 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLM Meets Scene Graph: Can Large Language Models Understand and Generate Scene Graphs? A Benchmark and Empirical Study
May 26, 2025



The remarkable reasoning and generalization capabilities of Large Language Models (LLMs) have paved the way for their expanding applications in embodied AI, robotics, and other real-world tasks. To effectively support these applications, grounding in spatial and temporal understanding in multimodal environments is essential. To this end, recent works have leveraged scene graphs, a structured representation that encodes entities, attributes, and their relationships in a scene. However, a comprehensive evaluation of LLMs' ability to utilize scene graphs remains limited. In this work, we introduce Text-Scene Graph (TSG) Bench, a benchmark designed to systematically assess LLMs' ability to (1) understand scene graphs and (2) generate them from textual narratives. With TSG Bench we evaluate 11 LLMs and reveal that, while models perform well on scene graph understanding, they struggle with scene graph generation, particularly for complex narratives. Our analysis indicates that these models fail to effectively decompose discrete scenes from a complex narrative, leading to a bottleneck when generating scene graphs. These findings underscore the need for improved methodologies in scene graph generation and provide valuable insights for future research. The demonstration of our benchmark is available at https://tsg-bench.netlify.app. Additionally, our code and evaluation data are publicly available at https://anonymous.4open.science/r/TSG-Bench.
Web-Shepherd: Advancing PRMs for Reinforcing Web Agents
May 21, 2025



Web navigation is a unique domain that can automate many repetitive real-life tasks and is challenging as it requires long-horizon sequential decision making beyond typical multimodal large language model (MLLM) tasks. Yet, specialized reward models for web navigation that can be utilized during both training and test-time have been absent until now. Despite the importance of speed and cost-effectiveness, prior works have utilized MLLMs as reward models, which poses significant constraints for real-world deployment. To address this, in this work, we propose the first process reward model (PRM) called Web-Shepherd which could assess web navigation trajectories in a step-level. To achieve this, we first construct the WebPRM Collection, a large-scale dataset with 40K step-level preference pairs and annotated checklists spanning diverse domains and difficulty levels. Next, we also introduce the WebRewardBench, the first meta-evaluation benchmark for evaluating PRMs. In our experiments, we observe that our Web-Shepherd achieves about 30 points better accuracy compared to using GPT-4o on WebRewardBench. Furthermore, when testing on WebArena-lite by using GPT-4o-mini as the policy and Web-Shepherd as the verifier, we achieve 10.9 points better performance, in 10 less cost compared to using GPT-4o-mini as the verifier. Our model, dataset, and code are publicly available at LINK.
YA-TA: Towards Personalized Question-Answering Teaching Assistants using Instructor-Student Dual Retrieval-augmented Knowledge Fusion
Aug 31, 2024



Engagement between instructors and students plays a crucial role in enhancing students'academic performance. However, instructors often struggle to provide timely and personalized support in large classes. To address this challenge, we propose a novel Virtual Teaching Assistant (VTA) named YA-TA, designed to offer responses to students that are grounded in lectures and are easy to understand. To facilitate YA-TA, we introduce the Dual Retrieval-augmented Knowledge Fusion (DRAKE) framework, which incorporates dual retrieval of instructor and student knowledge and knowledge fusion for tailored response generation. Experiments conducted in real-world classroom settings demonstrate that the DRAKE framework excels in aligning responses with knowledge retrieved from both instructor and student sides. Furthermore, we offer additional extensions of YA-TA, such as a Q&A board and self-practice tools to enhance the overall learning experience. Our video is publicly available.
Pearl: A Review-driven Persona-Knowledge Grounded Conversational Recommendation Dataset
Mar 08, 2024



Conversational recommender system is an emerging area that has garnered an increasing interest in the community, especially with the advancements in large language models (LLMs) that enable diverse reasoning over conversational input. Despite the progress, the field has many aspects left to explore. The currently available public datasets for conversational recommendation lack specific user preferences and explanations for recommendations, hindering high-quality recommendations. To address such challenges, we present a novel conversational recommendation dataset named PEARL, synthesized with persona- and knowledge-augmented LLM simulators. We obtain detailed persona and knowledge from real-world reviews and construct a large-scale dataset with over 57k dialogues. Our experimental results demonstrate that utterances in PEARL include more specific user preferences, show expertise in the target domain, and provide recommendations more relevant to the dialogue context than those in prior datasets.
Dialogue Chain-of-Thought Distillation for Commonsense-aware Conversational Agents
Oct 22, 2023



Human-like chatbots necessitate the use of commonsense reasoning in order to effectively comprehend and respond to implicit information present within conversations. Achieving such coherence and informativeness in responses, however, is a non-trivial task. Even for large language models (LLMs), the task of identifying and aggregating key evidence within a single hop presents a substantial challenge. This complexity arises because such evidence is scattered across multiple turns in a conversation, thus necessitating integration over multiple hops. Hence, our focus is to facilitate such multi-hop reasoning over a dialogue context, namely dialogue chain-of-thought (CoT) reasoning. To this end, we propose a knowledge distillation framework that leverages LLMs as unreliable teachers and selectively distills consistent and helpful rationales via alignment filters. We further present DOCTOR, a DialOgue Chain-of-ThOught Reasoner that provides reliable CoT rationales for response generation. We conduct extensive experiments to show that enhancing dialogue agents with high-quality rationales from DOCTOR significantly improves the quality of their responses.
Evidence-empowered Transfer Learning for Alzheimer's Disease
Mar 03, 2023



Transfer learning has been widely utilized to mitigate the data scarcity problem in the field of Alzheimer's disease (AD). Conventional transfer learning relies on re-using models trained on AD-irrelevant tasks such as natural image classification. However, it often leads to negative transfer due to the discrepancy between the non-medical source and target medical domains. To address this, we present evidence-empowered transfer learning for AD diagnosis. Unlike conventional approaches, we leverage an AD-relevant auxiliary task, namely morphological change prediction, without requiring additional MRI data. In this auxiliary task, the diagnosis model learns the evidential and transferable knowledge from morphological features in MRI scans. Experimental results demonstrate that our framework is not only effective in improving detection performance regardless of model capacity, but also more data-efficient and faithful.
TUTORING: Instruction-Grounded Conversational Agent for Language Learners
Feb 24, 2023In this paper, we propose Tutoring bot, a generative chatbot trained on a large scale of tutor-student conversations for English-language learning. To mimic a human tutor's behavior in language education, the tutor bot leverages diverse educational instructions and grounds to each instruction as additional input context for the tutor response generation. As a single instruction generally involves multiple dialogue turns to give the student sufficient speaking practice, the tutor bot is required to monitor and capture when the current instruction should be kept or switched to the next instruction. For that, the tutor bot is learned to not only generate responses but also infer its teaching action and progress on the current conversation simultaneously by a multi-task learning scheme. Our Tutoring bot is deployed under a non-commercial use license at https://tutoringai.com.
Kernel-convoluted Deep Neural Networks with Data Augmentation
Dec 24, 2020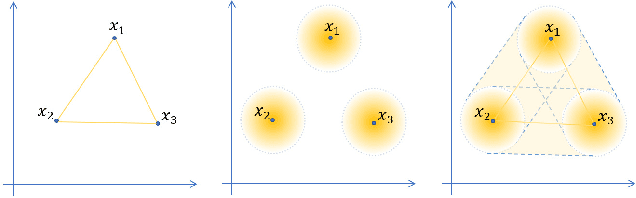

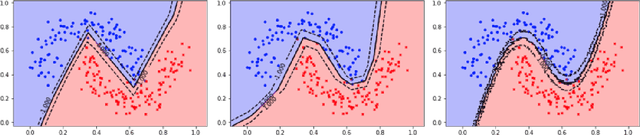
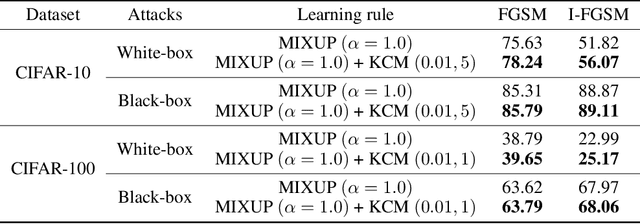
The Mixup method (Zhang et al. 2018), which uses linearly interpolated data, has emerged as an effective data augmentation tool to improve generalization performance and the robustness to adversarial examples. The motivation is to curtail undesirable oscillations by its implicit model constraint to behave linearly at in-between observed data points and promote smoothness. In this work, we formally investigate this premise, propose a way to explicitly impose smoothness constraints, and extend it to incorporate with implicit model constraints. First, we derive a new function class composed of kernel-convoluted models (KCM) where the smoothness constraint is directly imposed by locally averaging the original functions with a kernel function. Second, we propose to incorporate the Mixup method into KCM to expand the domains of smoothness. In both cases of KCM and the KCM adapted with the Mixup, we provide risk analysis, respectively, under some conditions for kernels. We show that the upper bound of the excess risk is not slower than that of the original function class. The upper bound of the KCM with the Mixup remains dominated by that of the KCM if the perturbation of the Mixup vanishes faster than \(O(n^{-1/2})\) where \(n\) is a sample size. Using CIFAR-10 and CIFAR-100 datasets, our experiments demonstrate that the KCM with the Mixup outperforms the Mixup method in terms of generalization and robustness to adversarial examples.