 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCoverage Performance Analysis of FAS-enhanced LoRa Wide Area Networks under both Co-SF and Inter-SF Interference
Jan 28, 2026This paper presents an analytical framework for evaluating the coverage performance of the fluid antenna system (FAS)-enhanced LoRa wide-area networks (LoRaWANs). We investigate the effects of large-scale pathloss in LoRaWAN, small-scale fading characterized by FAS, and dense interference (i.e., collision in an ALOHA-based mechanism) arising from randomly deployed end devices (EDs). Both co-spreading factor (co-SF) interference (with the same SF) and inter-SF interference (with different SFs) are introduced into the network, and their differences in physical characteristics are also considered in the analysis. Additionally, simple yet accurate statistical approximations of the FAS channel envelope and power are derived using the extreme-value theorem. Based on the approximated channel expression, the theoretical coverage probability of the proposed FAS-enhanced LoRaWAN is derived. Numerical results validate our analytical approximations by exhibiting close agreement with the exact correlation model. Notably, it is revealed that a FAS with a normalized aperture of 1 times 1 can greatly enhance network performance, in terms of both ED numbers and coverage range.
Explainer-guided Targeted Adversarial Attacks against Binary Code Similarity Detection Models
Jun 05, 2025Binary code similarity detection (BCSD) serves as a fundamental technique for various software engineering tasks, e.g., vulnerability detection and classification. Attacks against such models have therefore drawn extensive attention, aiming at misleading the models to generate erroneous predictions. Prior works have explored various approaches to generating semantic-preserving variants, i.e., adversarial samples, to evaluate the robustness of the models against adversarial attacks. However, they have mainly relied on heuristic criteria or iterative greedy algorithms to locate salient code influencing the model output, failing to operate on a solid theoretical basis. Moreover, when processing programs with high complexities, such attacks tend to be time-consuming. In this work, we propose a novel optimization for adversarial attacks against BCSD models. In particular, we aim to improve the attacks in a challenging scenario, where the attack goal is to limit the model predictions to a specific range, i.e., the targeted attacks. Our attack leverages the superior capability of black-box, model-agnostic explainers in interpreting the model decision boundaries, thereby pinpointing the critical code snippet to apply semantic-preserving perturbations. The evaluation results demonstrate that compared with the state-of-the-art attacks, the proposed attacks achieve higher attack success rate in almost all scenarios, while also improving the efficiency and transferability. Our real-world case studies on vulnerability detection and classification further demonstrate the security implications of our attacks, highlighting the urgent need to further enhance the robustness of existing BCSD models.
On Performance of LoRa Fluid Antenna Systems
Feb 21, 2025This paper advocates a fluid antenna system (FAS) assisting long-range communication (LoRa-FAS) for Internet-of-Things (IoT) applications. Our focus is on pilot sequence overhead and placement for FAS. Specifically, we consider embedding pilot sequences within symbols to reduce the equivalent symbol error rate (SER), leveraging the fact that the pilot sequences do not convey source information and correlation detection at the LoRa receiver needs not be performed across the entire symbol. We obtain closed-form approximations for the probability density function (PDF) and cumulative distribution function (CDF) of the FAS channel, assuming perfect channel state information (CSI). Moreover, the approximate SER, hence the bit error rate (BER), of the proposed LoRa-FAS is derived. Simulation results indicate that substantial SER gains can be achieved by FAS within the LoRa framework, even with a limited size of FAS. Furthermore, our analytical results align well with that of the Clarke's exact spatial correlation model. Finally, the correlation factor for the block correlation model should be selected as the proportion of the exact correlation matrix's eigenvalues greater than $1$.
EmoBox: Multilingual Multi-corpus Speech Emotion Recognition Toolkit and Benchmark
Jun 11, 2024Speech emotion recognition (SER) is an important part of human-computer interaction, receiving extensive attention from both industry and academia. However, the current research field of SER has long suffered from the following problems: 1) There are few reasonable and universal splits of the datasets, making comparing different models and methods difficult. 2) No commonly used benchmark covers numerous corpus and languages for researchers to refer to, making reproduction a burden. In this paper, we propose EmoBox, an out-of-the-box multilingual multi-corpus speech emotion recognition toolkit, along with a benchmark for both intra-corpus and cross-corpus settings. For intra-corpus settings, we carefully designed the data partitioning for different datasets. For cross-corpus settings, we employ a foundation SER model, emotion2vec, to mitigate annotation errors and obtain a test set that is fully balanced in speakers and emotions distributions. Based on EmoBox, we present the intra-corpus SER results of 10 pre-trained speech models on 32 emotion datasets with 14 languages, and the cross-corpus SER results on 4 datasets with the fully balanced test sets. To the best of our knowledge, this is the largest SER benchmark, across language scopes and quantity scales. We hope that our toolkit and benchmark can facilitate the research of SER in the community.
1st Place Solution to Odyssey Emotion Recognition Challenge Task1: Tackling Class Imbalance Problem
May 30, 2024



Speech emotion recognition is a challenging classification task with natural emotional speech, especially when the distribution of emotion types is imbalanced in the training and test data. In this case, it is more difficult for a model to learn to separate minority classes, resulting in those sometimes being ignored or frequently misclassified. Previous work has utilised class weighted loss for training, but problems remain as it sometimes causes over-fitting for minor classes or under-fitting for major classes. This paper presents the system developed by a multi-site team for the participation in the Odyssey 2024 Emotion Recognition Challenge Track-1. The challenge data has the aforementioned properties and therefore the presented systems aimed to tackle these issues, by introducing focal loss in optimisation when applying class weighted loss. Specifically, the focal loss is further weighted by prior-based class weights. Experimental results show that combining these two approaches brings better overall performance, by sacrificing performance on major classes. The system further employs a majority voting strategy to combine the outputs of an ensemble of 7 models. The models are trained independently, using different acoustic features and loss functions - with the aim to have different properties for different data. Hence these models show different performance preferences on major classes and minor classes. The ensemble system output obtained the best performance in the challenge, ranking top-1 among 68 submissions. It also outperformed all single models in our set. On the Odyssey 2024 Emotion Recognition Challenge Task-1 data the system obtained a Macro-F1 score of 35.69% and an accuracy of 37.32%.
Automatic Speech Recognition System-Independent Word Error Rate Estimation
Apr 26, 2024



Word error rate (WER) is a metric used to evaluate the quality of transcriptions produced by Automatic Speech Recognition (ASR) systems. In many applications, it is of interest to estimate WER given a pair of a speech utterance and a transcript. Previous work on WER estimation focused on building models that are trained with a specific ASR system in mind (referred to as ASR system-dependent). These are also domain-dependent and inflexible in real-world applications. In this paper, a hypothesis generation method for ASR System-Independent WER estimation (SIWE) is proposed. In contrast to prior work, the WER estimators are trained using data that simulates ASR system output. Hypotheses are generated using phonetically similar or linguistically more likely alternative words. In WER estimation experiments, the proposed method reaches a similar performance to ASR system-dependent WER estimators on in-domain data and achieves state-of-the-art performance on out-of-domain data. On the out-of-domain data, the SIWE model outperformed the baseline estimators in root mean square error and Pearson correlation coefficient by relative 17.58% and 18.21%, respectively, on Switchboard and CALLHOME. The performance was further improved when the WER of the training set was close to the WER of the evaluation dataset.
Fast Word Error Rate Estimation Using Self-Supervised Representations For Speech And Text
Oct 12, 2023The quality of automatic speech recognition (ASR) is typically measured by word error rate (WER). WER estimation is a task aiming to predict the WER of an ASR system, given a speech utterance and a transcription. This task has gained increasing attention while advanced ASR systems are trained on large amounts of data. In this case, WER estimation becomes necessary in many scenarios, for example, selecting training data with unknown transcription quality or estimating the testing performance of an ASR system without ground truth transcriptions. Facing large amounts of data, the computation efficiency of a WER estimator becomes essential in practical applications. However, previous works usually did not consider it as a priority. In this paper, a Fast WER estimator (Fe-WER) using self-supervised learning representation (SSLR) is introduced. The estimator is built upon SSLR aggregated by average pooling. The results show that Fe-WER outperformed the e-WER3 baseline relatively by 19.69% and 7.16% on Ted-Lium3 in both evaluation metrics of root mean square error and Pearson correlation coefficient, respectively. Moreover, the estimation weighted by duration was 10.43% when the target was 10.88%. Lastly, the inference speed was about 4x in terms of a real-time factor.
SALSA: Attacking Lattice Cryptography with Transformers
Jul 11, 2022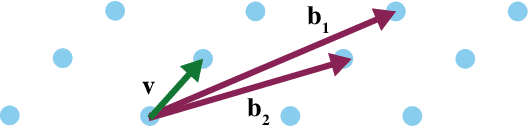
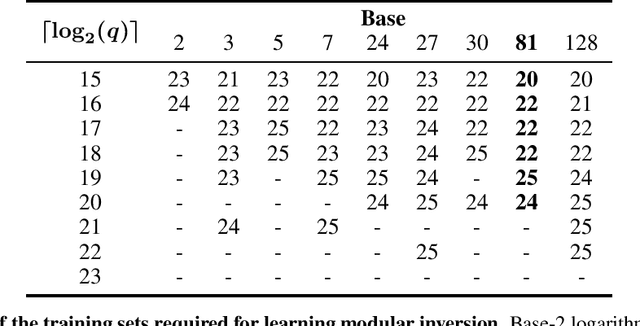
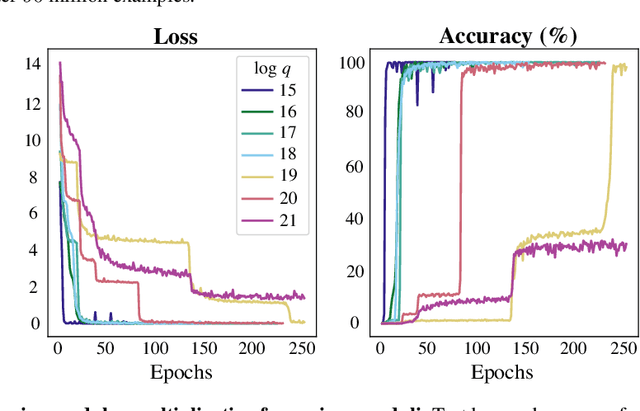
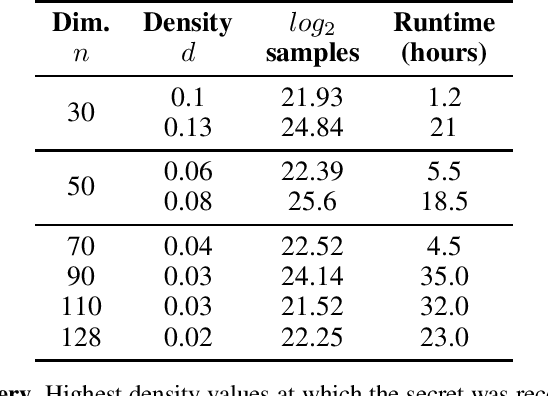
Currently deployed public-key cryptosystems will be vulnerable to attacks by full-scale quantum computers. Consequently, "quantum resistant" cryptosystems are in high demand, and lattice-based cryptosystems, based on a hard problem known as Learning With Errors (LWE), have emerged as strong contenders for standardization. In this work, we train transformers to perform modular arithmetic and combine half-trained models with statistical cryptanalysis techniques to propose SALSA: a machine learning attack on LWE-based cryptographic schemes. SALSA can fully recover secrets for small-to-mid size LWE instances with sparse binary secrets, and may scale to attack real-world LWE-based cryptosystems.
Efficient Non-Autoregressive GAN Voice Conversion using VQWav2vec Features and Dynamic Convolution
Mar 31, 2022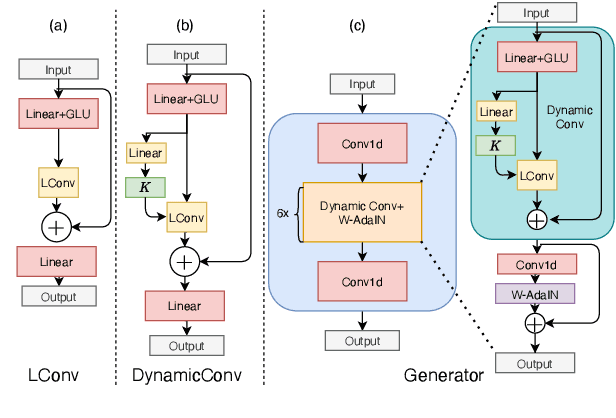
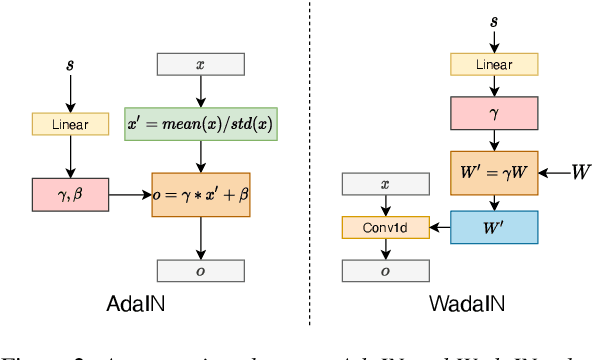
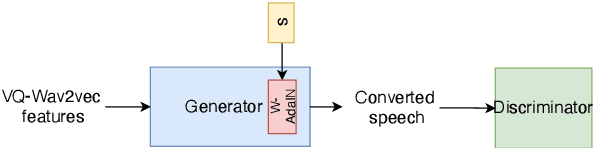

It was shown recently that a combination of ASR and TTS models yield highly competitive performance on standard voice conversion tasks such as the Voice Conversion Challenge 2020 (VCC2020). To obtain good performance both models require pretraining on large amounts of data, thereby obtaining large models that are potentially inefficient in use. In this work we present a model that is significantly smaller and thereby faster in processing while obtaining equivalent performance. To achieve this the proposed model, Dynamic-GAN-VC (DYGAN-VC), uses a non-autoregressive structure and makes use of vector quantised embeddings obtained from a VQWav2vec model. Furthermore dynamic convolution is introduced to improve speech content modeling while requiring a small number of parameters. Objective and subjective evaluation was performed using the VCC2020 task, yielding MOS scores of up to 3.86, and character error rates as low as 4.3\%. This was achieved with approximately half the number of model parameters, and up to 8 times faster decoding speed.
T-vectors: Weakly Supervised Speaker Identification Using Hierarchical Transformer Model
Oct 29, 2020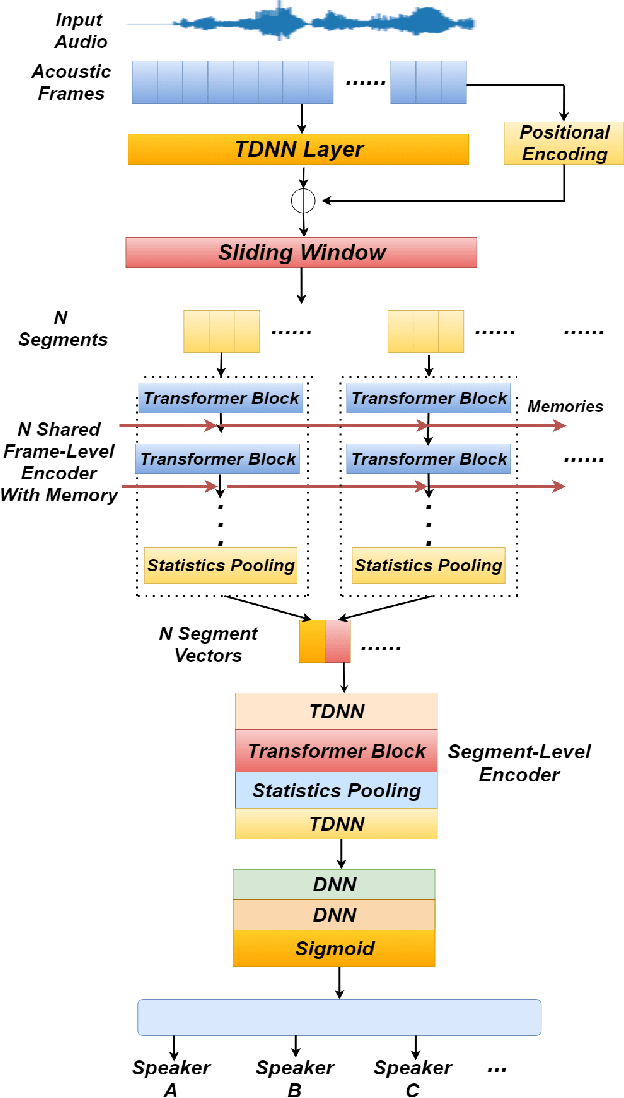
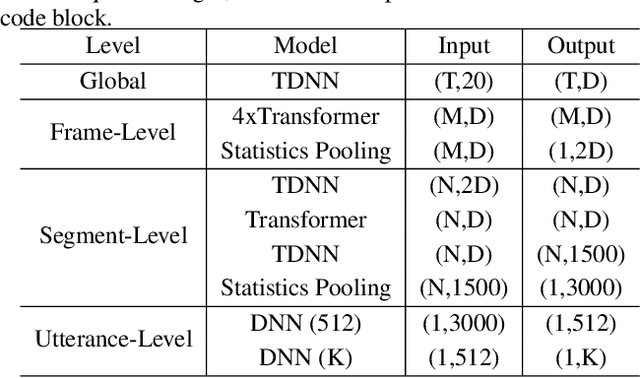
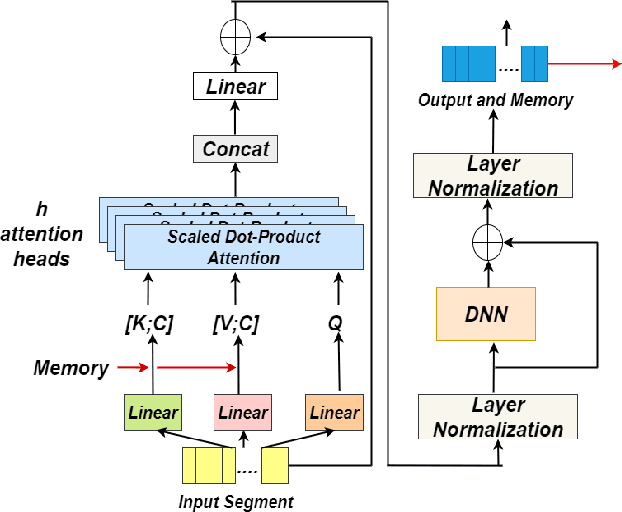
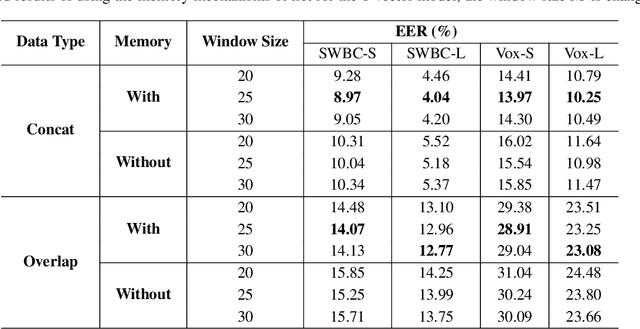
Identifying multiple speakers without knowing where a speaker's voice is in a recording is a challenging task. This paper proposes a hierarchical network with transformer encoders and memory mechanism to address this problem. The proposed model contains a frame-level encoder and segment-level encoder, both of them make use of the transformer encoder block. The multi-head attention mechanism in the transformer structure could better capture different speaker properties when the input utterance contains multiple speakers. The memory mechanism used in the frame-level encoders can build a recurrent connection that better capture long-term speaker features. The experiments are conducted on artificial datasets based on the Switchboard Cellular part1 (SWBC) and Voxceleb1 datasets. In different data construction scenarios (Concat and Overlap), the proposed model shows better performance comparaing with four strong baselines, reaching 13.3% and 10.5% relative improvement compared with H-vectors and S-vectors. The use of memory mechanism could reach 10.6% and 7.7% relative improvement compared with not using memory mechanism.