five algorithms for handling each of the aforementioned scenarios. We have performed comprehensive experiments on 12 datasets from 5 different domains (publications, movies, songs, restaurants, and books). Our experiments show that our algorithms provide significant benefits such as providing superior performance for a fixed training data size.
A large scale study of SVM based methods for abstract screening in systematic reviews
Jan 16, 2018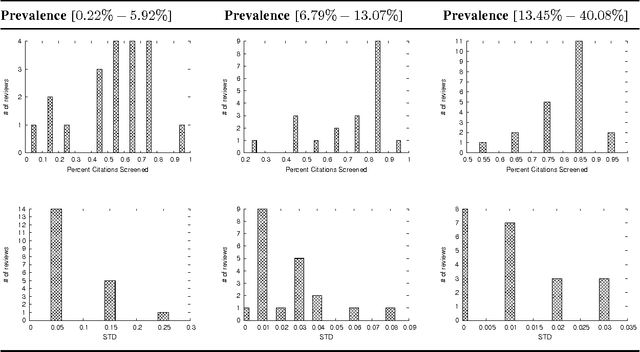
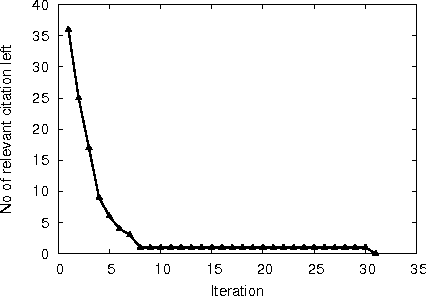


A major task in systematic reviews is abstract screening, i.e., excluding, often hundreds or thousand of, irrelevant citations returned from a database search based on titles and abstracts. Thus, a systematic review platform that can automate the abstract screening process is of huge importance. Several methods have been proposed for this task. However, it is very hard to clearly understand the applicability of these methods in a systematic review platform because of the following challenges: (1) the use of non-overlapping metrics for the evaluation of the proposed methods, (2) usage of features that are very hard to collect, (3) using a small set of reviews for the evaluation, and (4) no solid statistical testing or equivalence grouping of the methods. In this paper, we use feature representation that can be extracted per citation. We evaluate SVM-based methods (commonly used) on a large set of reviews ($61$) and metrics ($11$) to provide equivalence grouping of methods based on a solid statistical test. Our analysis also includes a strong variability of the metrics using $500$x$2$ cross validation. While some methods shine for different metrics and for different datasets, there is no single method that dominates the pack. Furthermore, we observe that in some cases relevant (included) citations can be found after screening only 15-20% of them via a certainty based sampling. A few included citations present outlying characteristics and can only be found after a very large number of screening steps. Finally, we present an ensemble algorithm for producing a $5$-star rating of citations based on their relevance. Such algorithm combines the best methods from our evaluation and through its $5$-star rating outputs a more easy-to-consume prediction.