 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFanar 2.0: Arabic Generative AI Stack
Mar 17, 2026We present Fanar 2.0, the second generation of Qatar's Arabic-centric Generative AI platform. Sovereignty is a first-class design principle: every component, from data pipelines to deployment infrastructure, was designed and operated entirely at QCRI, Hamad Bin Khalifa University. Fanar 2.0 is a story of resource-constrained excellence: the effort ran on 256 NVIDIA H100 GPUs, with Arabic having only ~0.5% of web data despite 400 million native speakers. Fanar 2.0 adopts a disciplined strategy of data quality over quantity, targeted continual pre-training, and model merging to achieve substantial gains within these constraints. At the core is Fanar-27B, continually pre-trained from a Gemma-3-27B backbone on a curated corpus of 120 billion high-quality tokens across three data recipes. Despite using 8x fewer pre-training tokens than Fanar 1.0, it delivers substantial benchmark improvements: Arabic knowledge (+9.1 pts), language (+7.3 pts), dialects (+3.5 pts), and English capability (+7.6 pts). Beyond the core LLM, Fanar 2.0 introduces a rich stack of new capabilities. FanarGuard is a state-of-the-art 4B bilingual moderation filter for Arabic safety and cultural alignment. The speech family Aura gains a long-form ASR model for hours-long audio. Oryx vision family adds Arabic-aware image and video understanding alongside culturally grounded image generation. An agentic tool-calling framework enables multi-step workflows. Fanar-Sadiq utilizes a multi-agent architecture for Islamic content. Fanar-Diwan provides classical Arabic poetry generation. FanarShaheen delivers LLM-powered bilingual translation. A redesigned multi-layer orchestrator coordinates all components through intent-aware routing and defense-in-depth safety validation. Taken together, Fanar 2.0 demonstrates that sovereign, resource-constrained AI development can produce systems competitive with those built at far greater scale.
Fanar-Sadiq: A Multi-Agent Architecture for Grounded Islamic QA
Mar 10, 2026Large language models (LLMs) can answer religious knowledge queries fluently, yet they often hallucinate and misattribute sources, which is especially consequential in Islamic settings where users expect grounding in canonical texts (Qur'an and Hadith) and jurisprudential (fiqh) nuance. Retrieval-augmented generation (RAG) reduces some of these limitations by grounding generation in external evidence. However, a single ``retrieve-then-generate'' pipeline is limited to deal with the diversity of Islamic queries. Users may request verbatim scripture, fatwa-style guidance with citations or rule-constrained computations such as zakat and inheritance that require strict arithmetic and legal invariants. In this work, we present a bilingual (Arabic/English) multi-agent Islamic assistant, called Fanar-Sadiq, which is a core component of the Fanar AI platform. Fanar-Sadiq routes Islamic-related queries to specialized modules within an agentic, tool-using architecture. The system supports intent-aware routing, retrieval-grounded fiqh answers with deterministic citation normalization and verification traces, exact verse lookup with quotation validation, and deterministic calculators for Sunni zakat and inheritance with madhhab-sensitive branching. We evaluate the complete end-to-end system on public Islamic QA benchmarks and demonstrate effectiveness and efficiency. Our system is currently publicly and freely accessible through API and a Web application, and has been accessed $\approx$1.9M times in less than a year.
More Data, Fewer Diacritics: Scaling Arabic TTS
Mar 02, 2026Arabic Text-to-Speech (TTS) research has been hindered by the availability of both publicly available training data and accurate Arabic diacritization models. In this paper, we address the limitation by exploring Arabic TTS training on large automatically annotated data. Namely, we built a robust pipeline for collecting Arabic recordings and processing them automatically using voice activity detection, speech recognition, automatic diacritization, and noise filtering, resulting in around 4,000 hours of Arabic TTS training data. We then trained several robust TTS models with voice cloning using varying amounts of data, namely 100, 1,000, and 4,000 hours with and without diacritization. We show that though models trained on diacritized data are generally better, larger amounts of training data compensate for the lack of diacritics to a significant degree. We plan to release a public Arabic TTS model that works without the need for diacritization.
From RAG to Agentic RAG for Faithful Islamic Question Answering
Jan 12, 2026LLMs are increasingly used for Islamic question answering, where ungrounded responses may carry serious religious consequences. Yet standard MCQ/MRC-style evaluations do not capture key real-world failure modes, notably free-form hallucinations and whether models appropriately abstain when evidence is lacking. To shed a light on this aspect we introduce ISLAMICFAITHQA, a 3,810-item bilingual (Arabic/English) generative benchmark with atomic single-gold answers, which enables direct measurement of hallucination and abstention. We additionally developed an end-to-end grounded Islamic modelling suite consisting of (i) 25K Arabic text-grounded SFT reasoning pairs, (ii) 5K bilingual preference samples for reward-guided alignment, and (iii) a verse-level Qur'an retrieval corpus of $\sim$6k atomic verses (ayat). Building on these resources, we develop an agentic Quran-grounding framework (agentic RAG) that uses structured tool calls for iterative evidence seeking and answer revision. Experiments across Arabic-centric and multilingual LLMs show that retrieval improves correctness and that agentic RAG yields the largest gains beyond standard RAG, achieving state-of-the-art performance and stronger Arabic-English robustness even with a small model (i.e., Qwen3 4B). We will make the experimental resources and datasets publicly available for the community.
BALSAM: A Platform for Benchmarking Arabic Large Language Models
Jul 30, 2025



The impressive advancement of Large Language Models (LLMs) in English has not been matched across all languages. In particular, LLM performance in Arabic lags behind, due to data scarcity, linguistic diversity of Arabic and its dialects, morphological complexity, etc. Progress is further hindered by the quality of Arabic benchmarks, which typically rely on static, publicly available data, lack comprehensive task coverage, or do not provide dedicated platforms with blind test sets. This makes it challenging to measure actual progress and to mitigate data contamination. Here, we aim to bridge these gaps. In particular, we introduce BALSAM, a comprehensive, community-driven benchmark aimed at advancing Arabic LLM development and evaluation. It includes 78 NLP tasks from 14 broad categories, with 52K examples divided into 37K test and 15K development, and a centralized, transparent platform for blind evaluation. We envision BALSAM as a unifying platform that sets standards and promotes collaborative research to advance Arabic LLM capabilities.
Creating Arabic LLM Prompts at Scale
Aug 12, 2024
The debut of chatGPT and BARD has popularized instruction following text generation using LLMs, where a user can interrogate an LLM using natural language requests and obtain natural language answers that matches their requests. Training LLMs to respond in this manner requires a large number of worked out examples of user requests (aka prompts) with corresponding gold responses. In this paper, we introduce two methods for creating such prompts for Arabic cheaply and quickly. The first methods entails automatically translating existing prompt datasets from English, such as PromptSource and Super-NaturalInstructions, and then using machine translation quality estimation to retain high quality translations only. The second method involves creating natural language prompts on top of existing Arabic NLP datasets. Using these two methods we were able to create more than 67.4 million Arabic prompts that cover a variety of tasks including summarization, headline generation, grammar checking, open/closed question answering, creative writing, etc. We show that fine tuning an open 7 billion parameter large language model, namely base Qwen2 7B, enables it to outperform a state-of-the-art 70 billion parameter instruction tuned model, namely Llama3 70B, in handling Arabic prompts.
An Automated End-to-End Open-Source Software for High-Quality Text-to-Speech Dataset Generation
Feb 26, 2024



Data availability is crucial for advancing artificial intelligence applications, including voice-based technologies. As content creation, particularly in social media, experiences increasing demand, translation and text-to-speech (TTS) technologies have become essential tools. Notably, the performance of these TTS technologies is highly dependent on the quality of the training data, emphasizing the mutual dependence of data availability and technological progress. This paper introduces an end-to-end tool to generate high-quality datasets for text-to-speech (TTS) models to address this critical need for high-quality data. The contributions of this work are manifold and include: the integration of language-specific phoneme distribution into sample selection, automation of the recording process, automated and human-in-the-loop quality assurance of recordings, and processing of recordings to meet specified formats. The proposed application aims to streamline the dataset creation process for TTS models through these features, thereby facilitating advancements in voice-based technologies.
NatiQ: An End-to-end Text-to-Speech System for Arabic
Jun 15, 2022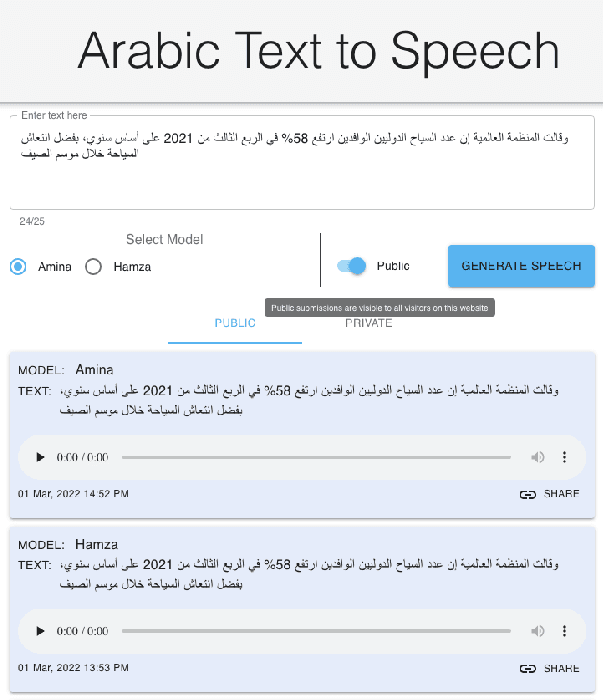
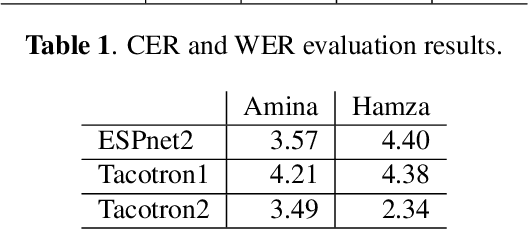
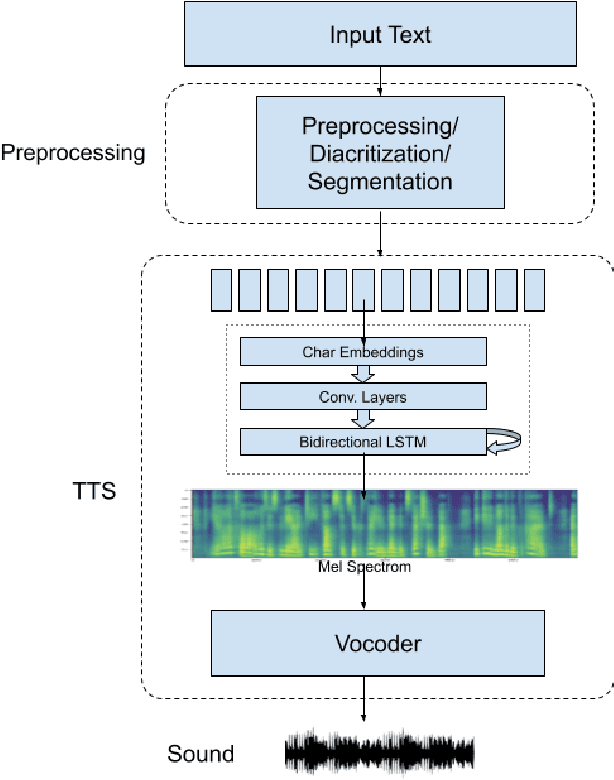
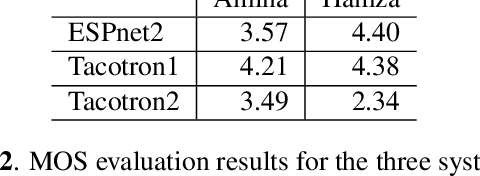
NatiQ is end-to-end text-to-speech system for Arabic. Our speech synthesizer uses an encoder-decoder architecture with attention. We used both tacotron-based models (tacotron-1 and tacotron-2) and the faster transformer model for generating mel-spectrograms from characters. We concatenated Tacotron1 with the WaveRNN vocoder, Tacotron2 with the WaveGlow vocoder and ESPnet transformer with the parallel wavegan vocoder to synthesize waveforms from the spectrograms. We used in-house speech data for two voices: 1) neutral male "Hamza"- narrating general content and news, and 2) expressive female "Amina"- narrating children story books to train our models. Our best systems achieve an average Mean Opinion Score (MOS) of 4.21 and 4.40 for Amina and Hamza respectively. The objective evaluation of the systems using word and character error rate (WER and CER) as well as the response time measured by real-time factor favored the end-to-end architecture ESPnet. NatiQ demo is available on-line at https://tts.qcri.org
Automatic Expansion and Retargeting of Arabic Offensive Language Training
Nov 18, 2021
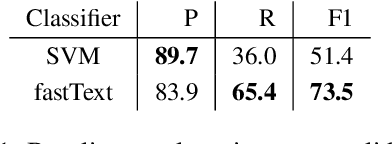
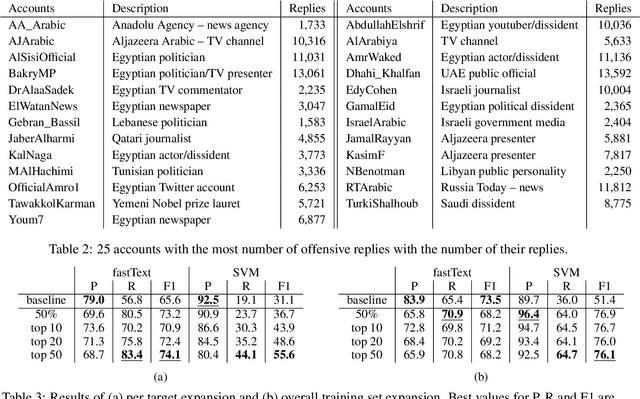
Rampant use of offensive language on social media led to recent efforts on automatic identification of such language. Though offensive language has general characteristics, attacks on specific entities may exhibit distinct phenomena such as malicious alterations in the spelling of names. In this paper, we present a method for identifying entity specific offensive language. We employ two key insights, namely that replies on Twitter often imply opposition and some accounts are persistent in their offensiveness towards specific targets. Using our methodology, we are able to collect thousands of targeted offensive tweets. We show the efficacy of the approach on Arabic tweets with 13% and 79% relative F1-measure improvement in entity specific offensive language detection when using deep-learning based and support vector machine based classifiers respectively. Further, expanding the training set with automatically identified offensive tweets directed at multiple entities can improve F1-measure by 48%.
Cross-lingual Emotion Detection
Jun 10, 2021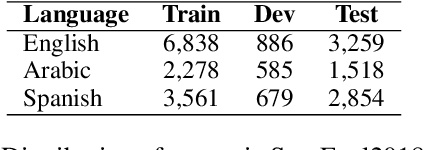

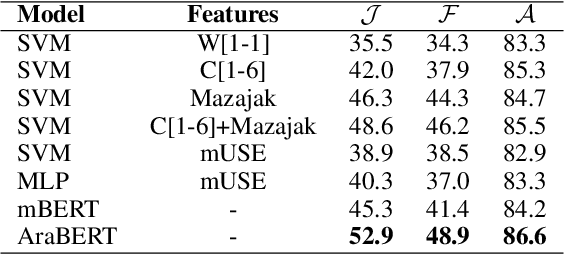
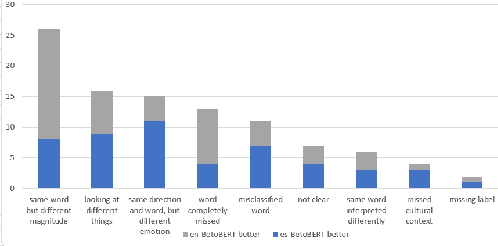
Emotion detection is of great importance for understanding humans. Constructing annotated datasets to train automated models can be expensive. We explore the efficacy of cross-lingual approaches that would use data from a source language to build models for emotion detection in a target language. We compare three approaches, namely: i) using inherently multilingual models; ii) translating training data into the target language; and iii) using an automatically tagged parallel corpus. In our study, we consider English as the source language with Arabic and Spanish as target languages. We study the effectiveness of different classification models such as BERT and SVMs trained with different features. Our BERT-based monolingual models that are trained on target language data surpass state-of-the-art (SOTA) by 4% and 5% absolute Jaccard score for Arabic and Spanish respectively. Next, we show that using cross-lingual approaches with English data alone, we can achieve more than 90% and 80% relative effectiveness of the Arabic and Spanish BERT models respectively. Lastly, we use LIME to interpret the differences between models.