 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCalibrated Value-Aware Model Learning with Stochastic Environment Models
May 28, 2025The idea of value-aware model learning, that models should produce accurate value estimates, has gained prominence in model-based reinforcement learning. The MuZero loss, which penalizes a model's value function prediction compared to the ground-truth value function, has been utilized in several prominent empirical works in the literature. However, theoretical investigation into its strengths and weaknesses is limited. In this paper, we analyze the family of value-aware model learning losses, which includes the popular MuZero loss. We show that these losses, as normally used, are uncalibrated surrogate losses, which means that they do not always recover the correct model and value function. Building on this insight, we propose corrections to solve this issue. Furthermore, we investigate the interplay between the loss calibration, latent model architectures, and auxiliary losses that are commonly employed when training MuZero-style agents. We show that while deterministic models can be sufficient to predict accurate values, learning calibrated stochastic models is still advantageous.
$λ$-AC: Learning latent decision-aware models for reinforcement learning in continuous state-spaces
Jun 30, 2023



The idea of decision-aware model learning, that models should be accurate where it matters for decision-making, has gained prominence in model-based reinforcement learning. While promising theoretical results have been established, the empirical performance of algorithms leveraging a decision-aware loss has been lacking, especially in continuous control problems. In this paper, we present a study on the necessary components for decision-aware reinforcement learning models and we showcase design choices that enable well-performing algorithms. To this end, we provide a theoretical and empirical investigation into prominent algorithmic ideas in the field. We highlight that empirical design decisions established in the MuZero line of works are vital to achieving good performance for related algorithms, and we showcase differences in behavior between different instantiations of value-aware algorithms in stochastic environments. Using these insights, we propose the Latent Model-Based Decision-Aware Actor-Critic framework ($\lambda$-AC) for decision-aware model-based reinforcement learning in continuous state-spaces and highlight important design choices in different environments.
Control-Oriented Model-Based Reinforcement Learning with Implicit Differentiation
Jun 06, 2021
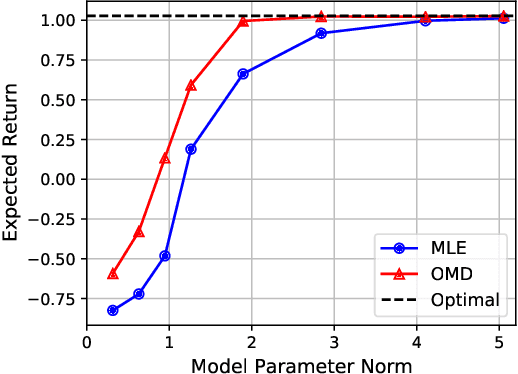
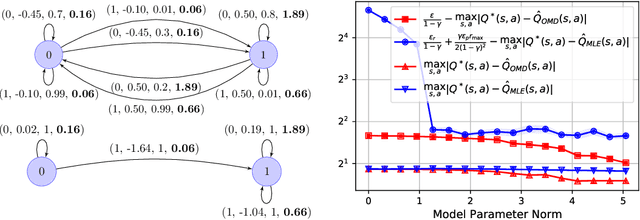
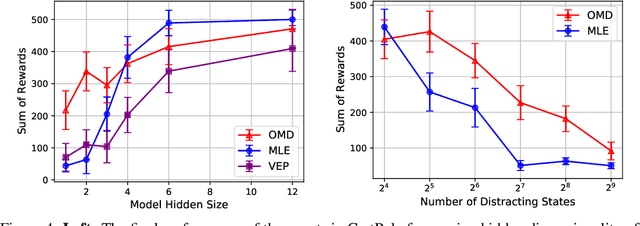
The shortcomings of maximum likelihood estimation in the context of model-based reinforcement learning have been highlighted by an increasing number of papers. When the model class is misspecified or has a limited representational capacity, model parameters with high likelihood might not necessarily result in high performance of the agent on a downstream control task. To alleviate this problem, we propose an end-to-end approach for model learning which directly optimizes the expected returns using implicit differentiation. We treat a value function that satisfies the Bellman optimality operator induced by the model as an implicit function of model parameters and show how to differentiate the function. We provide theoretical and empirical evidence highlighting the benefits of our approach in the model misspecification regime compared to likelihood-based methods.
Policy-Aware Model Learning for Policy Gradient Methods
Feb 28, 2020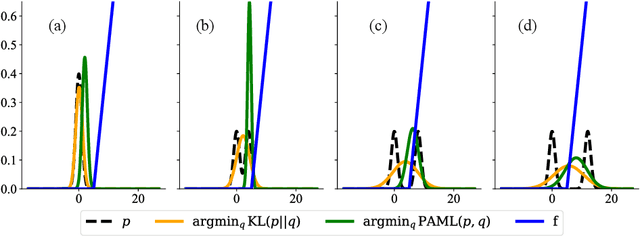
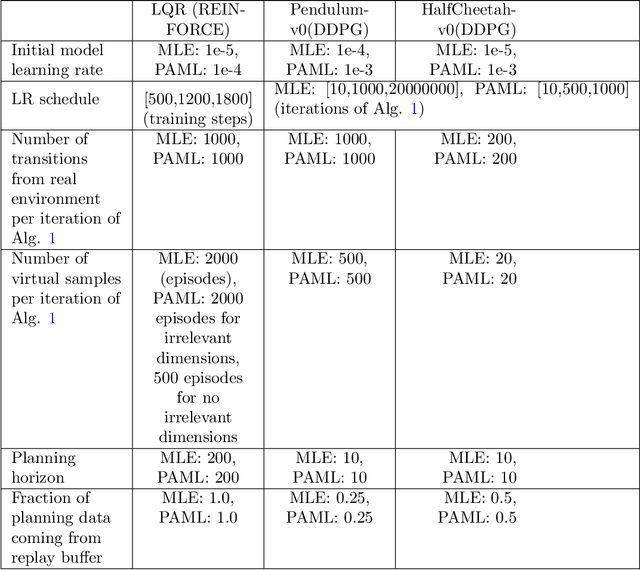
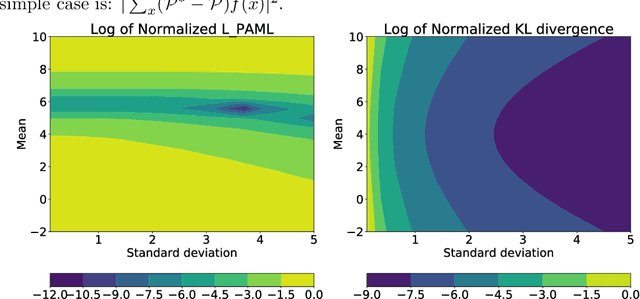
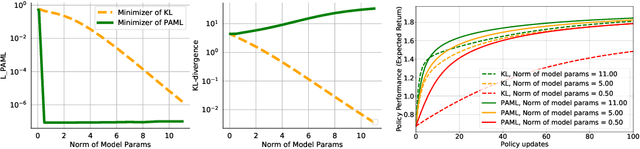
This paper considers the problem of learning a model in model-based reinforcement learning (MBRL). We examine how the planning module of an MBRL algorithm uses the model, and propose that the model learning module should incorporate the way the planner is going to use the model. This is in contrast to conventional model learning approaches, such as those based on maximum likelihood estimate, that learn a predictive model of the environment without explicitly considering the interaction of the model and the planner. We focus on policy gradient type of planning algorithms and derive new loss functions for model learning that incorporate how the planner uses the model. We call this approach Policy-Aware Model Learning (PAML). We theoretically analyze a generic model-based policy gradient algorithm and provide a convergence guarantee for the optimized policy. We also empirically evaluate PAML on some benchmark problems, showing promising results.