 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOMNIA: Closing the Loop by Leveraging LLMs for Knowledge Graph Completion
Mar 12, 2026Knowledge Graphs (KGs) are widely used to represent structured knowledge, yet their automatic construction, especially with Large Language Models (LLMs), often results in incomplete or noisy outputs. Knowledge Graph Completion (KGC) aims to infer and add missing triples, but most existing methods either rely on structural embeddings that overlook semantics or language models that ignore the graph's structure and depend on external sources. In this work, we present OMNIA, a two-stage approach that bridges structural and semantic reasoning for KGC. It first generates candidate triples by clustering semantically related entities and relations within the KG, then validates them through lightweight embedding filtering followed by LLM-based semantic validation. OMNIA performs on the internal KG, without external sources, and specifically targets implicit semantics that are most frequent in LLM-generated graphs. Extensive experiments on multiple datasets demonstrate that OMNIA significantly improves F1-score compared to traditional embedding-based models. These results highlight OMNIA's effectiveness and efficiency, as its clustering and filtering stages reduce both search space and validation cost while maintaining high-quality completion.
Research Trends for the Interplay between Large Language Models and Knowledge Graphs
Jun 12, 2024

This survey investigates the synergistic relationship between Large Language Models (LLMs) and Knowledge Graphs (KGs), which is crucial for advancing AI's capabilities in understanding, reasoning, and language processing. It aims to address gaps in current research by exploring areas such as KG Question Answering, ontology generation, KG validation, and the enhancement of KG accuracy and consistency through LLMs. The paper further examines the roles of LLMs in generating descriptive texts and natural language queries for KGs. Through a structured analysis that includes categorizing LLM-KG interactions, examining methodologies, and investigating collaborative uses and potential biases, this study seeks to provide new insights into the combined potential of LLMs and KGs. It highlights the importance of their interaction for improving AI applications and outlines future research directions.
Multilingual Irony Detection with Dependency Syntax and Neural Models
Nov 11, 2020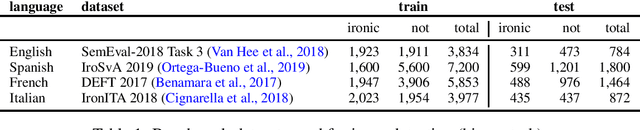
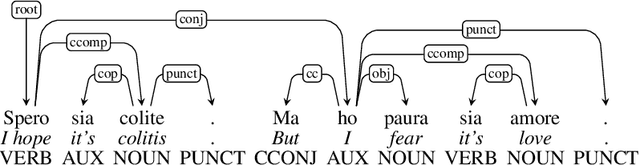

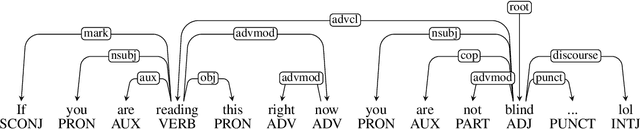
This paper presents an in-depth investigation of the effectiveness of dependency-based syntactic features on the irony detection task in a multilingual perspective (English, Spanish, French and Italian). It focuses on the contribution from syntactic knowledge, exploiting linguistic resources where syntax is annotated according to the Universal Dependencies scheme. Three distinct experimental settings are provided. In the first, a variety of syntactic dependency-based features combined with classical machine learning classifiers are explored. In the second scenario, two well-known types of word embeddings are trained on parsed data and tested against gold standard datasets. In the third setting, dependency-based syntactic features are combined into the Multilingual BERT architecture. The results suggest that fine-grained dependency-based syntactic information is informative for the detection of irony.
Irony Detection in a Multilingual Context
Feb 06, 2020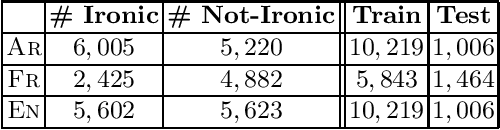

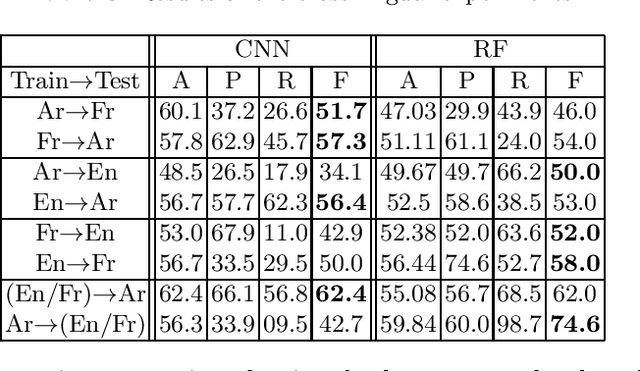
This paper proposes the first multilingual (French, English and Arabic) and multicultural (Indo-European languages vs. less culturally close languages) irony detection system. We employ both feature-based models and neural architectures using monolingual word representation. We compare the performance of these systems with state-of-the-art systems to identify their capabilities. We show that these monolingual models trained separately on different languages using multilingual word representation or text-based features can open the door to irony detection in languages that lack of annotated data for irony.