 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIdentifying AI Web Scrapers Using Canary Tokens
May 13, 2026From pre-training to query-time augmentation, web-scraped data helps to improve the quality and contextual relevancy of content generated by large language models (LLMs). However, large-scale web scraping to feed LLMs can affect site stability and raise legal, privacy, or ethics concerns. If website owners wish to limit LLM-related web scraping on their site, due to these or other concerns, they may turn to scraper access control mechanisms like the Robots Exclusion Protocol. To be most effective, such mechanisms require site owners to first identify the scrapers that they wish to restrict (e.g., via User-Agent strings). Existing mechanisms to identify LLM-related scrapers rely on voluntary disclosure by companies, one-off experiments by researchers, or crowd-sourced reports -- methods that are neither reliable nor scalable. This paper proposes a novel technique for accurately and automatically inferring LLM-related scrapers. We host dynamic websites that serve unique canary tokens to each visiting scraper, then prompt LLMs for information about our sites. If an LLM consistently generates outputs containing tokens unique to a scraper, it provides evidence of exposure to that scraper. Via experiments across 22 production LLM systems, we demonstrate that our approach can reliably identify which scrapers feed which LLM, including several that are not publicly known or disclosed by the companies. Our approach provides a promising avenue for unprivileged third parties to infer which scrapers serve data to which LLMs, potentially enabling better control over unwanted scraping.
Improving ML Attacks on LWE with Data Repetition and Stepwise Regression
Apr 05, 2026The Learning with Errors (LWE) problem is a hard math problem in lattice-based cryptography. In the simplest case of binary secrets, it is the subset sum problem, with error. Effective ML attacks on LWE were demonstrated in the case of binary, ternary, and small secrets, succeeding on fairly sparse secrets. The ML attacks recover secrets with up to 3 active bits in the "cruel region" (Nolte et al., 2024) on samples pre-processed with BKZ. We show that using larger training sets and repeated examples enables recovery of denser secrets. Empirically, we observe a power-law relationship between model-based attempts to recover the secrets, dataset size, and repeated examples. We introduce a stepwise regression technique to recover the "cool bits" of the secret.
What happens when generative AI models train recursively on each others' generated outputs?
May 27, 2025The internet is full of AI-generated content while also serving as a common source of training data for generative AI (genAI) models. This duality raises the possibility that future genAI models may be trained on other models' generated outputs. Prior work has studied consequences of models training on their own generated outputs, but limited work has considered what happens if models ingest content produced by other models. Given society's increasing dependence on genAI tools, understanding downstream effects of such data-mediated model interactions is critical. To this end, we provide empirical evidence for how data-mediated interactions might unfold in practice, develop a theoretical model for this interactive training process, and show experimentally possible long-term results of such interactions. We find that data-mediated interactions can benefit models by exposing them to novel concepts perhaps missed in original training data, but also can homogenize their performance on shared tasks.
Exploring Causes of Representational Similarity in Machine Learning Models
May 20, 2025



Numerous works have noted significant similarities in how machine learning models represent the world, even across modalities. Although much effort has been devoted to uncovering properties and metrics on which these models align, surprisingly little work has explored causes of this similarity. To advance this line of inquiry, this work explores how two possible causal factors -- dataset overlap and task overlap -- influence downstream model similarity. The exploration of dataset overlap is motivated by the reality that large-scale generative AI models are often trained on overlapping datasets of scraped internet data, while the exploration of task overlap seeks to substantiate claims from a recent work, the Platonic Representation Hypothesis, that task similarity may drive model similarity. We evaluate the effects of both factors through a broad set of experiments. We find that both positively correlate with higher representational similarity and that combining them provides the strongest effect. Our code and dataset are published.
We're Different, We're the Same: Creative Homogeneity Across LLMs
Jan 31, 2025Numerous powerful large language models (LLMs) are now available for use as writing support tools, idea generators, and beyond. Although these LLMs are marketed as helpful creative assistants, several works have shown that using an LLM as a creative partner results in a narrower set of creative outputs. However, these studies only consider the effects of interacting with a single LLM, begging the question of whether such narrowed creativity stems from using a particular LLM -- which arguably has a limited range of outputs -- or from using LLMs in general as creative assistants. To study this question, we elicit creative responses from humans and a broad set of LLMs using standardized creativity tests and compare the population-level diversity of responses. We find that LLM responses are much more similar to other LLM responses than human responses are to each other, even after controlling for response structure and other key variables. This finding of significant homogeneity in creative outputs across the LLMs we evaluate adds a new dimension to the ongoing conversation about creativity and LLMs. If today's LLMs behave similarly, using them as a creative partners -- regardless of the model used -- may drive all users towards a limited set of "creative" outputs.
Teaching Transformers Modular Arithmetic at Scale
Oct 04, 2024



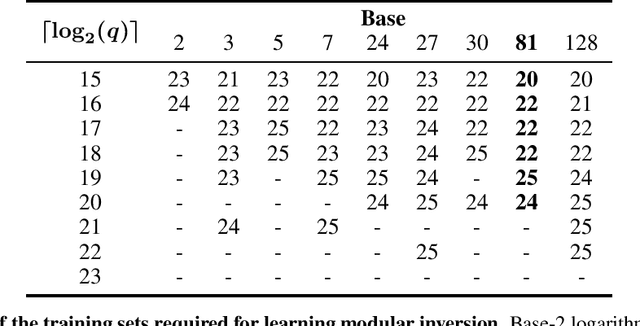
Modular addition is, on its face, a simple operation: given $N$ elements in $\mathbb{Z}_q$, compute their sum modulo $q$. Yet, scalable machine learning solutions to this problem remain elusive: prior work trains ML models that sum $N \le 6$ elements mod $q \le 1000$. Promising applications of ML models for cryptanalysis-which often involve modular arithmetic with large $N$ and $q$-motivate reconsideration of this problem. This work proposes three changes to the modular addition model training pipeline: more diverse training data, an angular embedding, and a custom loss function. With these changes, we demonstrate success with our approach for $N = 256, q = 3329$, a case which is interesting for cryptographic applications, and a significant increase in $N$ and $q$ over prior work. These techniques also generalize to other modular arithmetic problems, motivating future work.
Salsa Fresca: Angular Embeddings and Pre-Training for ML Attacks on Learning With Errors
Feb 02, 2024



Learning with Errors (LWE) is a hard math problem underlying recently standardized post-quantum cryptography (PQC) systems for key exchange and digital signatures. Prior work proposed new machine learning (ML)-based attacks on LWE problems with small, sparse secrets, but these attacks require millions of LWE samples to train on and take days to recover secrets. We propose three key methods -- better preprocessing, angular embeddings and model pre-training -- to improve these attacks, speeding up preprocessing by $25\times$ and improving model sample efficiency by $10\times$. We demonstrate for the first time that pre-training improves and reduces the cost of ML attacks on LWE. Our architecture improvements enable scaling to larger-dimension LWE problems: this work is the first instance of ML attacks recovering sparse binary secrets in dimension $n=1024$, the smallest dimension used in practice for homomorphic encryption applications of LWE where sparse binary secrets are proposed.
SALSA PICANTE: a machine learning attack on LWE with binary secrets
Mar 07, 2023



The Learning With Errors (LWE) problem is one of the major hard problems in post-quantum cryptography. For example, 1) the only Key Exchange Mechanism KEM standardized by NIST [14] is based on LWE; and 2) current publicly available Homomorphic Encryption (HE) libraries are based on LWE. NIST KEM schemes use random secrets, but homomorphic encryption schemes use binary or ternary secrets, for efficiency reasons. In particular, sparse binary secrets have been proposed, but not standardized [2], for HE. Prior work SALSA [49] demonstrated a new machine learning attack on sparse binary secrets for the LWE problem in small dimensions (up to n = 128) and low Hamming weights (up to h = 4). However, this attack assumed access to millions of LWE samples, and was not scaled to higher Hamming weights or dimensions. Our attack, PICANTE, reduces the number of samples required to just m = 4n samples. Moreover, it can recover secrets with much larger dimensions (up to 350) and Hamming weights (roughly n/10, or h = 33 for n = 300). To achieve this, we introduce a preprocessing step which allows us to generate the training data from a linear number of samples and changes the distribution of the training data to improve transformer training. We also improve the distinguisher/secret recovery methods of SALSA and introduce a novel cross-attention recovery mechanism which allows us to read-off the secret directly from the trained models.
Data Isotopes for Data Provenance in DNNs
Aug 29, 2022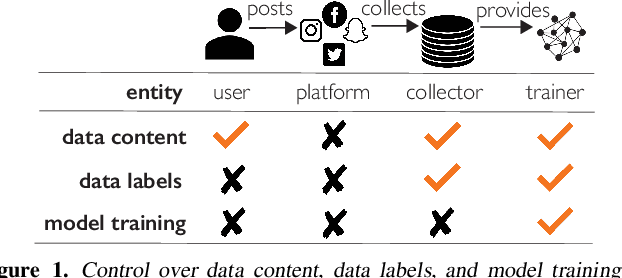

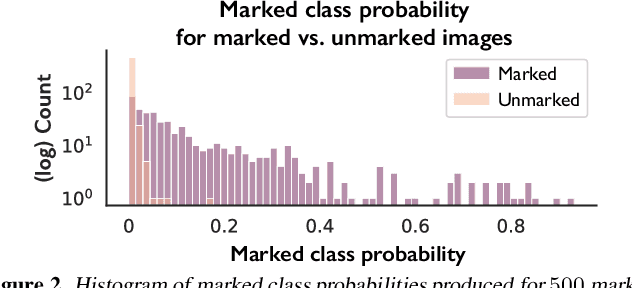

Today, creators of data-hungry deep neural networks (DNNs) scour the Internet for training fodder, leaving users with little control over or knowledge of when their data is appropriated for model training. To empower users to counteract unwanted data use, we design, implement and evaluate a practical system that enables users to detect if their data was used to train an DNN model. We show how users can create special data points we call isotopes, which introduce "spurious features" into DNNs during training. With only query access to a trained model and no knowledge of the model training process, or control of the data labels, a user can apply statistical hypothesis testing to detect if a model has learned the spurious features associated with their isotopes by training on the user's data. This effectively turns DNNs' vulnerability to memorization and spurious correlations into a tool for data provenance. Our results confirm efficacy in multiple settings, detecting and distinguishing between hundreds of isotopes with high accuracy. We further show that our system works on public ML-as-a-service platforms and larger models such as ImageNet, can use physical objects instead of digital marks, and remains generally robust against several adaptive countermeasures.
SALSA: Attacking Lattice Cryptography with Transformers
Jul 11, 2022
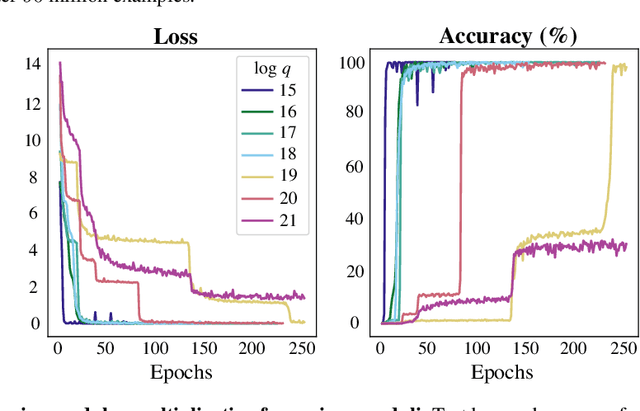
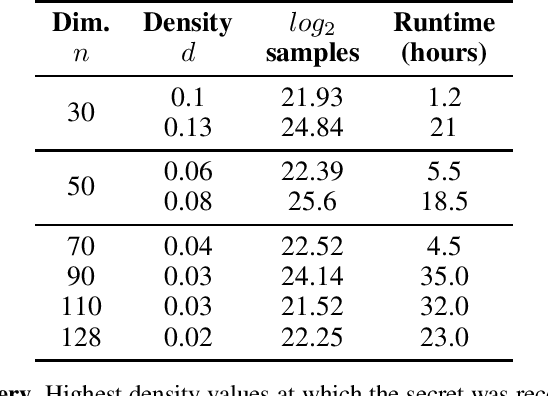
Currently deployed public-key cryptosystems will be vulnerable to attacks by full-scale quantum computers. Consequently, "quantum resistant" cryptosystems are in high demand, and lattice-based cryptosystems, based on a hard problem known as Learning With Errors (LWE), have emerged as strong contenders for standardization. In this work, we train transformers to perform modular arithmetic and combine half-trained models with statistical cryptanalysis techniques to propose SALSA: a machine learning attack on LWE-based cryptographic schemes. SALSA can fully recover secrets for small-to-mid size LWE instances with sparse binary secrets, and may scale to attack real-world LWE-based cryptosystems.