 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePhotorealistic Text-to-Image Diffusion Models with Deep Language Understanding
May 23, 2022

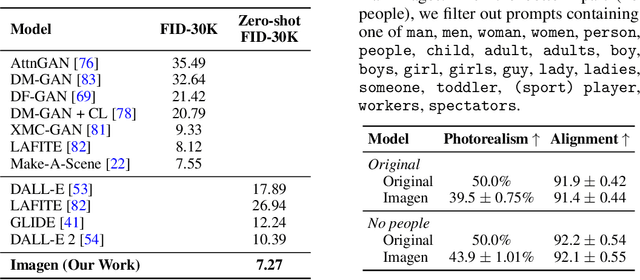
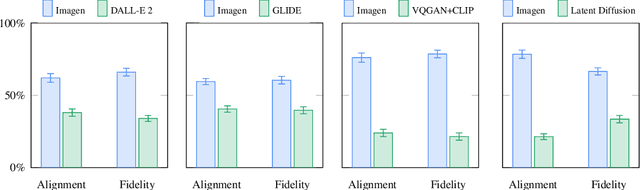
We present Imagen, a text-to-image diffusion model with an unprecedented degree of photorealism and a deep level of language understanding. Imagen builds on the power of large transformer language models in understanding text and hinges on the strength of diffusion models in high-fidelity image generation. Our key discovery is that generic large language models (e.g. T5), pretrained on text-only corpora, are surprisingly effective at encoding text for image synthesis: increasing the size of the language model in Imagen boosts both sample fidelity and image-text alignment much more than increasing the size of the image diffusion model. Imagen achieves a new state-of-the-art FID score of 7.27 on the COCO dataset, without ever training on COCO, and human raters find Imagen samples to be on par with the COCO data itself in image-text alignment. To assess text-to-image models in greater depth, we introduce DrawBench, a comprehensive and challenging benchmark for text-to-image models. With DrawBench, we compare Imagen with recent methods including VQ-GAN+CLIP, Latent Diffusion Models, and DALL-E 2, and find that human raters prefer Imagen over other models in side-by-side comparisons, both in terms of sample quality and image-text alignment. See https://imagen.research.google/ for an overview of the results.
Decoder Denoising Pretraining for Semantic Segmentation
May 23, 2022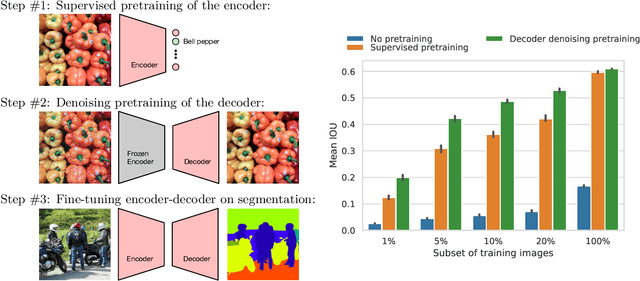
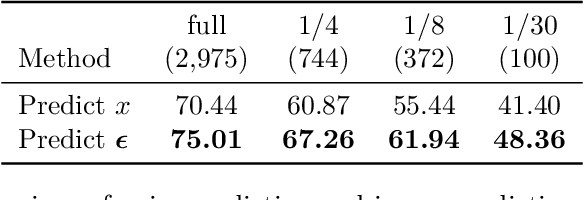
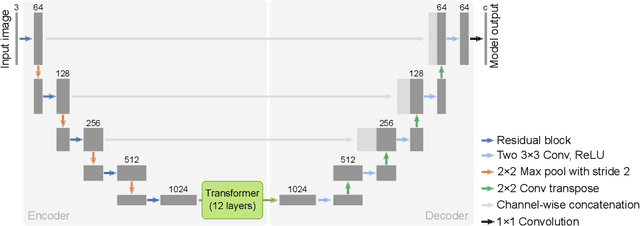
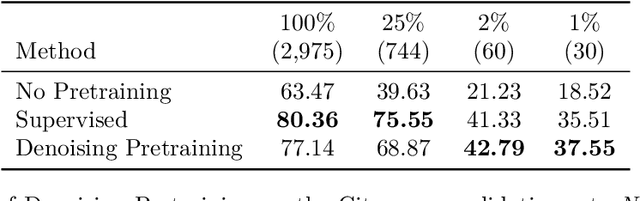
Semantic segmentation labels are expensive and time consuming to acquire. Hence, pretraining is commonly used to improve the label-efficiency of segmentation models. Typically, the encoder of a segmentation model is pretrained as a classifier and the decoder is randomly initialized. Here, we argue that random initialization of the decoder can be suboptimal, especially when few labeled examples are available. We propose a decoder pretraining approach based on denoising, which can be combined with supervised pretraining of the encoder. We find that decoder denoising pretraining on the ImageNet dataset strongly outperforms encoder-only supervised pretraining. Despite its simplicity, decoder denoising pretraining achieves state-of-the-art results on label-efficient semantic segmentation and offers considerable gains on the Cityscapes, Pascal Context, and ADE20K datasets.
Robust and Efficient Medical Imaging with Self-Supervision
May 19, 2022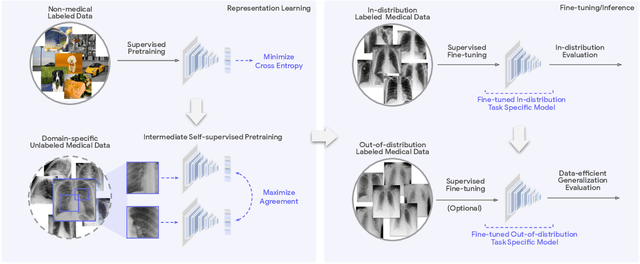
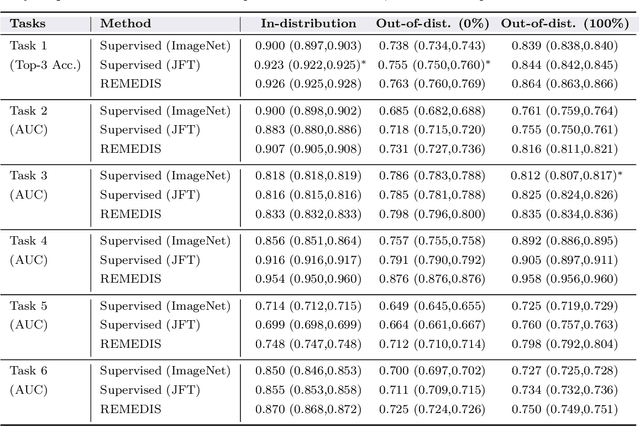
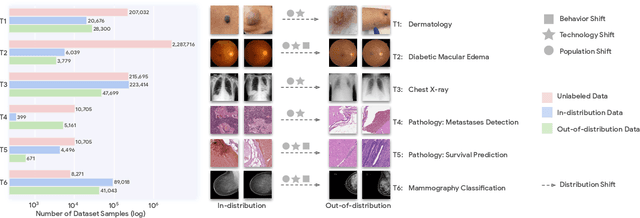

Recent progress in Medical Artificial Intelligence (AI) has delivered systems that can reach clinical expert level performance. However, such systems tend to demonstrate sub-optimal "out-of-distribution" performance when evaluated in clinical settings different from the training environment. A common mitigation strategy is to develop separate systems for each clinical setting using site-specific data [1]. However, this quickly becomes impractical as medical data is time-consuming to acquire and expensive to annotate [2]. Thus, the problem of "data-efficient generalization" presents an ongoing difficulty for Medical AI development. Although progress in representation learning shows promise, their benefits have not been rigorously studied, specifically for out-of-distribution settings. To meet these challenges, we present REMEDIS, a unified representation learning strategy to improve robustness and data-efficiency of medical imaging AI. REMEDIS uses a generic combination of large-scale supervised transfer learning with self-supervised learning and requires little task-specific customization. We study a diverse range of medical imaging tasks and simulate three realistic application scenarios using retrospective data. REMEDIS exhibits significantly improved in-distribution performance with up to 11.5% relative improvement in diagnostic accuracy over a strong supervised baseline. More importantly, our strategy leads to strong data-efficient generalization of medical imaging AI, matching strong supervised baselines using between 1% to 33% of retraining data across tasks. These results suggest that REMEDIS can significantly accelerate the life-cycle of medical imaging AI development thereby presenting an important step forward for medical imaging AI to deliver broad impact.
Video Diffusion Models
Apr 07, 2022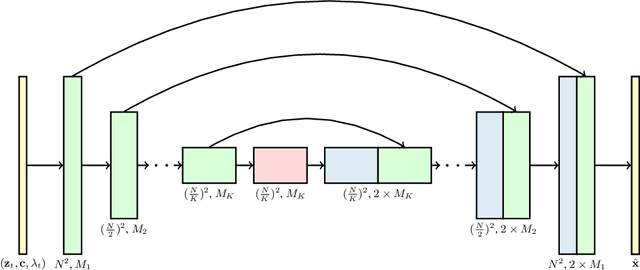
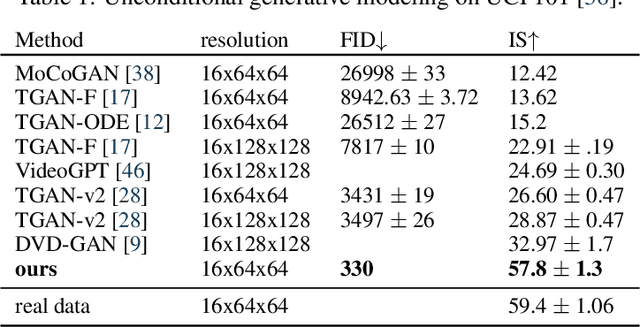


Generating temporally coherent high fidelity video is an important milestone in generative modeling research. We make progress towards this milestone by proposing a diffusion model for video generation that shows very promising initial results. Our model is a natural extension of the standard image diffusion architecture, and it enables jointly training from image and video data, which we find to reduce the variance of minibatch gradients and speed up optimization. To generate long and higher resolution videos we introduce a new conditional sampling technique for spatial and temporal video extension that performs better than previously proposed methods. We present the first results on a large text-conditioned video generation task, as well as state-of-the-art results on an established unconditional video generation benchmark. Supplementary material is available at https://video-diffusion.github.io/
Learning Fast Samplers for Diffusion Models by Differentiating Through Sample Quality
Feb 11, 2022



Diffusion models have emerged as an expressive family of generative models rivaling GANs in sample quality and autoregressive models in likelihood scores. Standard diffusion models typically require hundreds of forward passes through the model to generate a single high-fidelity sample. We introduce Differentiable Diffusion Sampler Search (DDSS): a method that optimizes fast samplers for any pre-trained diffusion model by differentiating through sample quality scores. We also present Generalized Gaussian Diffusion Models (GGDM), a family of flexible non-Markovian samplers for diffusion models. We show that optimizing the degrees of freedom of GGDM samplers by maximizing sample quality scores via gradient descent leads to improved sample quality. Our optimization procedure backpropagates through the sampling process using the reparametrization trick and gradient rematerialization. DDSS achieves strong results on unconditional image generation across various datasets (e.g., FID scores on LSUN church 128x128 of 11.6 with only 10 inference steps, and 4.82 with 20 steps, compared to 51.1 and 14.9 with strongest DDPM/DDIM baselines). Our method is compatible with any pre-trained diffusion model without fine-tuning or re-training required.
Palette: Image-to-Image Diffusion Models
Nov 10, 2021
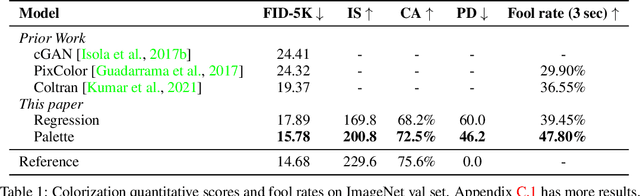

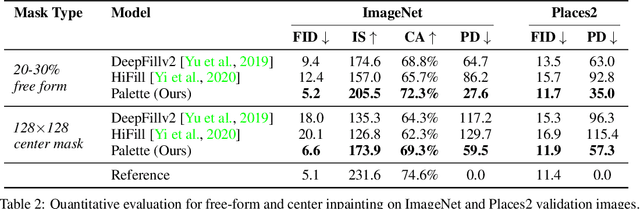
We introduce Palette, a simple and general framework for image-to-image translation using conditional diffusion models. On four challenging image-to-image translation tasks (colorization, inpainting, uncropping, and JPEG decompression), Palette outperforms strong GAN and regression baselines, and establishes a new state of the art. This is accomplished without task-specific hyper-parameter tuning, architecture customization, or any auxiliary loss, demonstrating a desirable degree of generality and flexibility. We uncover the impact of using $L_2$ vs. $L_1$ loss in the denoising diffusion objective on sample diversity, and demonstrate the importance of self-attention through empirical architecture studies. Importantly, we advocate a unified evaluation protocol based on ImageNet, and report several sample quality scores including FID, Inception Score, Classification Accuracy of a pre-trained ResNet-50, and Perceptual Distance against reference images for various baselines. We expect this standardized evaluation protocol to play a critical role in advancing image-to-image translation research. Finally, we show that a single generalist Palette model trained on 3 tasks (colorization, inpainting, JPEG decompression) performs as well or better than task-specific specialist counterparts.
WaveGrad 2: Iterative Refinement for Text-to-Speech Synthesis
Jun 19, 2021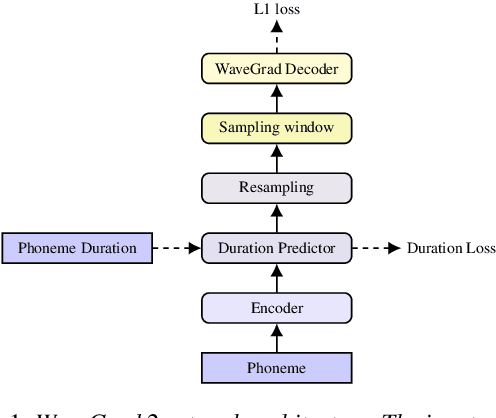
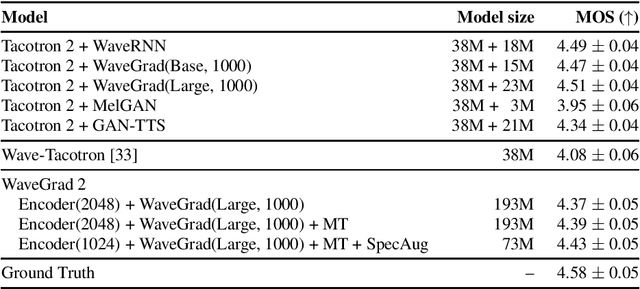
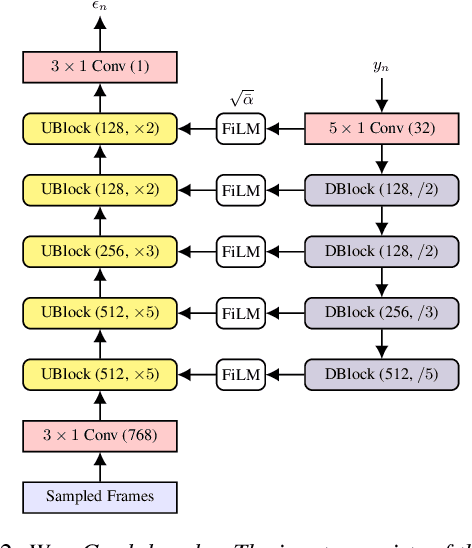

This paper introduces WaveGrad 2, a non-autoregressive generative model for text-to-speech synthesis. WaveGrad 2 is trained to estimate the gradient of the log conditional density of the waveform given a phoneme sequence. The model takes an input phoneme sequence, and through an iterative refinement process, generates an audio waveform. This contrasts to the original WaveGrad vocoder which conditions on mel-spectrogram features, generated by a separate model. The iterative refinement process starts from Gaussian noise, and through a series of refinement steps (e.g., 50 steps), progressively recovers the audio sequence. WaveGrad 2 offers a natural way to trade-off between inference speed and sample quality, through adjusting the number of refinement steps. Experiments show that the model can generate high fidelity audio, approaching the performance of a state-of-the-art neural TTS system. We also report various ablation studies over different model configurations. Audio samples are available at https://wavegrad.github.io/v2.
Generate, Annotate, and Learn: Generative Models Advance Self-Training and Knowledge Distillation
Jun 11, 2021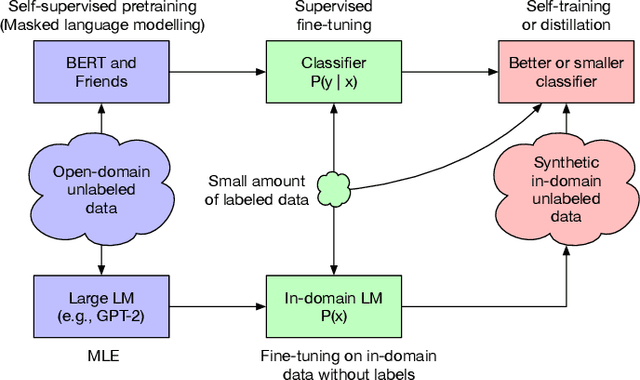
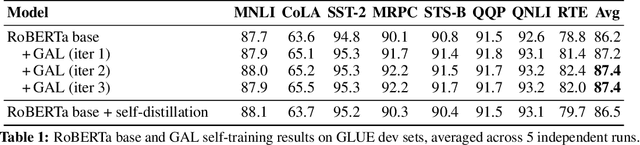
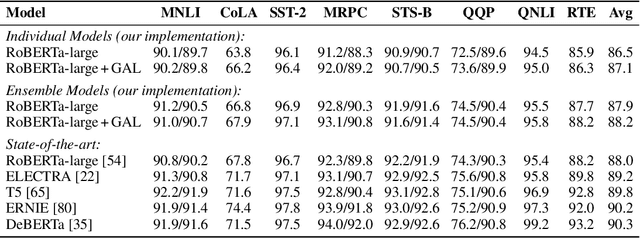
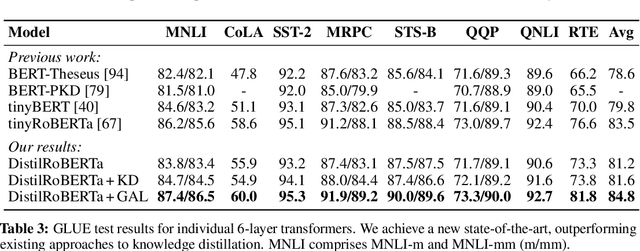
Semi-Supervised Learning (SSL) has seen success in many application domains, but this success often hinges on the availability of task-specific unlabeled data. Knowledge distillation (KD) has enabled compressing deep networks and ensembles, achieving the best results when distilling knowledge on fresh task-specific unlabeled examples. However, task-specific unlabeled data can be challenging to find. We present a general framework called "generate, annotate, and learn (GAL)" that uses unconditional generative models to synthesize in-domain unlabeled data, helping advance SSL and KD on different tasks. To obtain strong task-specific generative models, we adopt generic generative models, pretrained on open-domain data, and fine-tune them on inputs from specific tasks. Then, we use existing classifiers to annotate generated unlabeled examples with soft pseudo labels, which are used for additional training. When self-training is combined with samples generated from GPT2-large, fine-tuned on the inputs of each GLUE task, we outperform a strong RoBERTa-large baseline on the GLUE benchmark. Moreover, KD on GPT-2 samples yields a new state-of-the-art for 6-layer transformers on the GLUE leaderboard. Finally, self-training with GAL offers significant gains on image classification on CIFAR-10 and four tabular tasks from the UCI repository
Learning to Efficiently Sample from Diffusion Probabilistic Models
Jun 07, 2021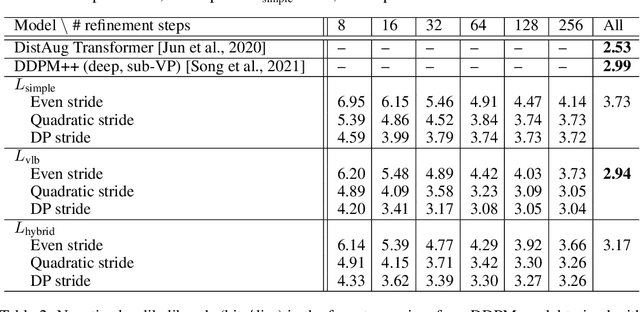
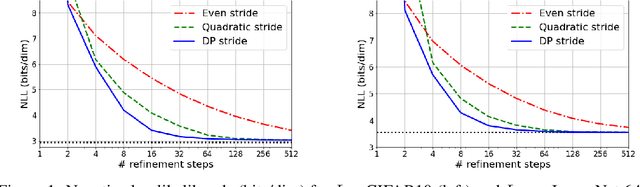
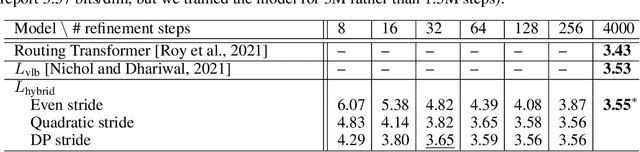
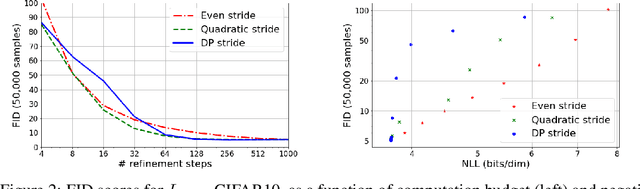
Denoising Diffusion Probabilistic Models (DDPMs) have emerged as a powerful family of generative models that can yield high-fidelity samples and competitive log-likelihoods across a range of domains, including image and speech synthesis. Key advantages of DDPMs include ease of training, in contrast to generative adversarial networks, and speed of generation, in contrast to autoregressive models. However, DDPMs typically require hundreds-to-thousands of steps to generate a high fidelity sample, making them prohibitively expensive for high dimensional problems. Fortunately, DDPMs allow trading generation speed for sample quality through adjusting the number of refinement steps as a post process. Prior work has been successful in improving generation speed through handcrafting the time schedule by trial and error. We instead view the selection of the inference time schedules as an optimization problem, and introduce an exact dynamic programming algorithm that finds the optimal discrete time schedules for any pre-trained DDPM. Our method exploits the fact that ELBO can be decomposed into separate KL terms, and given any computation budget, discovers the time schedule that maximizes the training ELBO exactly. Our method is efficient, has no hyper-parameters of its own, and can be applied to any pre-trained DDPM with no retraining. We discover inference time schedules requiring as few as 32 refinement steps, while sacrificing less than 0.1 bits per dimension compared to the default 4,000 steps used on ImageNet 64x64 [Ho et al., 2020; Nichol and Dhariwal, 2021].
Autoregressive Dynamics Models for Offline Policy Evaluation and Optimization
Apr 28, 2021

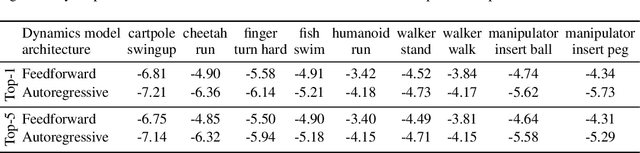

Standard dynamics models for continuous control make use of feedforward computation to predict the conditional distribution of next state and reward given current state and action using a multivariate Gaussian with a diagonal covariance structure. This modeling choice assumes that different dimensions of the next state and reward are conditionally independent given the current state and action and may be driven by the fact that fully observable physics-based simulation environments entail deterministic transition dynamics. In this paper, we challenge this conditional independence assumption and propose a family of expressive autoregressive dynamics models that generate different dimensions of the next state and reward sequentially conditioned on previous dimensions. We demonstrate that autoregressive dynamics models indeed outperform standard feedforward models in log-likelihood on heldout transitions. Furthermore, we compare different model-based and model-free off-policy evaluation (OPE) methods on RL Unplugged, a suite of offline MuJoCo datasets, and find that autoregressive dynamics models consistently outperform all baselines, achieving a new state-of-the-art. Finally, we show that autoregressive dynamics models are useful for offline policy optimization by serving as a way to enrich the replay buffer through data augmentation and improving performance using model-based planning.