 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePredictive Coding for Locally-Linear Control
Mar 02, 2020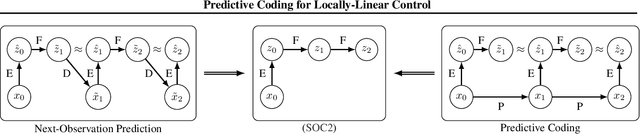
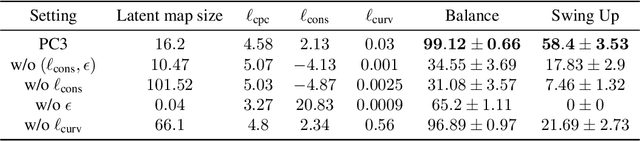


High-dimensional observations and unknown dynamics are major challenges when applying optimal control to many real-world decision making tasks. The Learning Controllable Embedding (LCE) framework addresses these challenges by embedding the observations into a lower dimensional latent space, estimating the latent dynamics, and then performing control directly in the latent space. To ensure the learned latent dynamics are predictive of next-observations, all existing LCE approaches decode back into the observation space and explicitly perform next-observation prediction---a challenging high-dimensional task that furthermore introduces a large number of nuisance parameters (i.e., the decoder) which are discarded during control. In this paper, we propose a novel information-theoretic LCE approach and show theoretically that explicit next-observation prediction can be replaced with predictive coding. We then use predictive coding to develop a decoder-free LCE model whose latent dynamics are amenable to locally-linear control. Extensive experiments on benchmark tasks show that our model reliably learns a controllable latent space that leads to superior performance when compared with state-of-the-art LCE baselines.
Collapsed Amortized Variational Inference for Switching Nonlinear Dynamical Systems
Oct 21, 2019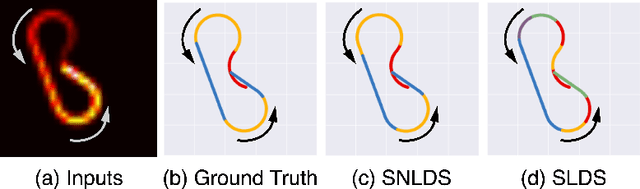

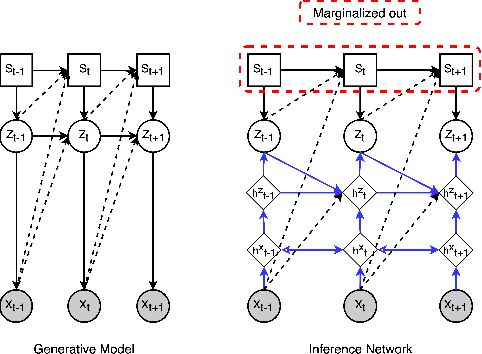

We propose an efficient inference method for switching nonlinear dynamical systems. The key idea is to learn an inference network which can be used as a proposal distribution for the continuous latent variables, while performing exact marginalization of the discrete latent variables. This allows us to use the reparameterization trick, and apply end-to-end training with stochastic gradient descent. We show that the proposed method can successfully segment time series data (including videos) into meaningful "regimes", by using the piece-wise nonlinear dynamics.
Training Variational Autoencoders with Buffered Stochastic Variational Inference
Feb 27, 2019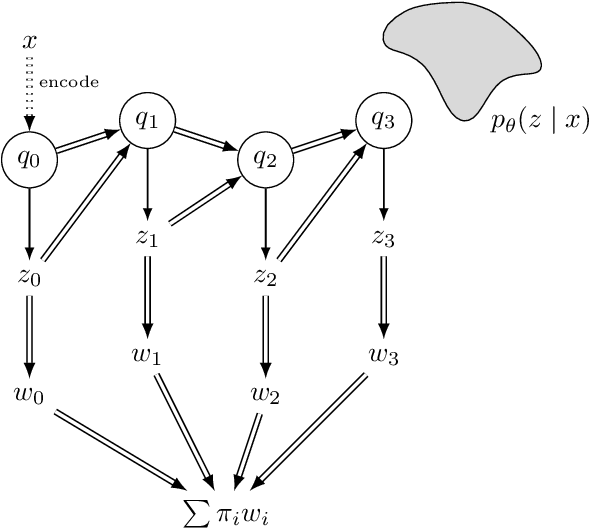
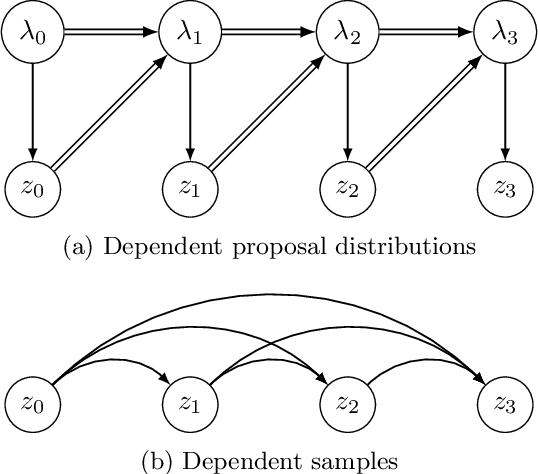
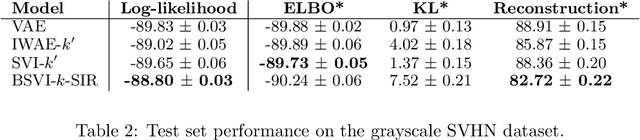
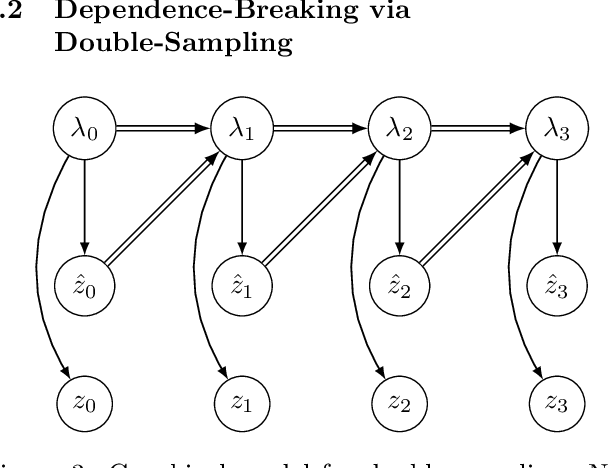
The recognition network in deep latent variable models such as variational autoencoders (VAEs) relies on amortized inference for efficient posterior approximation that can scale up to large datasets. However, this technique has also been demonstrated to select suboptimal variational parameters, often resulting in considerable additional error called the amortization gap. To close the amortization gap and improve the training of the generative model, recent works have introduced an additional refinement step that applies stochastic variational inference (SVI) to improve upon the variational parameters returned by the amortized inference model. In this paper, we propose the Buffered Stochastic Variational Inference (BSVI), a new refinement procedure that makes use of SVI's sequence of intermediate variational proposal distributions and their corresponding importance weights to construct a new generalized importance-weighted lower bound. We demonstrate empirically that training the variational autoencoders with BSVI consistently out-performs SVI, yielding an improved training procedure for VAEs.
Amortized Inference Regularization
May 23, 2018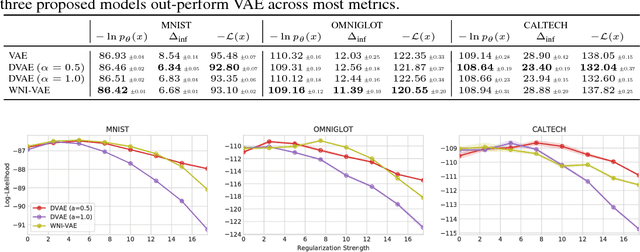

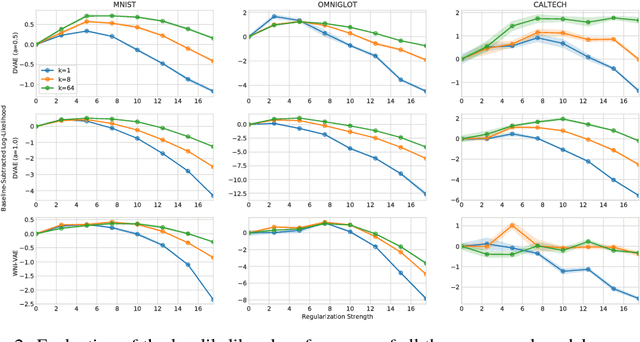

The variational autoencoder (VAE) is a popular model for density estimation and representation learning. Canonically, the variational principle suggests to prefer an expressive inference model so that the variational approximation is accurate. However, it is often overlooked that an overly-expressive inference model can be detrimental to the test set performance of both the amortized posterior approximator and, more importantly, the generative density estimator. In this paper, we leverage the fact that VAEs rely on amortized inference and propose techniques for amortized inference regularization (AIR) that control the smoothness of the inference model. We demonstrate that, by applying AIR, it is possible to improve VAE generalization on both inference and generative performance. Our paper challenges the belief that amortized inference is simply a mechanism for approximating maximum likelihood training and illustrates that regularization of the amortization family provides a new direction for understanding and improving generalization in VAEs.
A DIRT-T Approach to Unsupervised Domain Adaptation
Mar 19, 2018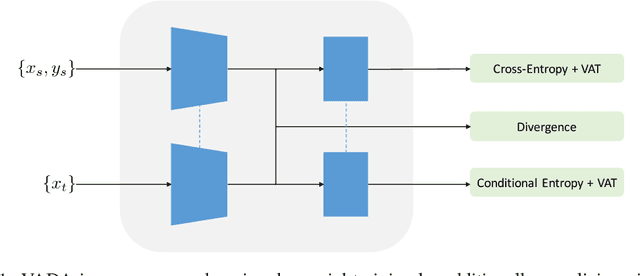
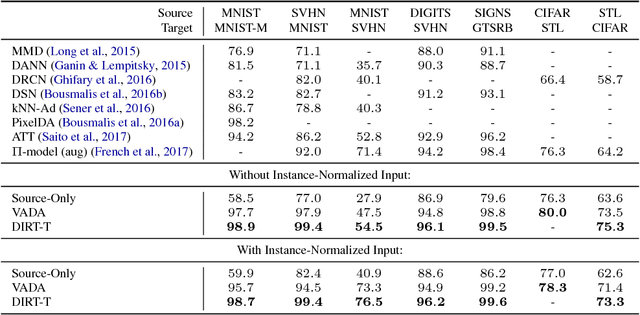
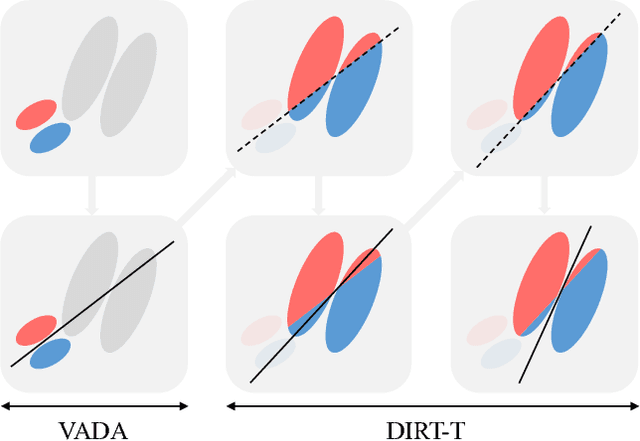

Domain adaptation refers to the problem of leveraging labeled data in a source domain to learn an accurate model in a target domain where labels are scarce or unavailable. A recent approach for finding a common representation of the two domains is via domain adversarial training (Ganin & Lempitsky, 2015), which attempts to induce a feature extractor that matches the source and target feature distributions in some feature space. However, domain adversarial training faces two critical limitations: 1) if the feature extraction function has high-capacity, then feature distribution matching is a weak constraint, 2) in non-conservative domain adaptation (where no single classifier can perform well in both the source and target domains), training the model to do well on the source domain hurts performance on the target domain. In this paper, we address these issues through the lens of the cluster assumption, i.e., decision boundaries should not cross high-density data regions. We propose two novel and related models: 1) the Virtual Adversarial Domain Adaptation (VADA) model, which combines domain adversarial training with a penalty term that punishes the violation the cluster assumption; 2) the Decision-boundary Iterative Refinement Training with a Teacher (DIRT-T) model, which takes the VADA model as initialization and employs natural gradient steps to further minimize the cluster assumption violation. Extensive empirical results demonstrate that the combination of these two models significantly improve the state-of-the-art performance on the digit, traffic sign, and Wi-Fi recognition domain adaptation benchmarks.
Bottleneck Conditional Density Estimation
Jun 30, 2017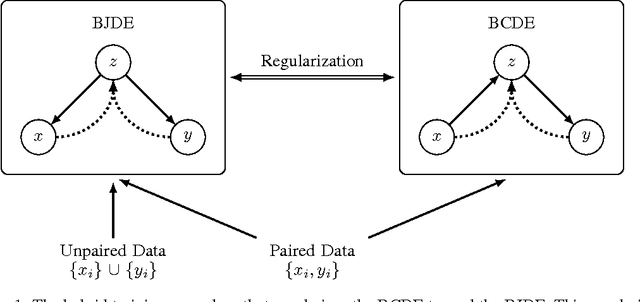
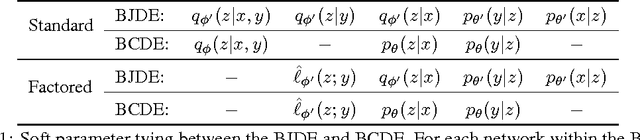
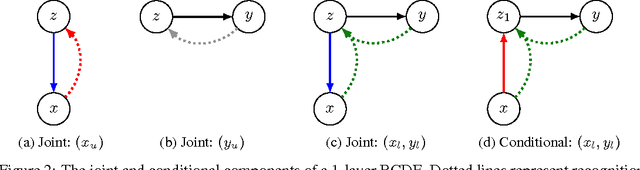
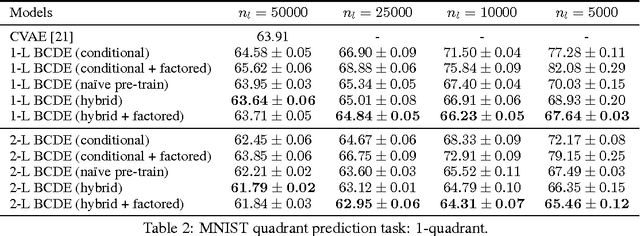
We introduce a new framework for training deep generative models for high-dimensional conditional density estimation. The Bottleneck Conditional Density Estimator (BCDE) is a variant of the conditional variational autoencoder (CVAE) that employs layer(s) of stochastic variables as the bottleneck between the input $x$ and target $y$, where both are high-dimensional. Crucially, we propose a new hybrid training method that blends the conditional generative model with a joint generative model. Hybrid blending is the key to effective training of the BCDE, which avoids overfitting and provides a novel mechanism for leveraging unlabeled data. We show that our hybrid training procedure enables models to achieve competitive results in the MNIST quadrant prediction task in the fully-supervised setting, and sets new benchmarks in the semi-supervised regime for MNIST, SVHN, and CelebA.
Robust Dialog State Tracking for Large Ontologies
May 07, 2016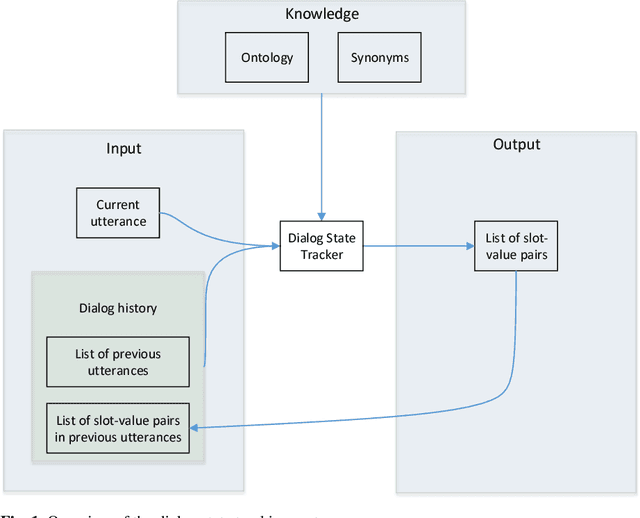
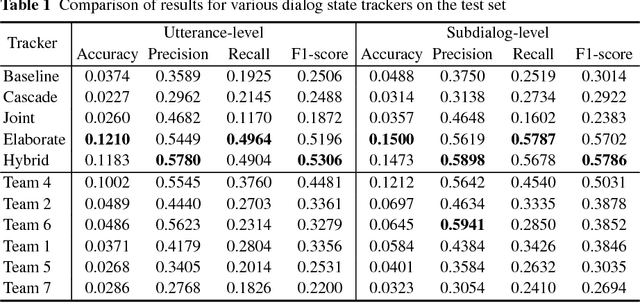
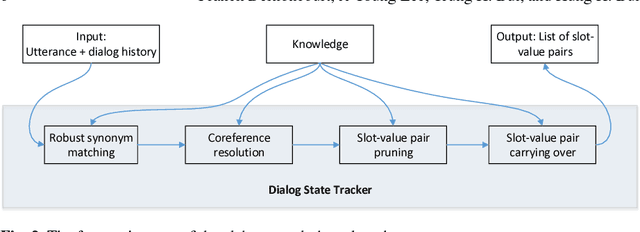
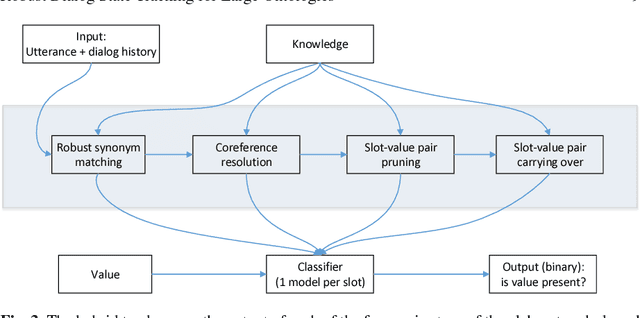
The Dialog State Tracking Challenge 4 (DSTC 4) differentiates itself from the previous three editions as follows: the number of slot-value pairs present in the ontology is much larger, no spoken language understanding output is given, and utterances are labeled at the subdialog level. This paper describes a novel dialog state tracking method designed to work robustly under these conditions, using elaborate string matching, coreference resolution tailored for dialogs and a few other improvements. The method can correctly identify many values that are not explicitly present in the utterance. On the final evaluation, our method came in first among 7 competing teams and 24 entries. The F1-score achieved by our method was 9 and 7 percentage points higher than that of the runner-up for the utterance-level evaluation and for the subdialog-level evaluation, respectively.
Adobe-MIT submission to the DSTC 4 Spoken Language Understanding pilot task
May 07, 2016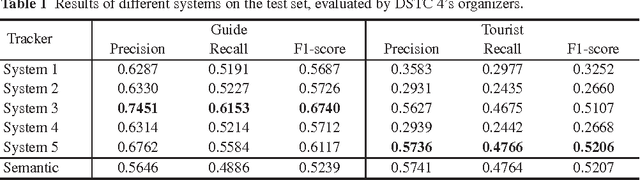
The Dialog State Tracking Challenge 4 (DSTC 4) proposes several pilot tasks. In this paper, we focus on the spoken language understanding pilot task, which consists of tagging a given utterance with speech acts and semantic slots. We compare different classifiers: the best system obtains 0.52 and 0.67 F1-scores on the test set for speech act recognition for the tourist and the guide respectively, and 0.52 F1-score for semantic tagging for both the guide and the tourist.
MCMC for Hierarchical Semi-Markov Conditional Random Fields
Aug 06, 2014
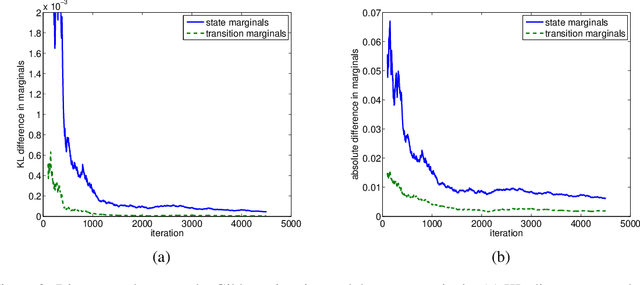
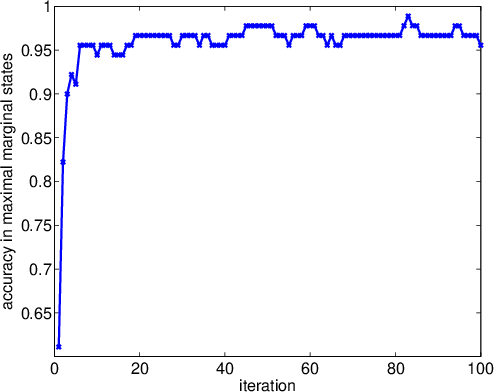
Deep architecture such as hierarchical semi-Markov models is an important class of models for nested sequential data. Current exact inference schemes either cost cubic time in sequence length, or exponential time in model depth. These costs are prohibitive for large-scale problems with arbitrary length and depth. In this contribution, we propose a new approximation technique that may have the potential to achieve sub-cubic time complexity in length and linear time depth, at the cost of some loss of quality. The idea is based on two well-known methods: Gibbs sampling and Rao-Blackwellisation. We provide some simulation-based evaluation of the quality of the RGBS with respect to run time and sequence length.
Hierarchical Semi-Markov Conditional Random Fields for Recursive Sequential Data
Sep 10, 2010
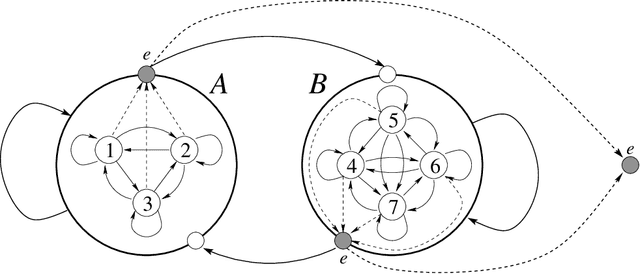
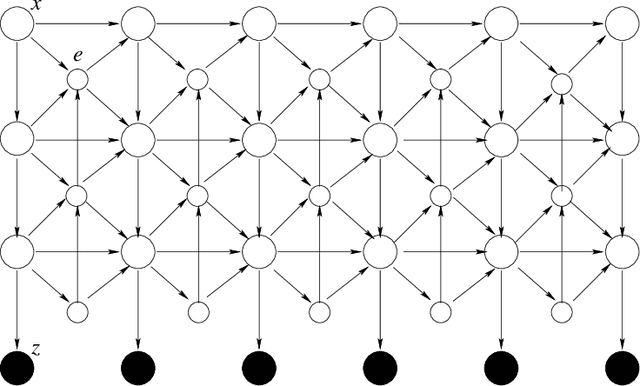
Inspired by the hierarchical hidden Markov models (HHMM), we present the hierarchical semi-Markov conditional random field (HSCRF), a generalisation of embedded undirectedMarkov chains tomodel complex hierarchical, nestedMarkov processes. It is parameterised in a discriminative framework and has polynomial time algorithms for learning and inference. Importantly, we consider partiallysupervised learning and propose algorithms for generalised partially-supervised learning and constrained inference. We demonstrate the HSCRF in two applications: (i) recognising human activities of daily living (ADLs) from indoor surveillance cameras, and (ii) noun-phrase chunking. We show that the HSCRF is capable of learning rich hierarchical models with reasonable accuracy in both fully and partially observed data cases.