 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnd-to-End Spatio-Temporal Action Localisation with Video Transformers
Apr 24, 2023



The most performant spatio-temporal action localisation models use external person proposals and complex external memory banks. We propose a fully end-to-end, purely-transformer based model that directly ingests an input video, and outputs tubelets -- a sequence of bounding boxes and the action classes at each frame. Our flexible model can be trained with either sparse bounding-box supervision on individual frames, or full tubelet annotations. And in both cases, it predicts coherent tubelets as the output. Moreover, our end-to-end model requires no additional pre-processing in the form of proposals, or post-processing in terms of non-maximal suppression. We perform extensive ablation experiments, and significantly advance the state-of-the-art results on four different spatio-temporal action localisation benchmarks with both sparse keyframes and full tubelet annotations.
Scaling Vision Transformers to 22 Billion Parameters
Feb 10, 2023



The scaling of Transformers has driven breakthrough capabilities for language models. At present, the largest large language models (LLMs) contain upwards of 100B parameters. Vision Transformers (ViT) have introduced the same architecture to image and video modelling, but these have not yet been successfully scaled to nearly the same degree; the largest dense ViT contains 4B parameters (Chen et al., 2022). We present a recipe for highly efficient and stable training of a 22B-parameter ViT (ViT-22B) and perform a wide variety of experiments on the resulting model. When evaluated on downstream tasks (often with a lightweight linear model on frozen features), ViT-22B demonstrates increasing performance with scale. We further observe other interesting benefits of scale, including an improved tradeoff between fairness and performance, state-of-the-art alignment to human visual perception in terms of shape/texture bias, and improved robustness. ViT-22B demonstrates the potential for "LLM-like" scaling in vision, and provides key steps towards getting there.
Dual PatchNorm
Feb 06, 2023



We propose Dual PatchNorm: two Layer Normalization layers (LayerNorms), before and after the patch embedding layer in Vision Transformers. We demonstrate that Dual PatchNorm outperforms the result of exhaustive search for alternative LayerNorm placement strategies in the Transformer block itself. In our experiments, incorporating this trivial modification, often leads to improved accuracy over well-tuned Vision Transformers and never hurts.
Adaptive Computation with Elastic Input Sequence
Jan 30, 2023When solving a problem, human beings have the adaptive ability in terms of the type of information they use, the procedure they take, and the amount of time they spend approaching and solving the problem. However, most standard neural networks have the same function type and fixed computation budget on different samples regardless of their nature and difficulty. Adaptivity is a powerful paradigm as it not only imbues practitioners with flexibility pertaining to the downstream usage of these models but can also serve as a powerful inductive bias for solving certain challenging classes of problems. In this work, we propose a new strategy, AdaTape, that enables dynamic computation in neural networks via adaptive tape tokens. AdaTape employs an elastic input sequence by equipping an existing architecture with a dynamic read-and-write tape. Specifically, we adaptively generate input sequences using tape tokens obtained from a tape bank that can either be trainable or generated from input data. We analyze the challenges and requirements to obtain dynamic sequence content and length, and propose the Adaptive Tape Reader (ATR) algorithm to achieve both objectives. Via extensive experiments on image recognition tasks, we show that AdaTape can achieve better performance while maintaining the computational cost.
DSI++: Updating Transformer Memory with New Documents
Dec 19, 2022



Differentiable Search Indices (DSIs) encode a corpus of documents in the parameters of a model and use the same model to map queries directly to relevant document identifiers. Despite the strong performance of DSI models, deploying them in situations where the corpus changes over time is computationally expensive because reindexing the corpus requires re-training the model. In this work, we introduce DSI++, a continual learning challenge for DSI to incrementally index new documents while being able to answer queries related to both previously and newly indexed documents. Across different model scales and document identifier representations, we show that continual indexing of new documents leads to considerable forgetting of previously indexed documents. We also hypothesize and verify that the model experiences forgetting events during training, leading to unstable learning. To mitigate these issues, we investigate two approaches. The first focuses on modifying the training dynamics. Flatter minima implicitly alleviate forgetting, so we optimize for flatter loss basins and show that the model stably memorizes more documents (+12\%). Next, we introduce a generative memory to sample pseudo-queries for documents and supplement them during continual indexing to prevent forgetting for the retrieval task. Extensive experiments on novel continual indexing benchmarks based on Natural Questions (NQ) and MS MARCO demonstrate that our proposed solution mitigates forgetting by a significant margin. Concretely, it improves the average Hits@10 by $+21.1\%$ over competitive baselines for NQ and requires $6$ times fewer model updates compared to re-training the DSI model for incrementally indexing five corpora in a sequence.
Sparse Upcycling: Training Mixture-of-Experts from Dense Checkpoints
Dec 09, 2022



Training large, deep neural networks to convergence can be prohibitively expensive. As a result, often only a small selection of popular, dense models are reused across different contexts and tasks. Increasingly, sparsely activated models, which seek to decouple model size from computation costs, are becoming an attractive alternative to dense models. Although more efficient in terms of quality and computation cost, sparse models remain data-hungry and costly to train from scratch in the large scale regime. In this work, we propose sparse upcycling -- a simple way to reuse sunk training costs by initializing a sparsely activated Mixture-of-Experts model from a dense checkpoint. We show that sparsely upcycled T5 Base, Large, and XL language models and Vision Transformer Base and Large models, respectively, significantly outperform their dense counterparts on SuperGLUE and ImageNet, using only ~50% of the initial dense pretraining sunk cost. The upcycled models also outperform sparse models trained from scratch on 100% of the initial dense pretraining computation budget.
Automated Deep Aberration Detection from Chromosome Karyotype Images
Nov 30, 2022Chromosome analysis is essential for diagnosing genetic disorders. For hematologic malignancies, identification of somatic clonal aberrations by karyotype analysis remains the standard of care. However, karyotyping is costly and time-consuming because of the largely manual process and the expertise required in identifying and annotating aberrations. Efforts to automate karyotype analysis to date fell short in aberration detection. Using a training set of ~10k patient specimens and ~50k karyograms from over 5 years from the Fred Hutchinson Cancer Center, we created a labeled set of images representing individual chromosomes. These individual chromosomes were used to train and assess deep learning models for classifying the 24 human chromosomes and identifying chromosomal aberrations. The top-accuracy models utilized the recently introduced Topological Vision Transformers (TopViTs) with 2-level-block-Toeplitz masking, to incorporate structural inductive bias. TopViT outperformed CNN (Inception) models with >99.3% accuracy for chromosome identification, and exhibited accuracies >99% for aberration detection in most aberrations. Notably, we were able to show high-quality performance even in "few shot" learning scenarios. Incorporating the definition of clonality substantially improved both precision and recall (sensitivity). When applied to "zero shot" scenarios, the model captured aberrations without training, with perfect precision at >50% recall. Together these results show that modern deep learning models can approach expert-level performance for chromosome aberration detection. To our knowledge, this is the first study demonstrating the downstream effectiveness of TopViTs. These results open up exciting opportunities for not only expediting patient results but providing a scalable technology for early screening of low-abundance chromosomal lesions.
Scaling Instruction-Finetuned Language Models
Oct 20, 2022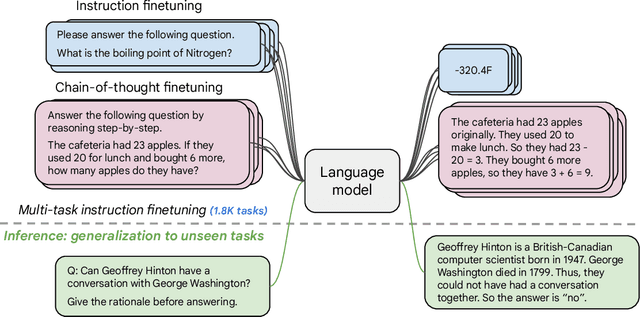

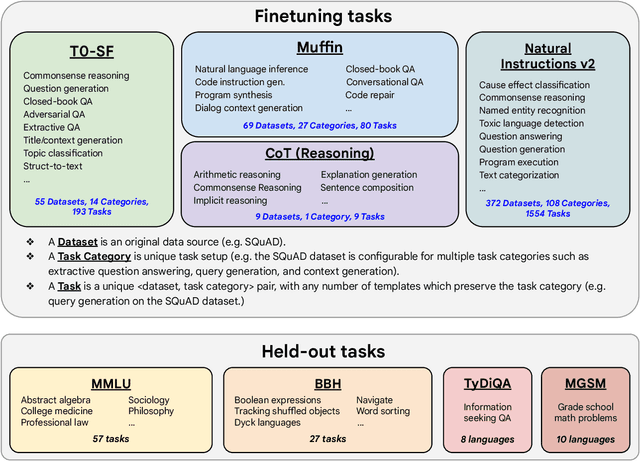

Finetuning language models on a collection of datasets phrased as instructions has been shown to improve model performance and generalization to unseen tasks. In this paper we explore instruction finetuning with a particular focus on (1) scaling the number of tasks, (2) scaling the model size, and (3) finetuning on chain-of-thought data. We find that instruction finetuning with the above aspects dramatically improves performance on a variety of model classes (PaLM, T5, U-PaLM), prompting setups (zero-shot, few-shot, CoT), and evaluation benchmarks (MMLU, BBH, TyDiQA, MGSM, open-ended generation). For instance, Flan-PaLM 540B instruction-finetuned on 1.8K tasks outperforms PALM 540B by a large margin (+9.4% on average). Flan-PaLM 540B achieves state-of-the-art performance on several benchmarks, such as 75.2% on five-shot MMLU. We also publicly release Flan-T5 checkpoints, which achieve strong few-shot performance even compared to much larger models, such as PaLM 62B. Overall, instruction finetuning is a general method for improving the performance and usability of pretrained language models.
Transcending Scaling Laws with 0.1% Extra Compute
Oct 20, 2022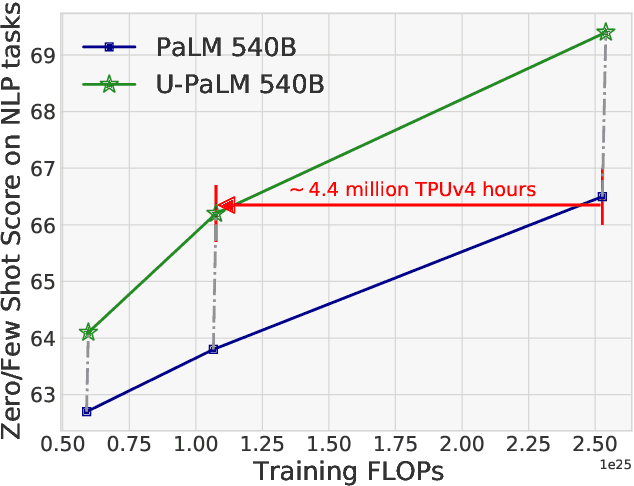
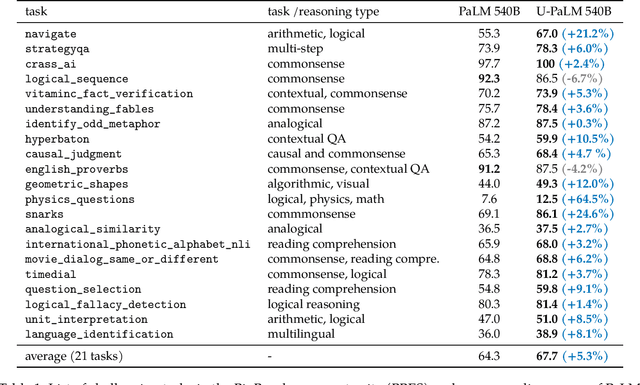
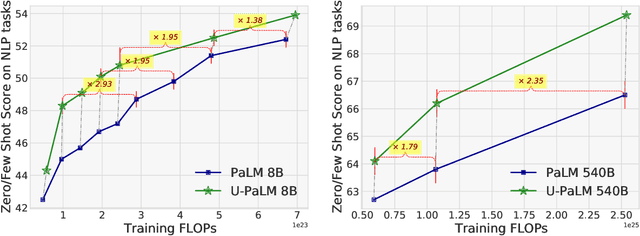
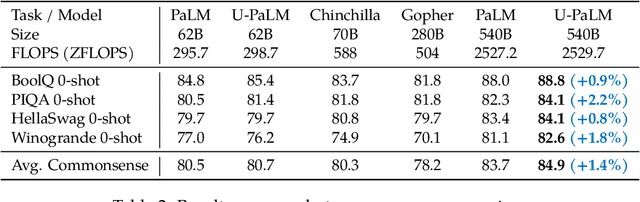
Scaling language models improves performance but comes with significant computational costs. This paper proposes UL2R, a method that substantially improves existing language models and their scaling curves with a relatively tiny amount of extra compute. The key idea is to continue training a state-of-the-art large language model (e.g., PaLM) on a few more steps with UL2's mixture-of-denoiser objective. We show that, with almost negligible extra computational costs and no new sources of data, we are able to substantially improve the scaling properties of large language models on downstream metrics. In this paper, we continue training PaLM with UL2R, introducing a new set of models at 8B, 62B, and 540B scale which we call U-PaLM. Impressively, at 540B scale, we show an approximately 2x computational savings rate where U-PaLM achieves the same performance as the final PaLM 540B model at around half its computational budget (i.e., saving $\sim$4.4 million TPUv4 hours). We further show that this improved scaling curve leads to 'emergent abilities' on challenging BIG-Bench tasks -- for instance, U-PaLM does much better than PaLM on some tasks or demonstrates better quality at much smaller scale (62B as opposed to 540B). Overall, we show that U-PaLM outperforms PaLM on many few-shot setups, i.e., English NLP tasks (e.g., commonsense reasoning, question answering), reasoning tasks with chain-of-thought (e.g., GSM8K), multilingual tasks (MGSM, TydiQA), MMLU and challenging BIG-Bench tasks. Finally, we provide qualitative examples showing the new capabilities of U-PaLM for single and multi-span infilling.
$Λ$-DARTS: Mitigating Performance Collapse by Harmonizing Operation Selection among Cells
Oct 14, 2022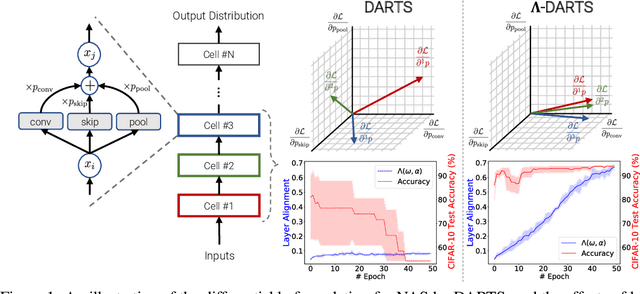
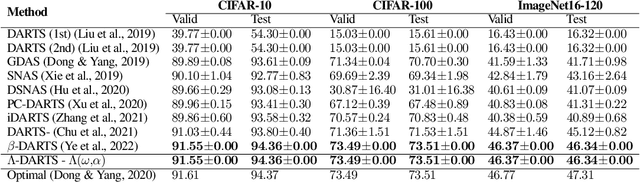
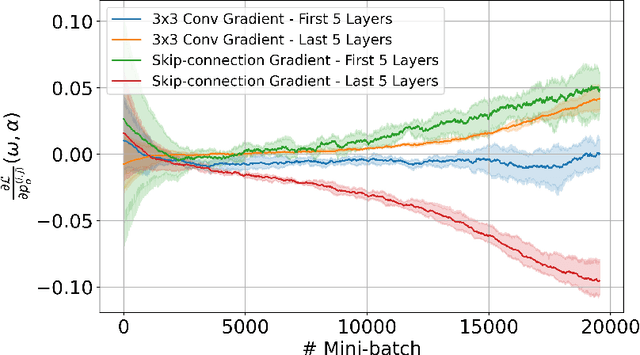
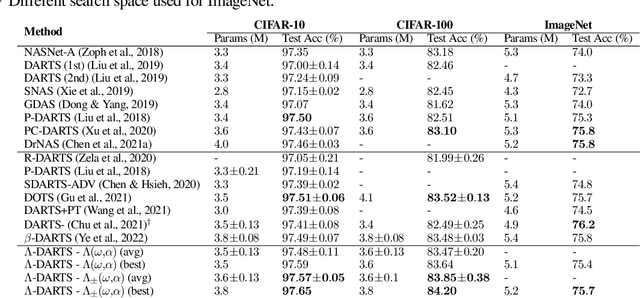
Differentiable neural architecture search (DARTS) is a popular method for neural architecture search (NAS), which performs cell-search and utilizes continuous relaxation to improve the search efficiency via gradient-based optimization. The main shortcoming of DARTS is performance collapse, where the discovered architecture suffers from a pattern of declining quality during search. Performance collapse has become an important topic of research, with many methods trying to solve the issue through either regularization or fundamental changes to DARTS. However, the weight-sharing framework used for cell-search in DARTS and the convergence of architecture parameters has not been analyzed yet. In this paper, we provide a thorough and novel theoretical and empirical analysis on DARTS and its point of convergence. We show that DARTS suffers from a specific structural flaw due to its weight-sharing framework that limits the convergence of DARTS to saturation points of the softmax function. This point of convergence gives an unfair advantage to layers closer to the output in choosing the optimal architecture, causing performance collapse. We then propose two new regularization terms that aim to prevent performance collapse by harmonizing operation selection via aligning gradients of layers. Experimental results on six different search spaces and three different datasets show that our method ($\Lambda$-DARTS) does indeed prevent performance collapse, providing justification for our theoretical analysis and the proposed remedy.