 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProximal Gradient Temporal Difference Learning: Stable Reinforcement Learning with Polynomial Sample Complexity
Jun 06, 2020
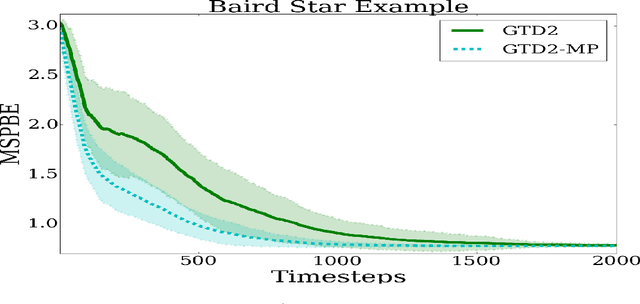
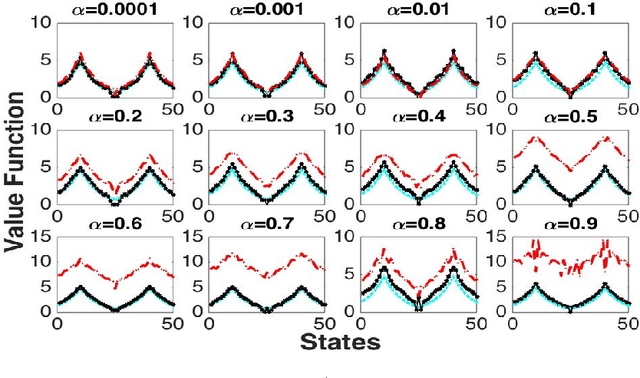
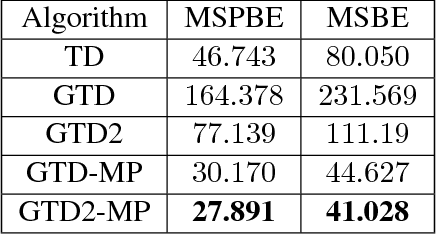
In this paper, we introduce proximal gradient temporal difference learning, which provides a principled way of designing and analyzing true stochastic gradient temporal difference learning algorithms. We show how gradient TD (GTD) reinforcement learning methods can be formally derived, not by starting from their original objective functions, as previously attempted, but rather from a primal-dual saddle-point objective function. We also conduct a saddle-point error analysis to obtain finite-sample bounds on their performance. Previous analyses of this class of algorithms use stochastic approximation techniques to prove asymptotic convergence, and do not provide any finite-sample analysis. We also propose an accelerated algorithm, called GTD2-MP, that uses proximal ``mirror maps'' to yield an improved convergence rate. The results of our theoretical analysis imply that the GTD family of algorithms are comparable and may indeed be preferred over existing least squares TD methods for off-policy learning, due to their linear complexity. We provide experimental results showing the improved performance of our accelerated gradient TD methods.
Automatic Policy Synthesis to Improve the Safety of Nonlinear Dynamical Systems
Jun 06, 2020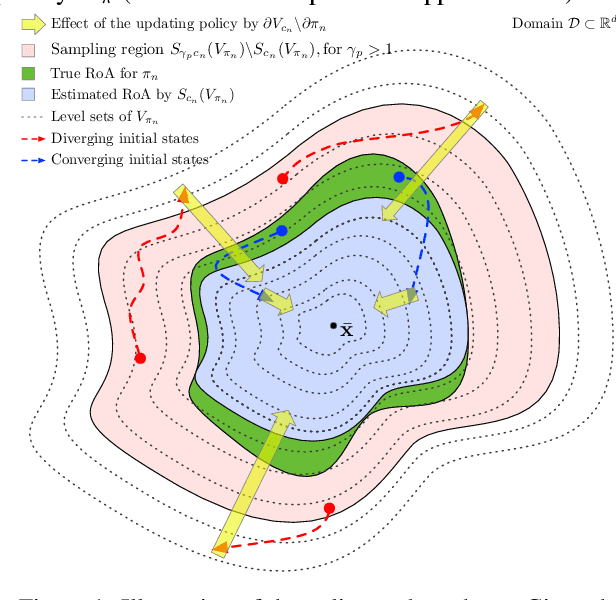
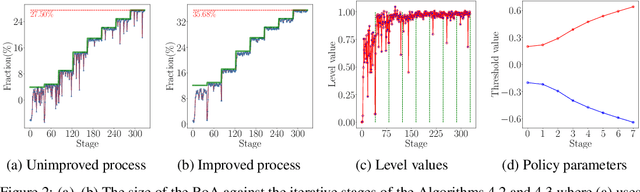
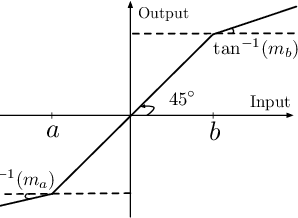
Learning controllers merely based on a performance metric has been proven effective in many physical and non-physical tasks in both control theory and reinforcement learning. However, in practice, the controller must guarantee some notion of safety to ensure that it does not harm either the agent or the environment. Stability is a crucial notion of safety, whose violation can certainly cause unsafe behaviors. Lyapunov functions are effective tools to assess stability in nonlinear dynamical systems. In this paper, we combine an improving Lyapunov function with automatic controller synthesis to obtain control policies with large safe regions. We propose a two-player collaborative algorithm that alternates between estimating a Lyapunov function and deriving a controller that gradually enlarges the stability region of the closed-loop system. We provide theoretical results on the class of systems that can be treated with the proposed algorithm and empirically evaluate the effectiveness of our method using an exemplary dynamical system.
Active Model Estimation in Markov Decision Processes
Mar 06, 2020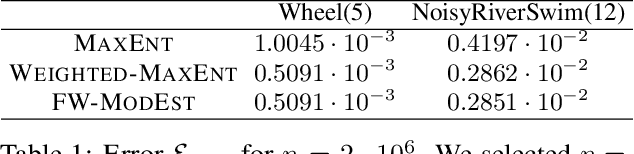
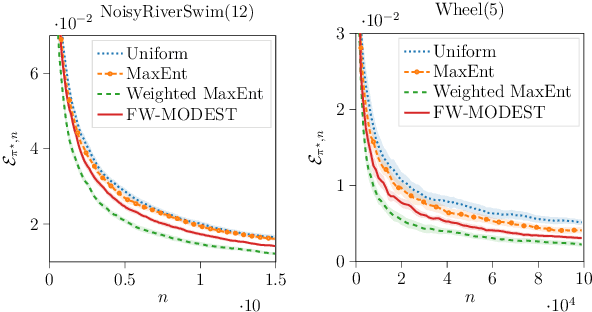
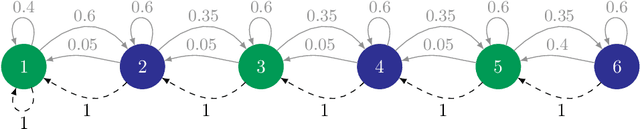
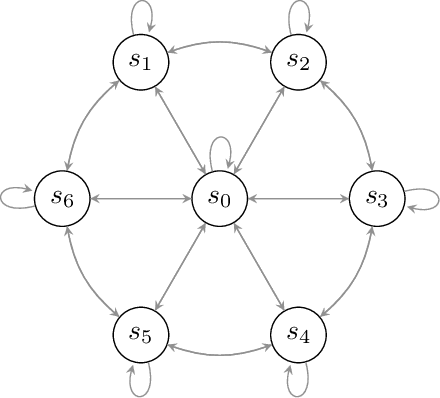
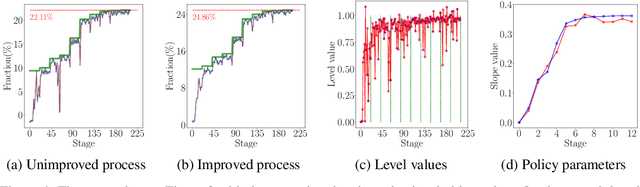
We study the problem of efficient exploration in order to learn an accurate model of an environment, modeled as a Markov decision process (MDP). Efficient exploration in this problem requires the agent to identify the regions in which estimating the model is more difficult and then exploit this knowledge to collect more samples there. In this paper, we formalize this problem, introduce the first algorithm to learn an $\epsilon$-accurate estimate of the dynamics, and provide its sample complexity analysis. While this algorithm enjoys strong guarantees in the large-sample regime, it tends to have a poor performance in early stages of exploration. To address this issue, we propose an algorithm that is based on maximum weighted entropy, a heuristic that stems from common sense and our theoretical analysis. The main idea here is cover the entire state-action space with the weight proportional to the noise in the transitions. Using a number of simple domains with heterogeneous noise in their transitions, we show that our heuristic-based algorithm outperforms both our original algorithm and the maximum entropy algorithm in the small sample regime, while achieving similar asymptotic performance as that of the original algorithm.
Predictive Coding for Locally-Linear Control
Mar 02, 2020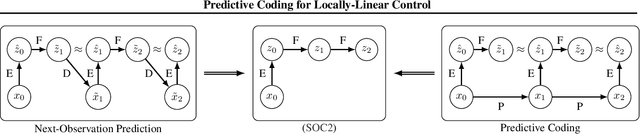
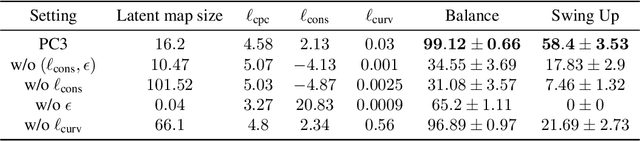


High-dimensional observations and unknown dynamics are major challenges when applying optimal control to many real-world decision making tasks. The Learning Controllable Embedding (LCE) framework addresses these challenges by embedding the observations into a lower dimensional latent space, estimating the latent dynamics, and then performing control directly in the latent space. To ensure the learned latent dynamics are predictive of next-observations, all existing LCE approaches decode back into the observation space and explicitly perform next-observation prediction---a challenging high-dimensional task that furthermore introduces a large number of nuisance parameters (i.e., the decoder) which are discarded during control. In this paper, we propose a novel information-theoretic LCE approach and show theoretically that explicit next-observation prediction can be replaced with predictive coding. We then use predictive coding to develop a decoder-free LCE model whose latent dynamics are amenable to locally-linear control. Extensive experiments on benchmark tasks show that our model reliably learns a controllable latent space that leads to superior performance when compared with state-of-the-art LCE baselines.
Policy-Aware Model Learning for Policy Gradient Methods
Feb 28, 2020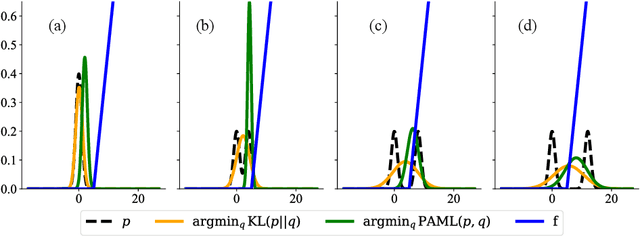
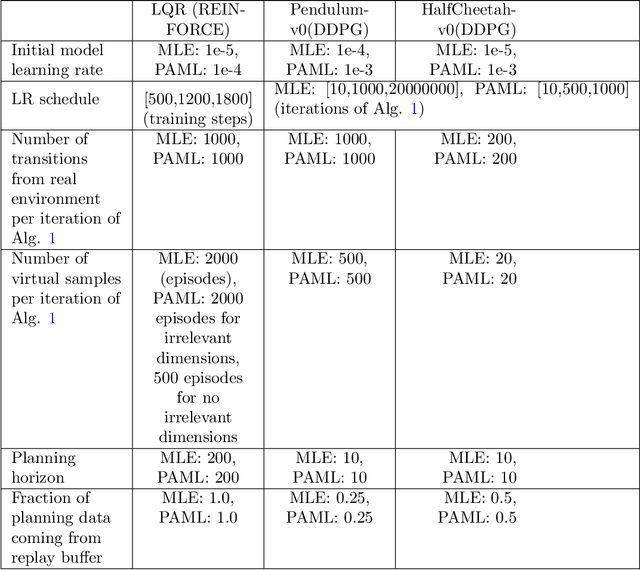
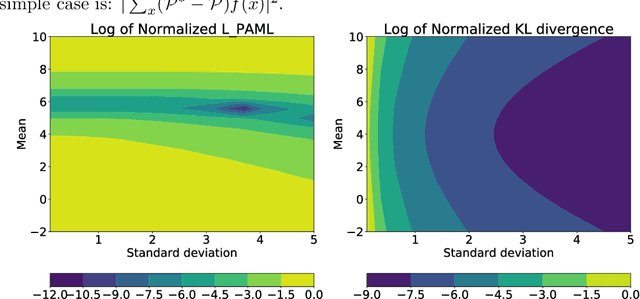
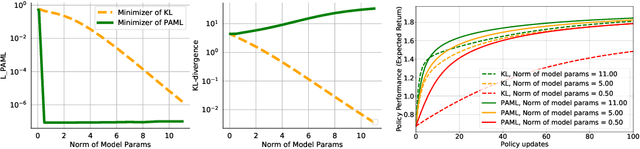
This paper considers the problem of learning a model in model-based reinforcement learning (MBRL). We examine how the planning module of an MBRL algorithm uses the model, and propose that the model learning module should incorporate the way the planner is going to use the model. This is in contrast to conventional model learning approaches, such as those based on maximum likelihood estimate, that learn a predictive model of the environment without explicitly considering the interaction of the model and the planner. We focus on policy gradient type of planning algorithms and derive new loss functions for model learning that incorporate how the planner uses the model. We call this approach Policy-Aware Model Learning (PAML). We theoretically analyze a generic model-based policy gradient algorithm and provide a convergence guarantee for the optimized policy. We also empirically evaluate PAML on some benchmark problems, showing promising results.
Improved Algorithms for Conservative Exploration in Bandits
Feb 08, 2020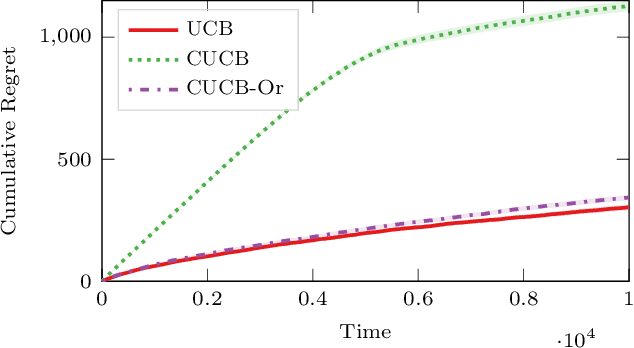
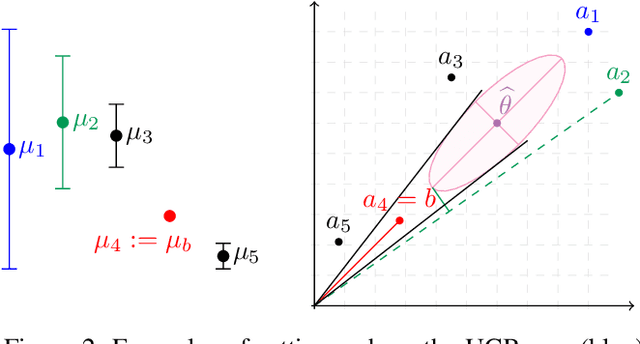
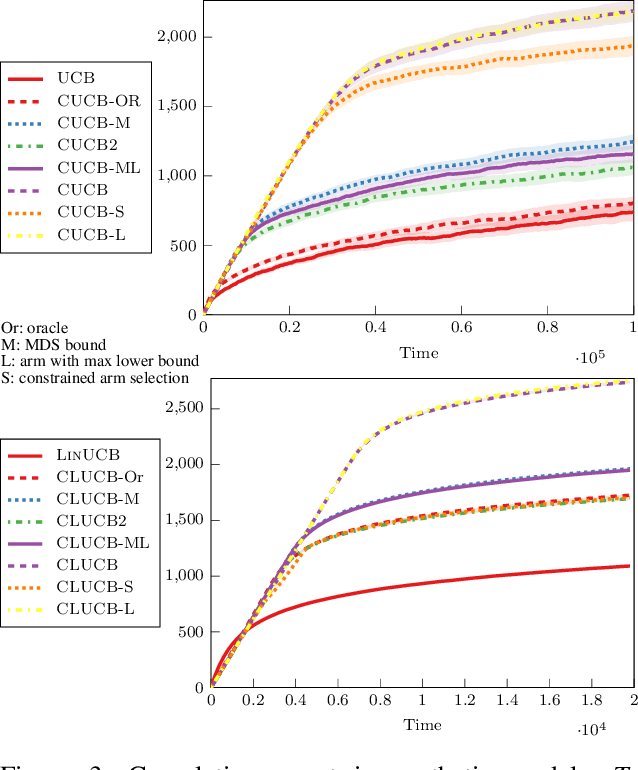
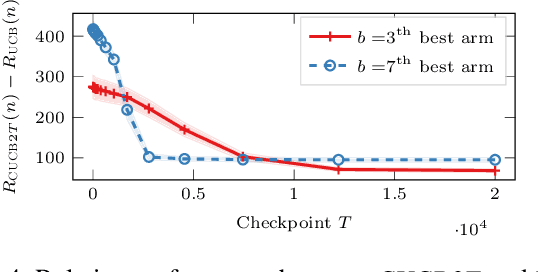
In many fields such as digital marketing, healthcare, finance, and robotics, it is common to have a well-tested and reliable baseline policy running in production (e.g., a recommender system). Nonetheless, the baseline policy is often suboptimal. In this case, it is desirable to deploy online learning algorithms (e.g., a multi-armed bandit algorithm) that interact with the system to learn a better/optimal policy under the constraint that during the learning process the performance is almost never worse than the performance of the baseline itself. In this paper, we study the conservative learning problem in the contextual linear bandit setting and introduce a novel algorithm, the Conservative Constrained LinUCB (CLUCB2). We derive regret bounds for CLUCB2 that match existing results and empirically show that it outperforms state-of-the-art conservative bandit algorithms in a number of synthetic and real-world problems. Finally, we consider a more realistic constraint where the performance is verified only at predefined checkpoints (instead of at every step) and show how this relaxed constraint favorably impacts the regret and empirical performance of CLUCB2.
Conservative Exploration in Reinforcement Learning
Feb 08, 2020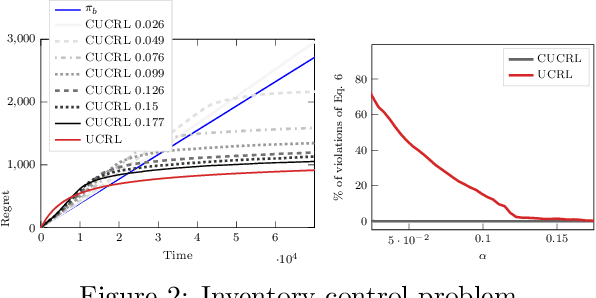

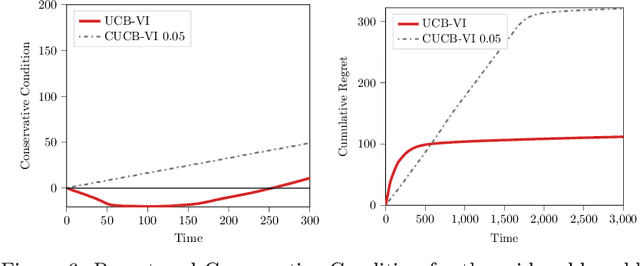
While learning in an unknown Markov Decision Process (MDP), an agent should trade off exploration to discover new information about the MDP, and exploitation of the current knowledge to maximize the reward. Although the agent will eventually learn a good or optimal policy, there is no guarantee on the quality of the intermediate policies. This lack of control is undesired in real-world applications where a minimum requirement is that the executed policies are guaranteed to perform at least as well as an existing baseline. In this paper, we introduce the notion of conservative exploration for average reward and finite horizon problems. We present two optimistic algorithms that guarantee (w.h.p.) that the conservative constraint is never violated during learning. We derive regret bounds showing that being conservative does not hinder the learning ability of these algorithms.
Adaptive Sampling for Estimating Multiple Probability Distributions
Dec 07, 2019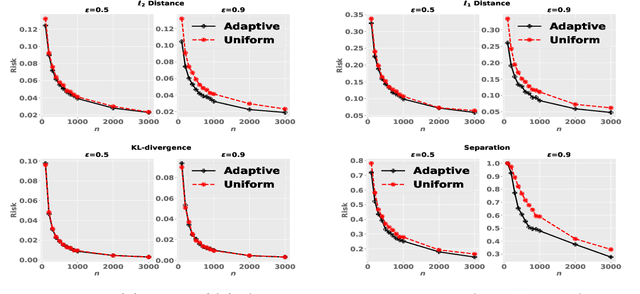
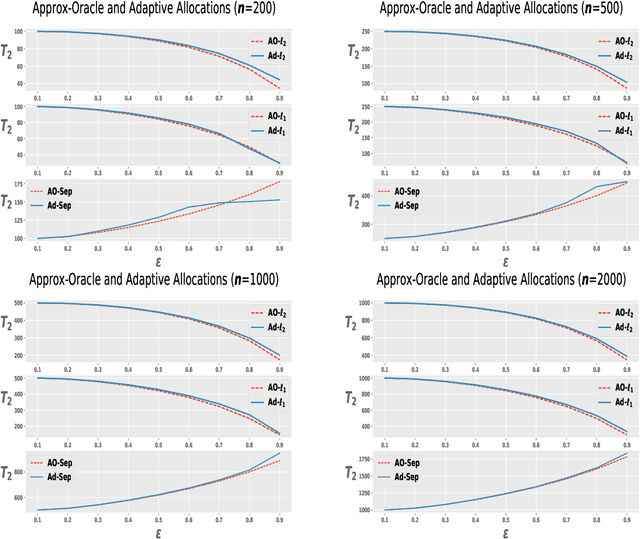
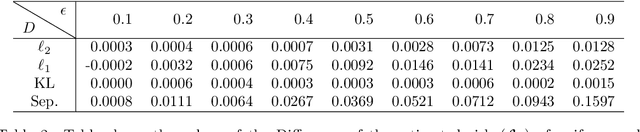

We consider the problem of allocating samples to a finite set of discrete distributions in order to learn them uniformly well in terms of four common distance measures: $\ell_2^2$, $\ell_1$, $f$-divergence, and separation distance. To present a unified treatment of these distances, we first propose a general optimistic tracking algorithm and analyze its sample allocation performance w.r.t.~an oracle. We then instantiate this algorithm for the four distance measures and derive bounds on the regret of their resulting allocation schemes. We verify our theoretical findings through some experiments. Finally, we show that the techniques developed in the paper can be easily extended to the related setting of minimizing the average error (in terms of the four distances) in learning a set of distributions.
Multi-step Greedy Policies in Model-Free Deep Reinforcement Learning
Oct 14, 2019
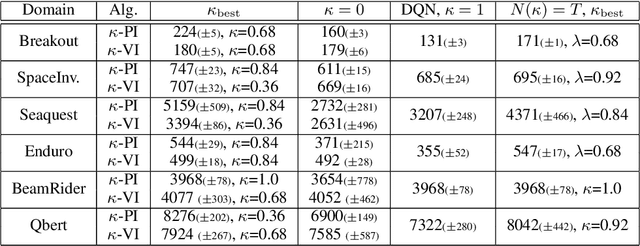
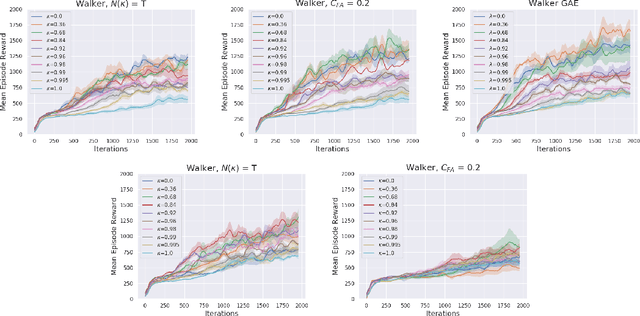
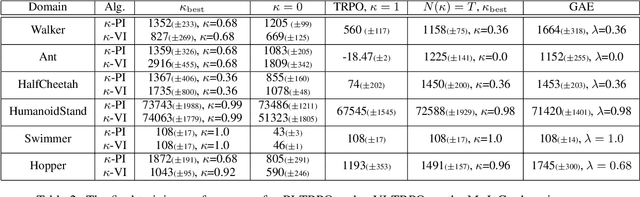
Multi-step greedy policies have been extensively used in model-based Reinforcement Learning (RL) and in the case when a model of the environment is available (e.g., in the game of Go). In this work, we explore the benefits of multi-step greedy policies in model-free RL when employed in the framework of multi-step Dynamic Programming (DP): multi-step Policy and Value Iteration. These algorithms iteratively solve short-horizon decision problems and converge to the optimal solution of the original one. By using model-free algorithms as solvers of the short-horizon problems we derive fully model-free algorithms which are instances of the multi-step DP framework. As model-free algorithms are prone to instabilities w.r.t. the decision problem horizon, this simple approach can help in mitigating these instabilities and results in an improved model-free algorithms. We test this approach and show results on both discrete and continuous control problems.
Benchmarking Batch Deep Reinforcement Learning Algorithms
Oct 03, 2019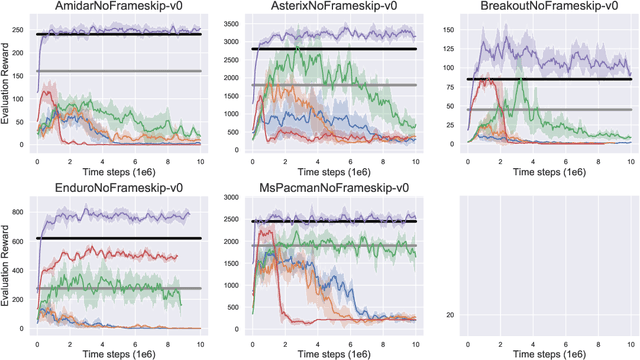
Widely-used deep reinforcement learning algorithms have been shown to fail in the batch setting--learning from a fixed data set without interaction with the environment. Following this result, there have been several papers showing reasonable performances under a variety of environments and batch settings. In this paper, we benchmark the performance of recent off-policy and batch reinforcement learning algorithms under unified settings on the Atari domain, with data generated by a single partially-trained behavioral policy. We find that under these conditions, many of these algorithms underperform DQN trained online with the same amount of data, as well as the partially-trained behavioral policy. To introduce a strong baseline, we adapt the Batch-Constrained Q-learning algorithm to a discrete-action setting, and show it outperforms all existing algorithms at this task.