 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOMNIA: Closing the Loop by Leveraging LLMs for Knowledge Graph Completion
Mar 12, 2026Knowledge Graphs (KGs) are widely used to represent structured knowledge, yet their automatic construction, especially with Large Language Models (LLMs), often results in incomplete or noisy outputs. Knowledge Graph Completion (KGC) aims to infer and add missing triples, but most existing methods either rely on structural embeddings that overlook semantics or language models that ignore the graph's structure and depend on external sources. In this work, we present OMNIA, a two-stage approach that bridges structural and semantic reasoning for KGC. It first generates candidate triples by clustering semantically related entities and relations within the KG, then validates them through lightweight embedding filtering followed by LLM-based semantic validation. OMNIA performs on the internal KG, without external sources, and specifically targets implicit semantics that are most frequent in LLM-generated graphs. Extensive experiments on multiple datasets demonstrate that OMNIA significantly improves F1-score compared to traditional embedding-based models. These results highlight OMNIA's effectiveness and efficiency, as its clustering and filtering stages reduce both search space and validation cost while maintaining high-quality completion.
Semantic-Guided RL for Interpretable Feature Engineering
Oct 03, 2024



The quality of Machine Learning (ML) models strongly depends on the input data, as such generating high-quality features is often required to improve the predictive accuracy. This process is referred to as Feature Engineering (FE). However, since manual feature engineering is time-consuming and requires case-by-case domain knowledge, Automated Feature Engineering (AutoFE) is crucial. A major challenge that remains is to generate interpretable features. To tackle this problem, we introduce SMART, a hybrid approach that uses semantic technologies to guide the generation of interpretable features through a two-step process: Exploitation and Exploration. The former uses Description Logics (DL) to reason on the semantics embedded in Knowledge Graphs (KG) to infer domain-specific features, while the latter exploits the knowledge graph to conduct a guided exploration of the search space through Deep Reinforcement Learning (DRL). Our experiments on public datasets demonstrate that SMART significantly improves prediction accuracy while ensuring a high level of interpretability.
Leveraging Knowlegde Graphs for Interpretable Feature Generation
Jun 01, 2024



The quality of Machine Learning (ML) models strongly depends on the input data, as such Feature Engineering (FE) is often required in ML. In addition, with the proliferation of ML-powered systems, especially in critical contexts, the need for interpretability and explainability becomes increasingly important. Since manual FE is time-consuming and requires case specific knowledge, we propose KRAFT, an AutoFE framework that leverages a knowledge graph to guide the generation of interpretable features. Our hybrid AI approach combines a neural generator to transform raw features through a series of transformations and a knowledge-based reasoner to evaluate features interpretability using Description Logics (DL). The generator is trained through Deep Reinforcement Learning (DRL) to maximize the prediction accuracy and the interpretability of the generated features. Extensive experiments on real datasets demonstrate that KRAFT significantly improves accuracy while ensuring a high level of interpretability.
Cleaning Inconsistent Data in Temporal DL-Lite Under Best Repair Semantics
Aug 30, 2021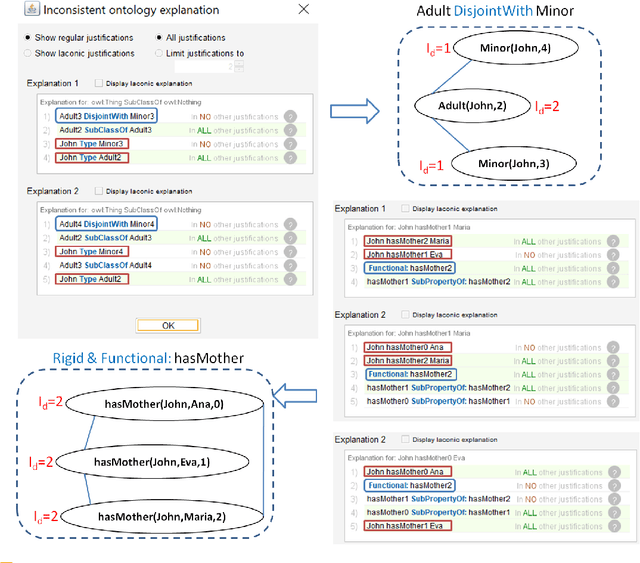
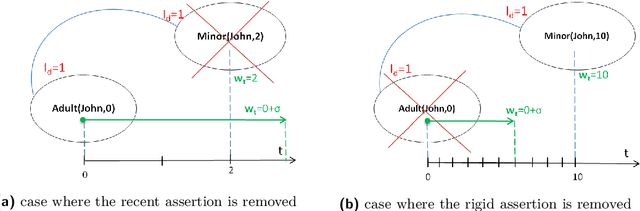
In this paper, we address the problem of handling inconsistent data in Temporal Description Logic (TDL) knowledge bases. Considering the data part of the Knowledge Base as the source of inconsistency over time, we propose an ABox repair approach. This is the first work handling the repair in TDL Knowledge bases. To do so, our goal is twofold: 1) detect temporal inconsistencies and 2) propose a data temporal reparation. For the inconsistency detection, we propose a reduction approach from TDL to DL which allows to provide a tight NP-complete upper bound for TDL concept satisfiability and to use highly optimised DL reasoners that can bring precise explanation (the set of inconsistent data assertions). Thereafter, from the obtained explanation, we propose a method for automatically computing the best repair in the temporal setting based on the allowed rigid predicates and the time order of assertions.
SentiQ: A Probabilistic Logic Approach to Enhance Sentiment Analysis Tool Quality
Aug 19, 2020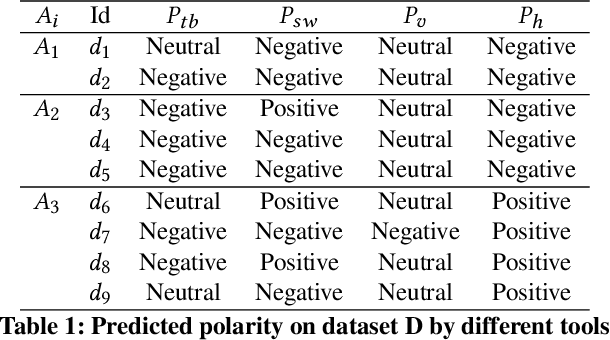
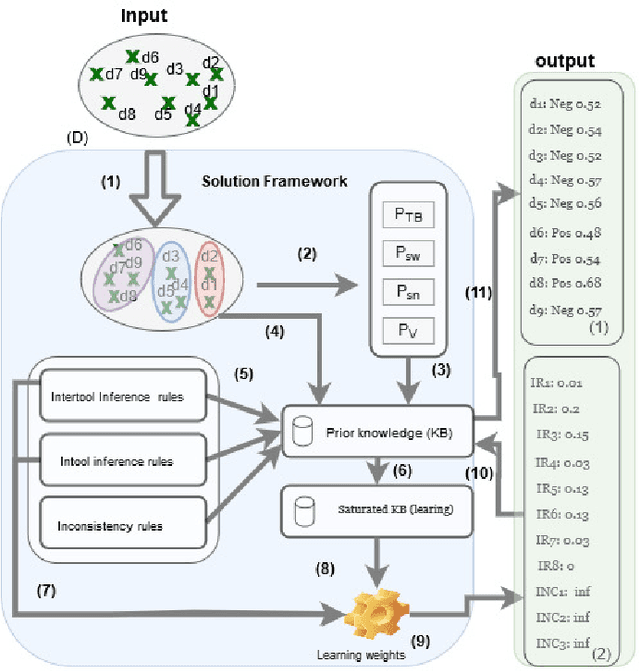
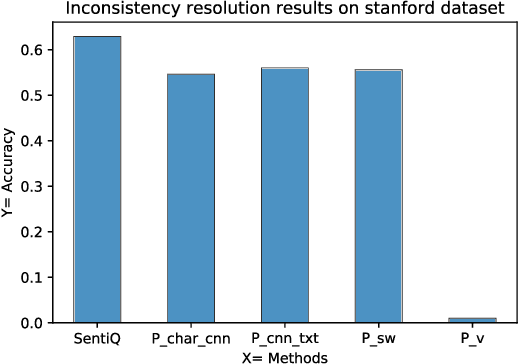

The opinion expressed in various Web sites and social-media is an essential contributor to the decision making process of several organizations. Existing sentiment analysis tools aim to extract the polarity (i.e., positive, negative, neutral) from these opinionated contents. Despite the advance of the research in the field, sentiment analysis tools give \textit{inconsistent} polarities, which is harmful to business decisions. In this paper, we propose SentiQ, an unsupervised Markov logic Network-based approach that injects the semantic dimension in the tools through rules. It allows to detect and solve inconsistencies and then improves the overall accuracy of the tools. Preliminary experimental results demonstrate the usefulness of SentiQ.