 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFixed-Point RNNs: From Diagonal to Dense in a Few Iterations
Mar 13, 2025



Linear recurrent neural networks (RNNs) and state-space models (SSMs) such as Mamba have become promising alternatives to softmax-attention as sequence mixing layers in Transformer architectures. Current models, however, do not exhibit the full state-tracking expressivity of RNNs because they rely on channel-wise (i.e. diagonal) sequence mixing. In this paper, we propose to compute a dense linear RNN as the fixed-point of a parallelizable diagonal linear RNN in a single layer. We explore mechanisms to improve its memory and state-tracking abilities in practice, and achieve state-of-the-art results on the commonly used toy tasks $A_5$, $S_5$, copying, and modular arithmetics. We hope our results will open new avenues to more expressive and efficient sequence mixers.
QEQR: An Exploration of Query Expansion Methods for Question Retrieval in CQA Services
Nov 23, 2024CQA services are valuable sources of knowledge that can be used to find answers to users' information needs. In these services, question retrieval aims to help users with their information needs by finding similar questions to theirs. However, finding similar questions is obstructed by the lexical gap that exists between relevant questions. In this work, we target this problem by using query expansion methods. We use word-similarity-based methods, propose a question-similarity-based method and selective expansion of these methods to expand a question that's been submitted and mitigate the lexical gap problem. Our best method achieves a significant relative improvement of 1.8\% compared to the best-performing baseline without query expansion.
Geometric Inductive Biases of Deep Networks: The Role of Data and Architecture
Oct 15, 2024In this paper, we propose the $\textit{geometric invariance hypothesis (GIH)}$, which argues that when training a neural network, the input space curvature remains invariant under transformation in certain directions determined by its architecture. Starting with a simple non-linear binary classification problem residing on a plane in a high dimensional space, we observe that while an MLP can solve this problem regardless of the orientation of the plane, this is not the case for a ResNet. Motivated by this example, we define two maps that provide a compact $\textit{architecture-dependent}$ summary of the input space geometry of a neural network and its evolution during training, which we dub the $\textbf{average geometry}$ and $\textbf{average geometry evolution}$, respectively. By investigating average geometry evolution at initialization, we discover that the geometry of a neural network evolves according to the projection of data covariance onto average geometry. As a result, in cases where the average geometry is low-rank (such as in a ResNet), the geometry only changes in a subset of the input space. This causes an architecture-dependent invariance property in input-space curvature, which we dub GIH. Finally, we present extensive experimental results to observe the consequences of GIH and how it relates to generalization in neural networks.
Generative Adversarial Training Can Improve Neural Language Models
Nov 02, 2022
While deep learning in the form of recurrent neural networks (RNNs) has caused a significant improvement in neural language modeling, the fact that they are extremely prone to overfitting is still a mainly unresolved issue. In this paper we propose a regularization method based on generative adversarial networks (GANs) and adversarial training (AT), that can prevent overfitting in neural language models. Unlike common adversarial training methods such as the fast gradient sign method (FGSM) that require a second back-propagation through time, and therefore effectively require at least twice the amount of time for regular training, the overhead of our method does not exceed more than 20% of the training of the baselines.
$Λ$-DARTS: Mitigating Performance Collapse by Harmonizing Operation Selection among Cells
Oct 14, 2022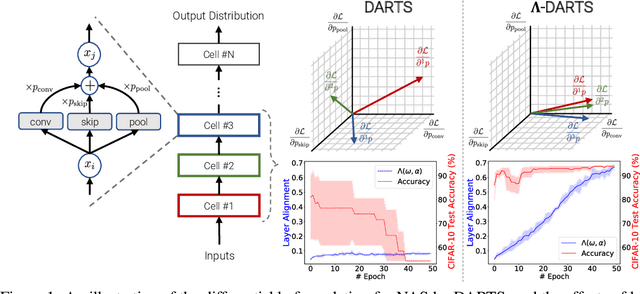
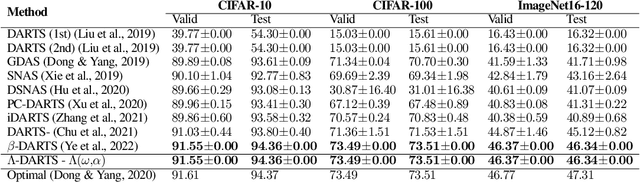
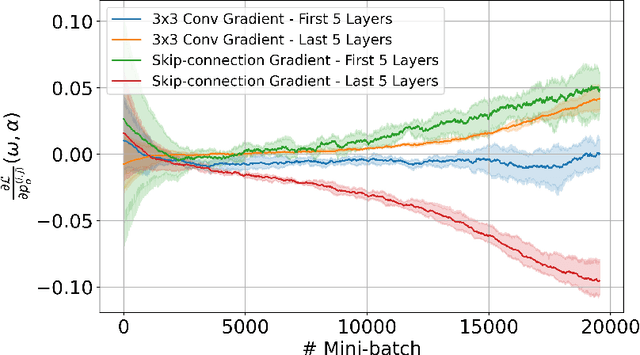
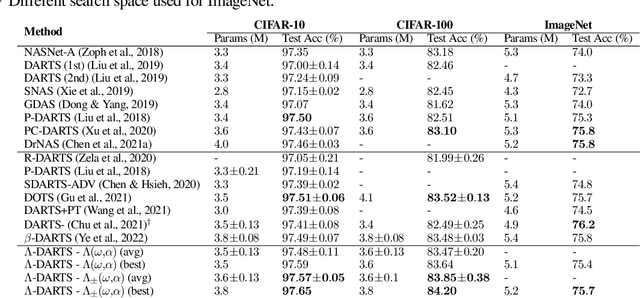
Differentiable neural architecture search (DARTS) is a popular method for neural architecture search (NAS), which performs cell-search and utilizes continuous relaxation to improve the search efficiency via gradient-based optimization. The main shortcoming of DARTS is performance collapse, where the discovered architecture suffers from a pattern of declining quality during search. Performance collapse has become an important topic of research, with many methods trying to solve the issue through either regularization or fundamental changes to DARTS. However, the weight-sharing framework used for cell-search in DARTS and the convergence of architecture parameters has not been analyzed yet. In this paper, we provide a thorough and novel theoretical and empirical analysis on DARTS and its point of convergence. We show that DARTS suffers from a specific structural flaw due to its weight-sharing framework that limits the convergence of DARTS to saturation points of the softmax function. This point of convergence gives an unfair advantage to layers closer to the output in choosing the optimal architecture, causing performance collapse. We then propose two new regularization terms that aim to prevent performance collapse by harmonizing operation selection via aligning gradients of layers. Experimental results on six different search spaces and three different datasets show that our method ($\Lambda$-DARTS) does indeed prevent performance collapse, providing justification for our theoretical analysis and the proposed remedy.
NLP-IIS@UT at SemEval-2021 Task 4: Machine Reading Comprehension using the Long Document Transformer
May 08, 2021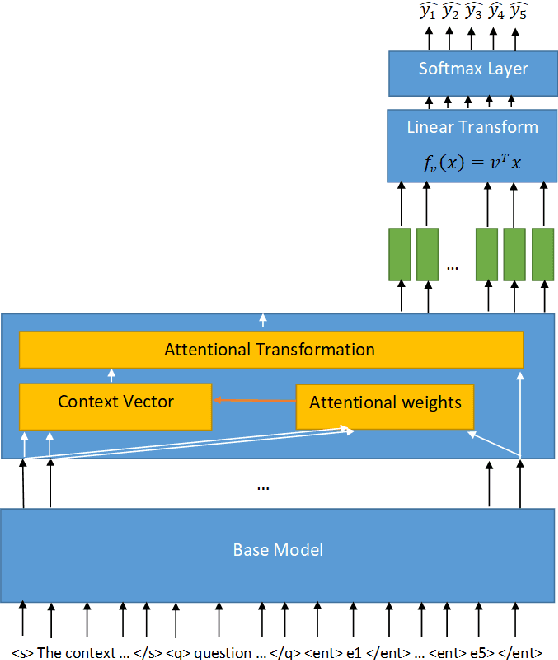
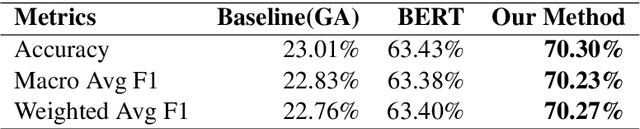
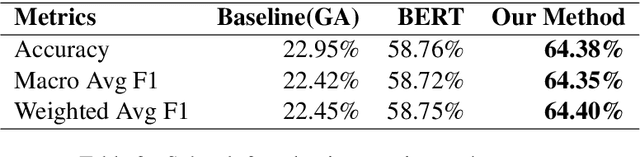
This paper presents a technical report of our submission to the 4th task of SemEval-2021, titled: Reading Comprehension of Abstract Meaning. In this task, we want to predict the correct answer based on a question given a context. Usually, contexts are very lengthy and require a large receptive field from the model. Thus, common contextualized language models like BERT miss fine representation and performance due to the limited capacity of the input tokens. To tackle this problem, we used the Longformer model to better process the sequences. Furthermore, we utilized the method proposed in the Longformer benchmark on Wikihop dataset which improved the accuracy on our task data from 23.01% and 22.95% achieved by the baselines for subtask 1 and 2, respectively, to 70.30% and 64.38%.
Aspect Category Detection via Topic-Attention Network
Jan 04, 2019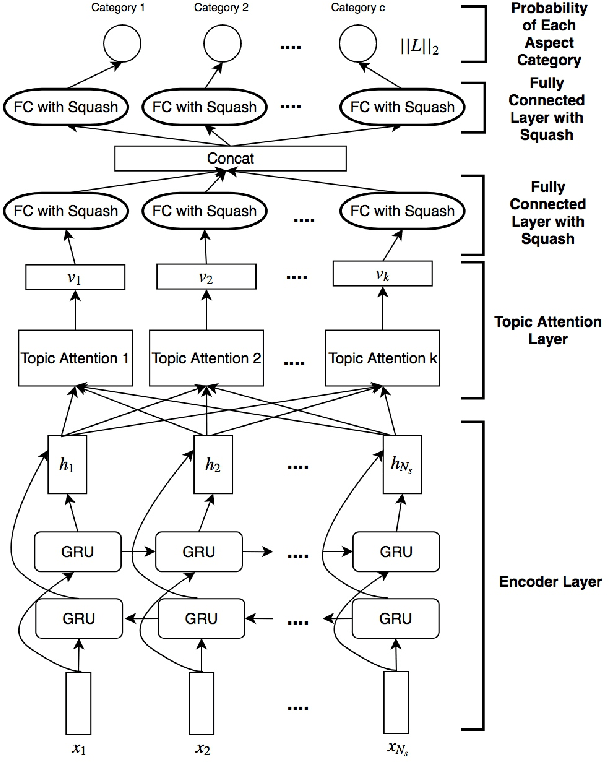
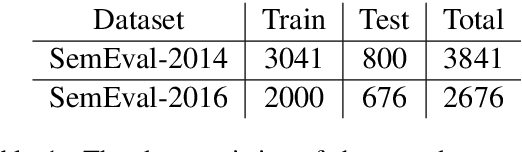
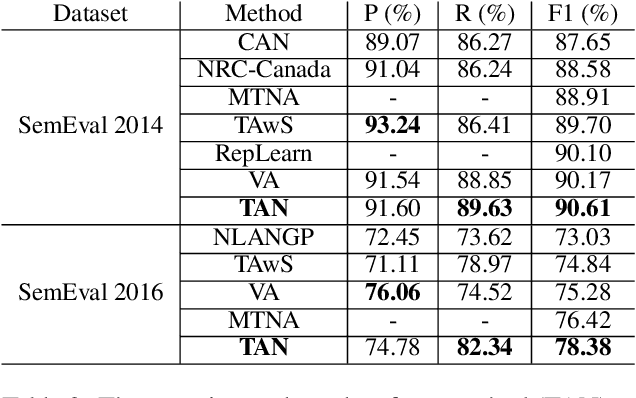
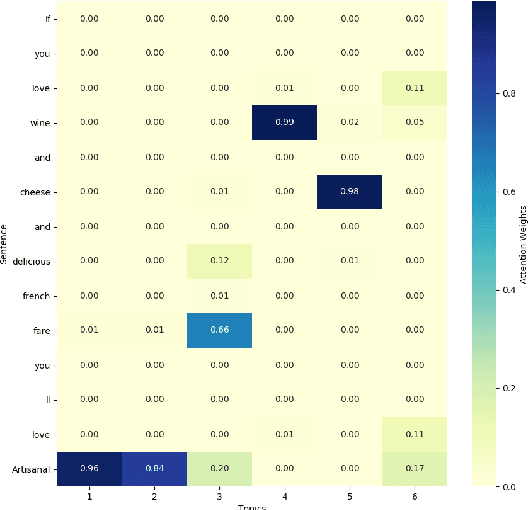
The e-commerce has started a new trend in natural language processing through sentiment analysis of user-generated reviews. Different consumers have different concerns about various aspects of a specific product or service. Aspect category detection, as a subtask of aspect-based sentiment analysis, tackles the problem of categorizing a given review sentence into a set of pre-defined aspect categories. In recent years, deep learning approaches have brought revolutionary advances in multiple branches of natural language processing including sentiment analysis. In this paper, we propose a deep neural network method based on attention mechanism to identify different aspect categories of a given review sentence. Our model utilizes several attentions with different topic contexts, enabling it to attend to different parts of a review sentence based on different topics. Experimental results on two datasets in the restaurant domain released by SemEval workshop demonstrates that our approach outperforms existing methods on both datasets. Visualization of the topic attention weights shows the effectiveness of our model in identifying words related to different topics.
An Unsupervised Approach for Aspect Category Detection Using Soft Cosine Similarity Measure
Dec 08, 2018
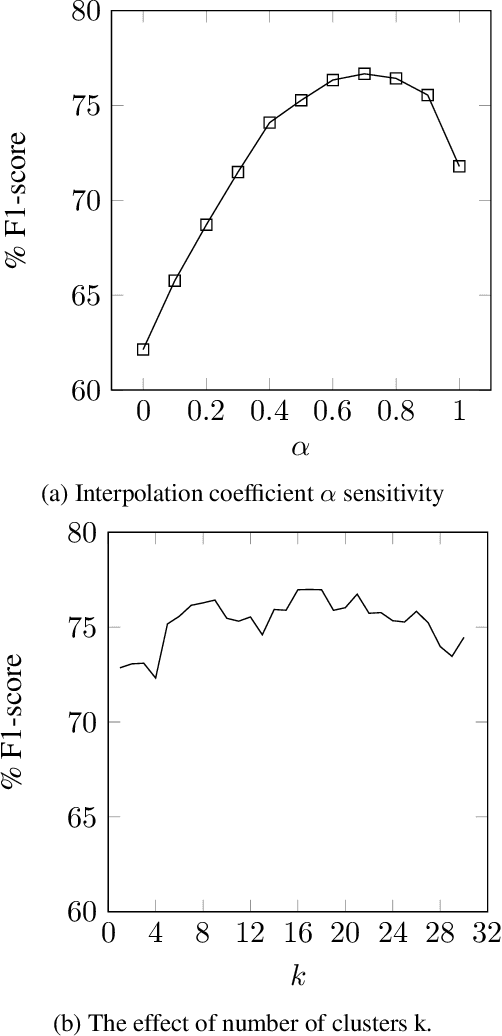
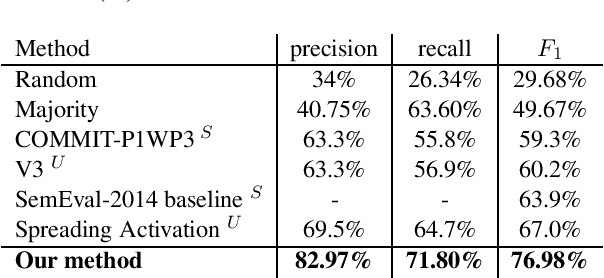
Aspect category detection is one of the important and challenging subtasks of aspect-based sentiment analysis. Given a set of pre-defined categories, this task aims to detect categories which are indicated implicitly or explicitly in a given review sentence. Supervised machine learning approaches perform well to accomplish this subtask. Note that, the performance of these methods depends on the availability of labeled train data, which is often difficult and costly to obtain. Besides, most of these supervised methods require feature engineering to perform well. In this paper, we propose an unsupervised method to address aspect category detection task without the need for any feature engineering. Our method utilizes clusters of unlabeled reviews and soft cosine similarity measure to accomplish aspect category detection task. Experimental results on SemEval-2014 restaurant dataset shows that proposed unsupervised approach outperforms several baselines by a substantial margin.