 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Empirical Study of Multimodal Model Merging
Apr 28, 2023Model merging (e.g., via interpolation or task arithmetic) fuses multiple models trained on different tasks to generate a multi-task solution. The technique has been proven successful in previous studies, where the models are trained on similar tasks and with the same initialization. In this paper, we expand on this concept to a multimodal setup by merging transformers trained on different modalities. Furthermore, we conduct our study for a novel goal where we can merge vision, language, and cross-modal transformers of a modality-specific architecture to create a parameter-efficient modality-agnostic architecture. Through comprehensive experiments, we systematically investigate the key factors impacting model performance after merging, including initialization, merging mechanisms, and model architectures. Our analysis leads to an effective training recipe for matching the performance of the modality-agnostic baseline (i.e. pre-trained from scratch) via model merging. Our code is available at: https://github.com/ylsung/vl-merging
ReCEval: Evaluating Reasoning Chains via Correctness and Informativeness
Apr 21, 2023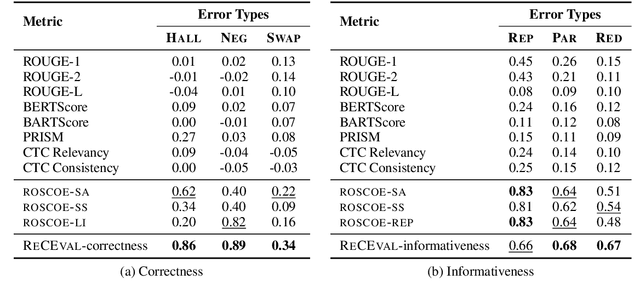
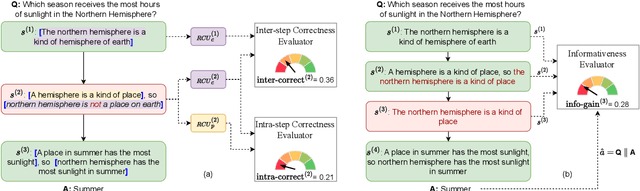
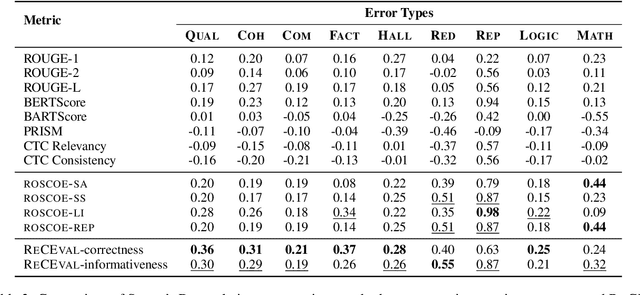
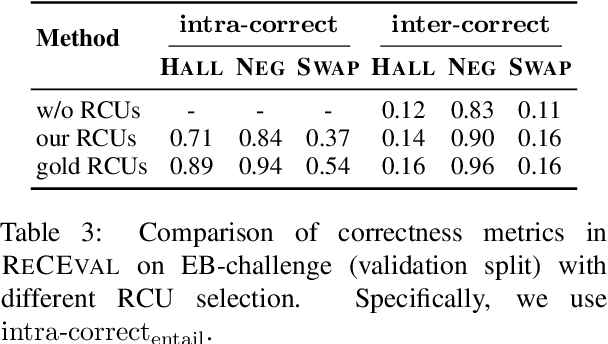
Multi-step reasoning ability is fundamental to many natural language tasks, yet it is unclear what constitutes a good reasoning chain and how to evaluate them. Most existing methods focus solely on whether the reasoning chain leads to the correct conclusion, but this answer-oriented view may confound the quality of reasoning with other spurious shortcuts to predict the answer. To bridge this gap, we evaluate reasoning chains by viewing them as informal proofs that derive the final answer. Specifically, we propose ReCEval (Reasoning Chain Evaluation), a framework that evaluates reasoning chains through two key properties: (1) correctness, i.e., each step makes a valid inference based on the information contained within the step, preceding steps, and input context, and (2) informativeness, i.e., each step provides new information that is helpful towards deriving the generated answer. We implement ReCEval using natural language inference models and information-theoretic measures. On multiple datasets, ReCEval is highly effective in identifying different types of errors, resulting in notable improvements compared to prior methods. We demonstrate that our informativeness metric captures the expected flow of information in high-quality reasoning chains and we also analyze the impact of previous steps on evaluating correctness and informativeness. Finally, we show that scoring reasoning chains based on ReCEval can improve downstream performance of reasoning tasks. Our code is publicly available at: https://github.com/archiki/ReCEval
Diagnostic Benchmark and Iterative Inpainting for Layout-Guided Image Generation
Apr 14, 2023
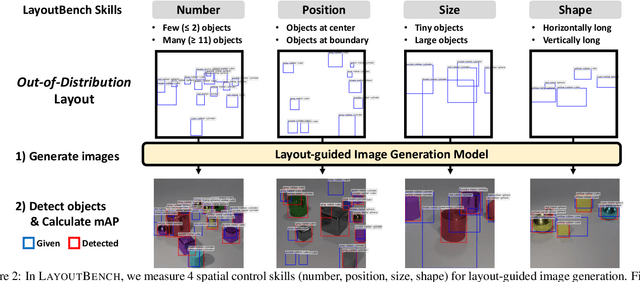
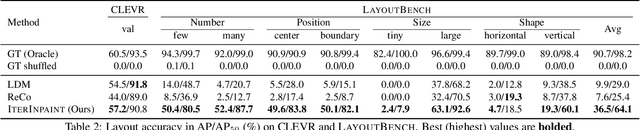
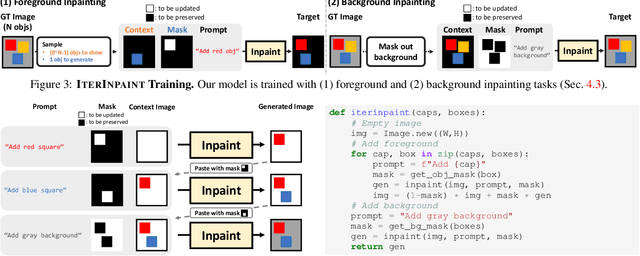
Spatial control is a core capability in controllable image generation. Advancements in layout-guided image generation have shown promising results on in-distribution (ID) datasets with similar spatial configurations. However, it is unclear how these models perform when facing out-of-distribution (OOD) samples with arbitrary, unseen layouts. In this paper, we propose LayoutBench, a diagnostic benchmark for layout-guided image generation that examines four categories of spatial control skills: number, position, size, and shape. We benchmark two recent representative layout-guided image generation methods and observe that the good ID layout control may not generalize well to arbitrary layouts in the wild (e.g., objects at the boundary). Next, we propose IterInpaint, a new baseline that generates foreground and background regions in a step-by-step manner via inpainting, demonstrating stronger generalizability than existing models on OOD layouts in LayoutBench. We perform quantitative and qualitative evaluation and fine-grained analysis on the four LayoutBench skills to pinpoint the weaknesses of existing models. Lastly, we show comprehensive ablation studies on IterInpaint, including training task ratio, crop&paste vs. repaint, and generation order. Project website: https://layoutbench.github.io
Improving Vision-and-Language Navigation by Generating Future-View Image Semantics
Apr 11, 2023Vision-and-Language Navigation (VLN) is the task that requires an agent to navigate through the environment based on natural language instructions. At each step, the agent takes the next action by selecting from a set of navigable locations. In this paper, we aim to take one step further and explore whether the agent can benefit from generating the potential future view during navigation. Intuitively, humans will have an expectation of how the future environment will look like, based on the natural language instructions and surrounding views, which will aid correct navigation. Hence, to equip the agent with this ability to generate the semantics of future navigation views, we first propose three proxy tasks during the agent's in-domain pre-training: Masked Panorama Modeling (MPM), Masked Trajectory Modeling (MTM), and Action Prediction with Image Generation (APIG). These three objectives teach the model to predict missing views in a panorama (MPM), predict missing steps in the full trajectory (MTM), and generate the next view based on the full instruction and navigation history (APIG), respectively. We then fine-tune the agent on the VLN task with an auxiliary loss that minimizes the difference between the view semantics generated by the agent and the ground truth view semantics of the next step. Empirically, our VLN-SIG achieves the new state-of-the-art on both the Room-to-Room dataset and the CVDN dataset. We further show that our agent learns to fill in missing patches in future views qualitatively, which brings more interpretability over agents' predicted actions. Lastly, we demonstrate that learning to predict future view semantics also enables the agent to have better performance on longer paths.
Hierarchical Video-Moment Retrieval and Step-Captioning
Mar 29, 2023



There is growing interest in searching for information from large video corpora. Prior works have studied relevant tasks, such as text-based video retrieval, moment retrieval, video summarization, and video captioning in isolation, without an end-to-end setup that can jointly search from video corpora and generate summaries. Such an end-to-end setup would allow for many interesting applications, e.g., a text-based search that finds a relevant video from a video corpus, extracts the most relevant moment from that video, and segments the moment into important steps with captions. To address this, we present the HiREST (HIerarchical REtrieval and STep-captioning) dataset and propose a new benchmark that covers hierarchical information retrieval and visual/textual stepwise summarization from an instructional video corpus. HiREST consists of 3.4K text-video pairs from an instructional video dataset, where 1.1K videos have annotations of moment spans relevant to text query and breakdown of each moment into key instruction steps with caption and timestamps (totaling 8.6K step captions). Our hierarchical benchmark consists of video retrieval, moment retrieval, and two novel moment segmentation and step captioning tasks. In moment segmentation, models break down a video moment into instruction steps and identify start-end boundaries. In step captioning, models generate a textual summary for each step. We also present starting point task-specific and end-to-end joint baseline models for our new benchmark. While the baseline models show some promising results, there still exists large room for future improvement by the community. Project website: https://hirest-cvpr2023.github.io
Exposing and Addressing Cross-Task Inconsistency in Unified Vision-Language Models
Mar 28, 2023As general purpose vision models get increasingly effective at a wide set of tasks, it is imperative that they be consistent across the tasks they support. Inconsistent AI models are considered brittle and untrustworthy by human users and are more challenging to incorporate into larger systems that take dependencies on their outputs. Measuring consistency between very heterogeneous tasks that might include outputs in different modalities is challenging since it is difficult to determine if the predictions are consistent with one another. As a solution, we introduce a benchmark dataset, COCOCON, where we use contrast sets created by modifying test instances for multiple tasks in small but semantically meaningful ways to change the gold label, and outline metrics for measuring if a model is consistent by ranking the original and perturbed instances across tasks. We find that state-of-the-art systems suffer from a surprisingly high degree of inconsistent behavior across tasks, especially for more heterogeneous tasks. Finally, we propose using a rank correlation-based auxiliary objective computed over large automatically created cross-task contrast sets to improve the multi-task consistency of large unified models, while retaining their original accuracy on downstream tasks. Project website available at https://adymaharana.github.io/cococon/
Faithfulness-Aware Decoding Strategies for Abstractive Summarization
Mar 06, 2023



Despite significant progress in understanding and improving faithfulness in abstractive summarization, the question of how decoding strategies affect faithfulness is less studied. We present a systematic study of the effect of generation techniques such as beam search and nucleus sampling on faithfulness in abstractive summarization. We find a consistent trend where beam search with large beam sizes produces the most faithful summaries while nucleus sampling generates the least faithful ones. We propose two faithfulness-aware generation methods to further improve faithfulness over current generation techniques: (1) ranking candidates generated by beam search using automatic faithfulness metrics and (2) incorporating lookahead heuristics that produce a faithfulness score on the future summary. We show that both generation methods significantly improve faithfulness across two datasets as evaluated by four automatic faithfulness metrics and human evaluation. To reduce computational cost, we demonstrate a simple distillation approach that allows the model to generate faithful summaries with just greedy decoding. Our code is publicly available at https://github.com/amazon-science/faithful-summarization-generation
Does Localization Inform Editing? Surprising Differences in Causality-Based Localization vs. Knowledge Editing in Language Models
Jan 10, 2023



Language models are known to learn a great quantity of factual information during pretraining, and recent work localizes this information to specific model weights like mid-layer MLP weights (Meng et al., 2022). In this paper, we find that we can change how a fact is stored in a model by editing weights that are in a different location than where existing methods suggest that the fact is stored. This is surprising because we would expect that localizing facts to specific parameters in models would tell us where to manipulate knowledge in models, and this assumption has motivated past work on model editing methods. Specifically, we show that localization conclusions from representation denoising (also known as Causal Tracing) do not provide any insight into which model MLP layer would be best to edit in order to override an existing stored fact with a new one. This finding raises questions about how past work relies on Causal Tracing to select which model layers to edit (Meng et al., 2022). Next, to better understand the discrepancy between representation denoising and weight editing, we develop several variants of the editing problem that appear more and more like representation denoising in their design and objective. Experiments show that, for one of our editing problems, editing performance does relate to localization results from representation denoising, but we find that which layer we edit is a far better predictor of performance. Our results suggest, counterintuitively, that better mechanistic understanding of how pretrained language models work may not always translate to insights about how to best change their behavior. Code is available at: https://github.com/google/belief-localization
Unifying Vision, Text, and Layout for Universal Document Processing
Dec 20, 2022



We propose Universal Document Processing (UDOP), a foundation Document AI model which unifies text, image, and layout modalities together with varied task formats, including document understanding and generation. UDOP leverages the spatial correlation between textual content and document image to model image, text, and layout modalities with one uniform representation. With a novel Vision-Text-Layout Transformer, UDOP unifies pretraining and multi-domain downstream tasks into a prompt-based sequence generation scheme. UDOP is pretrained on both large-scale unlabeled document corpora using innovative self-supervised objectives and diverse labeled data. UDOP also learns to generate document images from text and layout modalities via masked image reconstruction. To the best of our knowledge, this is the first time in the field of document AI that one model simultaneously achieves high-quality neural document editing and content customization. Our method sets the state-of-the-art on 9 Document AI tasks, e.g., document understanding and QA, across diverse data domains like finance reports, academic papers, and websites. UDOP ranks first on the leaderboard of the Document Understanding Benchmark (DUE).
MURMUR: Modular Multi-Step Reasoning for Semi-Structured Data-to-Text Generation
Dec 16, 2022



Prompting large language models has enabled significant recent progress in multi-step reasoning over text. However, when applied to text generation from semi-structured data (e.g., graphs or tables), these methods typically suffer from low semantic coverage, hallucination, and logical inconsistency. We propose MURMUR, a neuro-symbolic modular approach to text generation from semi-structured data with multi-step reasoning. MURMUR is a best-first search method that generates reasoning paths using: (1) neural and symbolic modules with specific linguistic and logical skills, (2) a grammar whose production rules define valid compositions of modules, and (3) value functions that assess the quality of each reasoning step. We conduct experiments on two diverse data-to-text generation tasks like WebNLG and LogicNLG. These tasks differ in their data representations (graphs and tables) and span multiple linguistic and logical skills. MURMUR obtains significant improvements over recent few-shot baselines like direct prompting and chain-of-thought prompting, while also achieving comparable performance to fine-tuned GPT-2 on out-of-domain data. Moreover, human evaluation shows that MURMUR generates highly faithful and correct reasoning paths that lead to 26% more logically consistent summaries on LogicNLG, compared to direct prompting.