 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTACO: Towards Task-Consistent Open-Vocabulary Adaptation in Video Recognition
Jun 24, 2026Adapting CLIP for open-vocabulary video recognition necessitates a delicate balance between newly acquired video knowledge and the pretrained generalization. While existing studies pursue this generalization-specialization trade-off with additional regularizations or constraints, we argue that they overlook the deviation of representations beyond the fine-tuning data distribution, resulting in suboptimal adaptation effects. We believe such deviation is inherited from the inconsistency between the fine-tuning and evaluation objectives, where model optimization is restricted to the known training distribution but evaluated on unseen ones. In this paper, we introduce \emph{TACO}, a simple yet effective framework to mitigate the potential negative effects induced by this inconsistency. Our key insight is that adaptation should preserve OOD-relevant alignment beyond the training distribution. To this end, we propose \emph{Relative Structure Distillation}, which regularizes the relative geometry of the representation space and suppresses harmful alignment shift during training. We further decouple the representation space from the optimization space with a lightweight specialization projection, allowing task-specific adaptation without directly overspecializing the representations used at test time. \emph{TACO} establishes state-of-the-art performance on diverse benchmarks under cross-dataset and base-to-novel settings. Code will be released at https://github.com/ZMHH-H/TACO.
Agentopia: Long-Term Life Simulation and Learning in Agent Societies
Jun 05, 2026Humans learn from social life. Simulating this process with LLM-powered agents represents a promising research direction, raising a natural question: whether LLMs can learn from such simulated social experience to better understand and replicate human behavior. However, prior agent society simulations typically operate at the scale of days, limiting the depth of social interactions and long-term growth. In this paper, we study long-term life simulation and LLM learning in agent societies, with two goals: (1) investigating social behaviors that emerge from life-long simulation, and (2) developing anthropomorphic capabilities in LLMs, particularly intelligence in social life, through years of simulated social experience. Specifically, we present Agentopia, a comprehensive framework for long-term life simulation in multi-agent societies, where 100 agents autonomously pursue personal growth, develop social relationships, and fulfill their needs and goals over 10 simulated years. We define life reward to mirror human well-being, and leverage this reward to train LLMs via rejection sampling. Extensive experiments show that agents exhibit rich emergent social behaviors. Furthermore, life reward training effectively enhances the underlying LLM, which leads to improved agent well-being in simulation, and generalizes to downstream role-playing benchmarks with +15.6% improvement.
Beyond Semantic Manipulation: Token-Space Attacks on Reward Models
Apr 03, 2026Reward models (RMs) are widely used as optimization targets in reinforcement learning from human feedback (RLHF), yet they remain vulnerable to reward hacking. Existing attacks mainly operate within the semantic space, constructing human-readable adversarial outputs that exploit RM biases. In this work, we introduce a fundamentally different paradigm: Token Mapping Perturbation Attack (TOMPA), a framework that performs adversarial optimization directly in token space. By bypassing the standard decode-re-tokenize interface between the policy and the reward model, TOMPA enables the attack policy to optimize over raw token sequences rather than coherent natural language. Using only black-box scalar feedback, TOMPA automatically discovers non-linguistic token patterns that elicit extremely high rewards across multiple state-of-the-art RMs. Specifically, when targeting Skywork-Reward-V2-Llama-3.1-8B, TOMPA nearly doubles the reward of GPT-5 reference answers and outperforms them on 98.0% of prompts. Despite these high scores, the generated outputs degenerate into nonsensical text, revealing that RMs can be systematically exploited beyond the semantic regime and exposing a critical vulnerability in current RLHF pipelines.
GroundVTS: Visual Token Sampling in Multimodal Large Language Models for Video Temporal Grounding
Apr 02, 2026Video temporal grounding (VTG) is a critical task in video understanding and a key capability for extending video large language models (Vid-LLMs) to broader applications. However, existing Vid-LLMs rely on uniform frame sampling to extract video information, resulting in a sparse distribution of key frames and the loss of crucial temporal cues. To address this limitation, we propose Grounded Visual Token Sampling (GroundVTS), a Vid-LLM architecture that focuses on the most informative temporal segments. GroundVTS employs a fine-grained, query-guided mechanism to filter visual tokens before feeding them into the LLM, thereby preserving essential spatio-temporal information and maintaining temporal coherence. Futhermore, we introduce a progressive optimization strategy that enables the LLM to effectively adapt to the non-uniform distribution of visual features, enhancing its ability to model temporal dependencies and achieve precise video localization. We comprehensively evaluate GroundVTS on three standard VTG benchmarks, where it outperforms existing methods, achieving a 7.7-point improvement in mIoU for moment retrieval and 12.0-point improvement in mAP for highlight detection. Code is available at https://github.com/Florence365/GroundVTS.
RynnBrain: Open Embodied Foundation Models
Feb 13, 2026Despite rapid progress in multimodal foundation models, embodied intelligence community still lacks a unified, physically grounded foundation model that integrates perception, reasoning, and planning within real-world spatial-temporal dynamics. We introduce RynnBrain, an open-source spatiotemporal foundation model for embodied intelligence. RynnBrain strengthens four core capabilities in a unified framework: comprehensive egocentric understanding, diverse spatiotemporal localization, physically grounded reasoning, and physics-aware planning. The RynnBrain family comprises three foundation model scales (2B, 8B, and 30B-A3B MoE) and four post-trained variants tailored for downstream embodied tasks (i.e., RynnBrain-Nav, RynnBrain-Plan, and RynnBrain-VLA) or complex spatial reasoning tasks (i.e., RynnBrain-CoP). In terms of extensive evaluations on 20 embodied benchmarks and 8 general vision understanding benchmarks, our RynnBrain foundation models largely outperform existing embodied foundation models by a significant margin. The post-trained model suite further substantiates two key potentials of the RynnBrain foundation model: (i) enabling physically grounded reasoning and planning, and (ii) serving as a strong pretrained backbone that can be efficiently adapted to diverse embodied tasks.
SignRAG: A Retrieval-Augmented System for Scalable Zero-Shot Road Sign Recognition
Dec 14, 2025

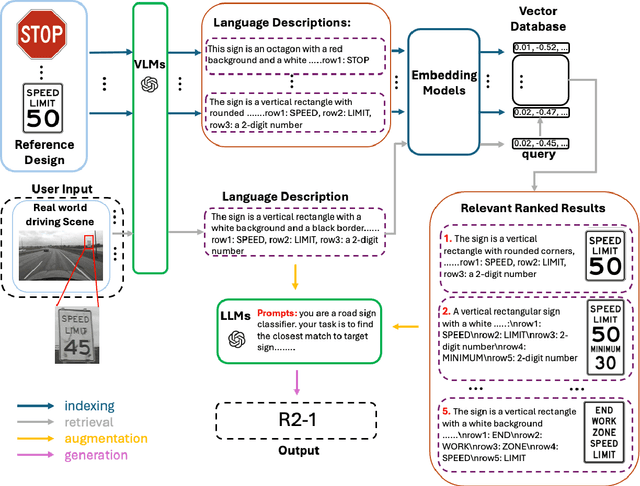

Automated road sign recognition is a critical task for intelligent transportation systems, but traditional deep learning methods struggle with the sheer number of sign classes and the impracticality of creating exhaustive labeled datasets. This paper introduces a novel zero-shot recognition framework that adapts the Retrieval-Augmented Generation (RAG) paradigm to address this challenge. Our method first uses a Vision Language Model (VLM) to generate a textual description of a sign from an input image. This description is used to retrieve a small set of the most relevant sign candidates from a vector database of reference designs. Subsequently, a Large Language Model (LLM) reasons over the retrieved candidates to make a final, fine-grained recognition. We validate this approach on a comprehensive set of 303 regulatory signs from the Ohio MUTCD. Experimental results demonstrate the framework's effectiveness, achieving 95.58% accuracy on ideal reference images and 82.45% on challenging real-world road data. This work demonstrates the viability of RAG-based architectures for creating scalable and accurate systems for road sign recognition without task-specific training.
An Uncertainty-Weighted Decision Transformer for Navigation in Dense, Complex Driving Scenarios
Sep 16, 2025Autonomous driving in dense, dynamic environments requires decision-making systems that can exploit both spatial structure and long-horizon temporal dependencies while remaining robust to uncertainty. This work presents a novel framework that integrates multi-channel bird's-eye-view occupancy grids with transformer-based sequence modeling for tactical driving in complex roundabout scenarios. To address the imbalance between frequent low-risk states and rare safety-critical decisions, we propose the Uncertainty-Weighted Decision Transformer (UWDT). UWDT employs a frozen teacher transformer to estimate per-token predictive entropy, which is then used as a weight in the student model's loss function. This mechanism amplifies learning from uncertain, high-impact states while maintaining stability across common low-risk transitions. Experiments in a roundabout simulator, across varying traffic densities, show that UWDT consistently outperforms other baselines in terms of reward, collision rate, and behavioral stability. The results demonstrate that uncertainty-aware, spatial-temporal transformers can deliver safer and more efficient decision-making for autonomous driving in complex traffic environments.
CleanPose: Category-Level Object Pose Estimation via Causal Learning and Knowledge Distillation
Feb 03, 2025



Category-level object pose estimation aims to recover the rotation, translation and size of unseen instances within predefined categories. In this task, deep neural network-based methods have demonstrated remarkable performance. However, previous studies show they suffer from spurious correlations raised by "unclean" confounders in models, hindering their performance on novel instances with significant variations. To address this issue, we propose CleanPose, a novel approach integrating causal learning and knowledge distillation to enhance category-level pose estimation. To mitigate the negative effect of unobserved confounders, we develop a causal inference module based on front-door adjustment, which promotes unbiased estimation by reducing potential spurious correlations. Additionally, to further improve generalization ability, we devise a residual-based knowledge distillation method that has proven effective in providing comprehensive category information guidance. Extensive experiments across multiple benchmarks (REAL275, CAMERA25 and HouseCat6D) hightlight the superiority of proposed CleanPose over state-of-the-art methods. Code will be released.
MoTE: Reconciling Generalization with Specialization for Visual-Language to Video Knowledge Transfer
Oct 14, 2024Transferring visual-language knowledge from large-scale foundation models for video recognition has proved to be effective. To bridge the domain gap, additional parametric modules are added to capture the temporal information. However, zero-shot generalization diminishes with the increase in the number of specialized parameters, making existing works a trade-off between zero-shot and close-set performance. In this paper, we present MoTE, a novel framework that enables generalization and specialization to be balanced in one unified model. Our approach tunes a mixture of temporal experts to learn multiple task views with various degrees of data fitting. To maximally preserve the knowledge of each expert, we propose \emph{Weight Merging Regularization}, which regularizes the merging process of experts in weight space. Additionally with temporal feature modulation to regularize the contribution of temporal feature during test. We achieve a sound balance between zero-shot and close-set video recognition tasks and obtain state-of-the-art or competitive results on various datasets, including Kinetics-400 \& 600, UCF, and HMDB. Code is available at \url{https://github.com/ZMHH-H/MoTE}.
Efficient Text-driven Motion Generation via Latent Consistency Training
May 05, 2024Motion diffusion models have recently proven successful for text-driven human motion generation. Despite their excellent generation performance, they are challenging to infer in real time due to the multi-step sampling mechanism that involves tens or hundreds of repeat function evaluation iterations. To this end, we investigate a motion latent consistency Training (MLCT) for motion generation to alleviate the computation and time consumption during iteration inference. It applies diffusion pipelines to low-dimensional motion latent spaces to mitigate the computational burden of each function evaluation. Explaining the diffusion process with probabilistic flow ordinary differential equation (PF-ODE) theory, the MLCT allows extremely few steps infer between the prior distribution to the motion latent representation distribution via maintaining consistency of the outputs over the trajectory of PF-ODE. Especially, we introduce a quantization constraint to optimize motion latent representations that are bounded, regular, and well-reconstructed compared to traditional variational constraints. Furthermore, we propose a conditional PF-ODE trajectory simulation method, which improves the conditional generation performance with minimal additional training costs. Extensive experiments on two human motion generation benchmarks show that the proposed model achieves state-of-the-art performance with less than 10\% time cost.