 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTAG: Boosting Text-VQA via Text-aware Visual Question-answer Generation
Aug 14, 2022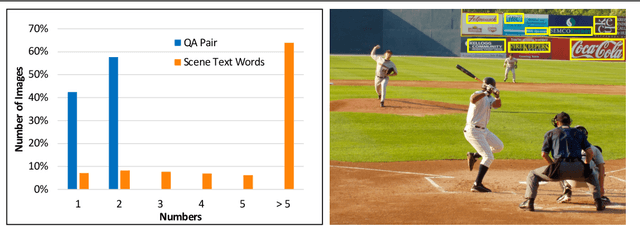
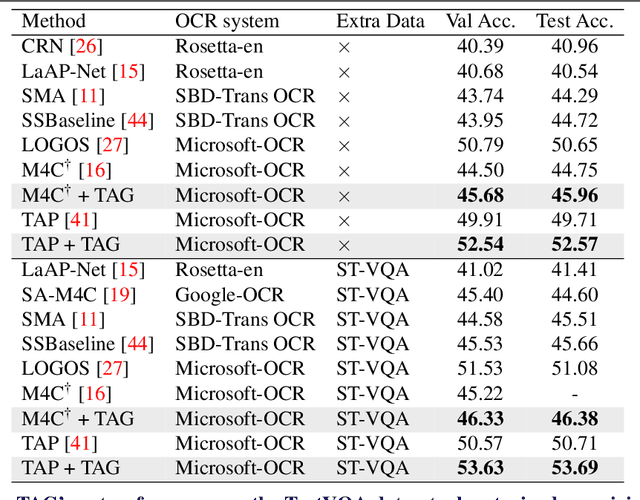

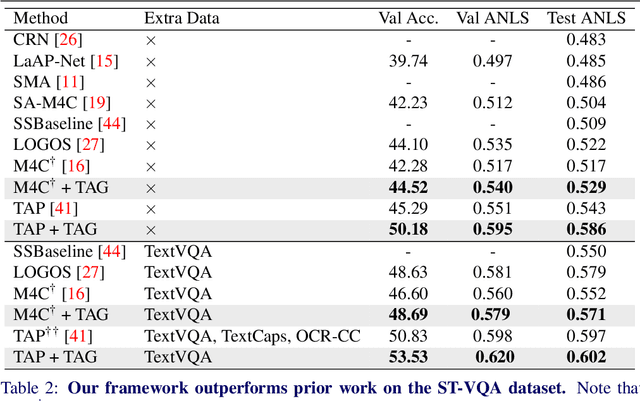
Text-VQA aims at answering questions that require understanding the textual cues in an image. Despite the great progress of existing Text-VQA methods, their performance suffers from insufficient human-labeled question-answer (QA) pairs. However, we observe that, in general, the scene text is not fully exploited in the existing datasets -- only a small portion of text in each image participates in the annotated QA activities. This results in a huge waste of useful information. To address this deficiency, we develop a new method to generate high-quality and diverse QA pairs by explicitly utilizing the existing rich text available in the scene context of each image. Specifically, we propose, TAG, a text-aware visual question-answer generation architecture that learns to produce meaningful, and accurate QA samples using a multimodal transformer. The architecture exploits underexplored scene text information and enhances scene understanding of Text-VQA models by combining the generated QA pairs with the initial training data. Extensive experimental results on two well-known Text-VQA benchmarks (TextVQA and ST-VQA) demonstrate that our proposed TAG effectively enlarges the training data that helps improve the Text-VQA performance without extra labeling effort. Moreover, our model outperforms state-of-the-art approaches that are pre-trained with extra large-scale data. Code is available at https://github.com/HenryJunW/TAG.
Value Retrieval with Arbitrary Queries for Form-like Documents
Dec 15, 2021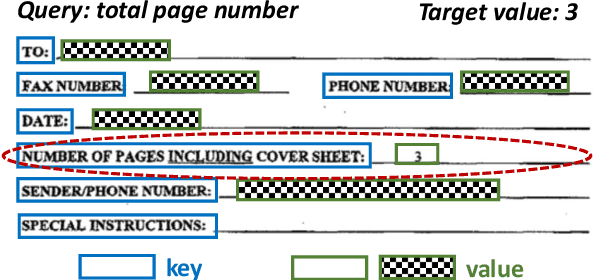

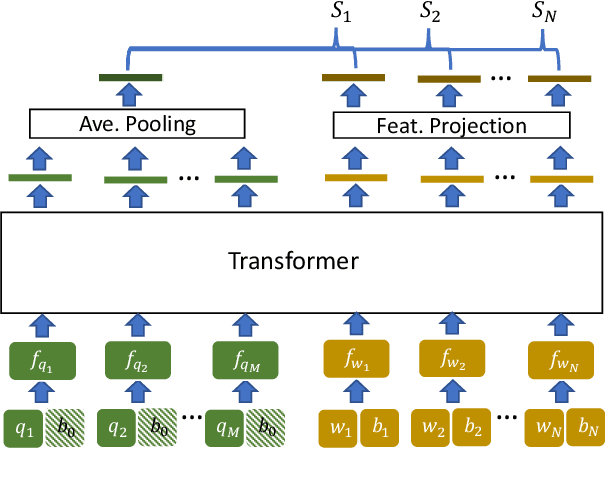
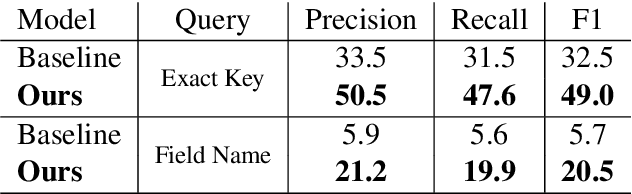
We propose value retrieval with arbitrary queries for form-like documents to reduce human effort of processing forms. Unlike previous methods that only address a fixed set of field items, our method predicts target value for an arbitrary query based on the understanding of layout and semantics of a form. To further boost model performance, we propose a simple document language modeling (simpleDLM) strategy to improve document understanding on large-scale model pre-training. Experimental results show that our method outperforms our baselines significantly and the simpleDLM further improves our performance on value retrieval by around 17\% F1 score compared with the state-of-the-art pre-training method. Code will be made publicly available.
Burn After Reading: Online Adaptation for Cross-domain Streaming Data
Dec 08, 2021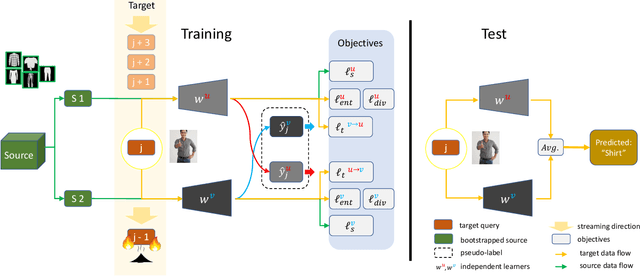
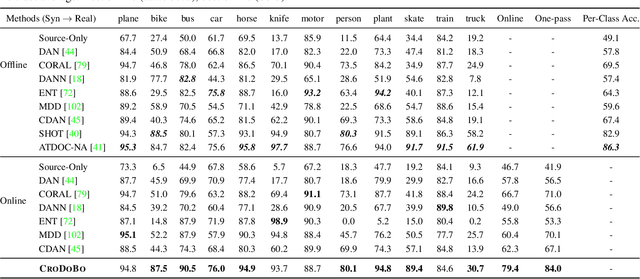
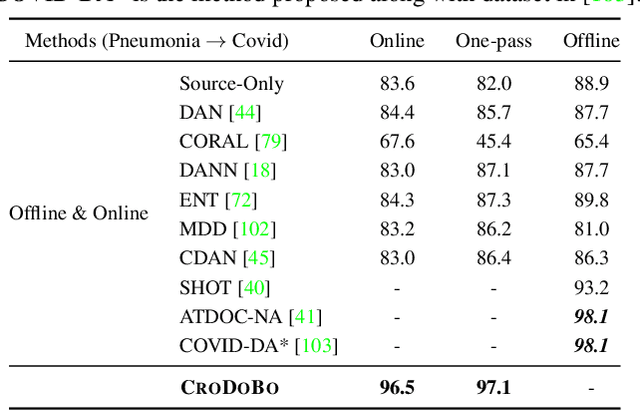
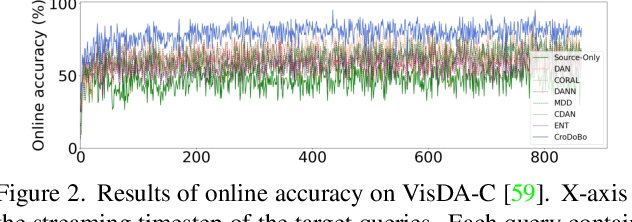
In the context of online privacy, many methods propose complex privacy and security preserving measures to protect sensitive data. In this paper, we argue that: not storing any sensitive data is the best form of security. Thus we propose an online framework that "burns after reading", i.e. each online sample is immediately deleted after it is processed. Meanwhile, we tackle the inevitable distribution shift between the labeled public data and unlabeled private data as a problem of unsupervised domain adaptation. Specifically, we propose a novel algorithm that aims at the most fundamental challenge of the online adaptation setting--the lack of diverse source-target data pairs. Therefore, we design a Cross-Domain Bootstrapping approach, called CroDoBo, to increase the combined diversity across domains. Further, to fully exploit the valuable discrepancies among the diverse combinations, we employ the training strategy of multiple learners with co-supervision. CroDoBo achieves state-of-the-art online performance on four domain adaptation benchmarks.
Towards Open Vocabulary Object Detection without Human-provided Bounding Boxes
Nov 18, 2021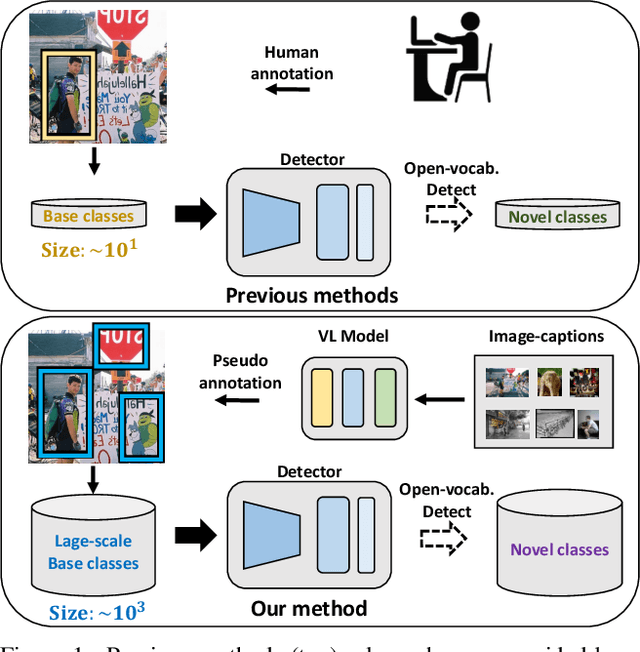
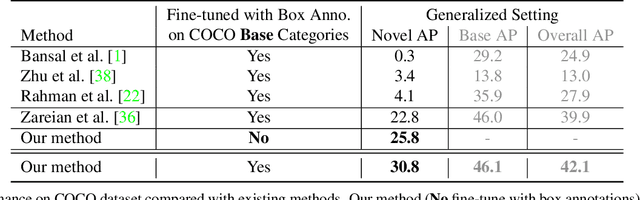
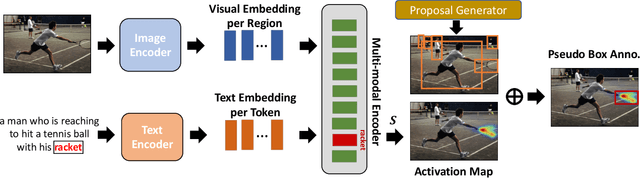
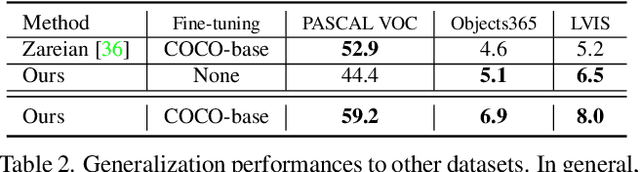
Despite great progress in object detection, most existing methods are limited to a small set of object categories, due to the tremendous human effort needed for instance-level bounding-box annotation. To alleviate the problem, recent open vocabulary and zero-shot detection methods attempt to detect object categories not seen during training. However, these approaches still rely on manually provided bounding-box annotations on a set of base classes. We propose an open vocabulary detection framework that can be trained without manually provided bounding-box annotations. Our method achieves this by leveraging the localization ability of pre-trained vision-language models and generating pseudo bounding-box labels that can be used directly for training object detectors. Experimental results on COCO, PASCAL VOC, Objects365 and LVIS demonstrate the effectiveness of our method. Specifically, our method outperforms the state-of-the-arts (SOTA) that are trained using human annotated bounding-boxes by 3% AP on COCO novel categories even though our training source is not equipped with manual bounding-box labels. When utilizing the manual bounding-box labels as our baselines do, our method surpasses the SOTA largely by 8% AP.
Robustness Evaluation of Transformer-based Form Field Extractors via Form Attacks
Oct 08, 2021
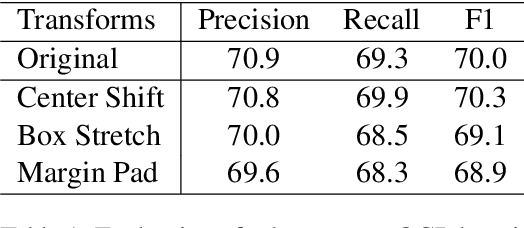
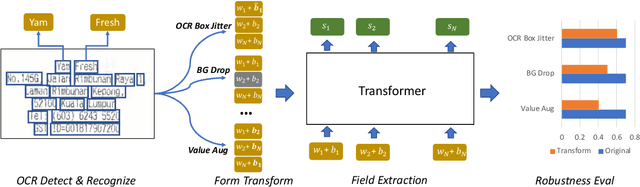
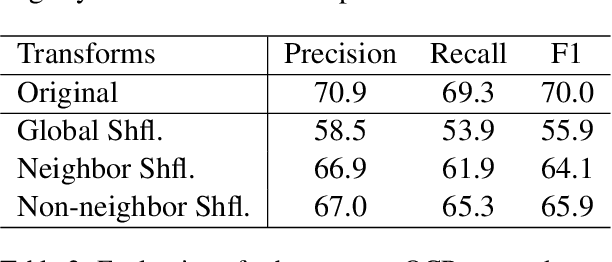
We propose a novel framework to evaluate the robustness of transformer-based form field extraction methods via form attacks. We introduce 14 novel form transformations to evaluate the vulnerability of the state-of-the-art field extractors against form attacks from both OCR level and form level, including OCR location/order rearrangement, form background manipulation and form field-value augmentation. We conduct robustness evaluation using real invoices and receipts, and perform comprehensive research analysis. Experimental results suggest that the evaluated models are very susceptible to form perturbations such as the variation of field-values (~15% drop in F1 score), the disarrangement of input text order(~15% drop in F1 score) and the disruption of the neighboring words of field-values(~10% drop in F1 score). Guided by the analysis, we make recommendations to improve the design of field extractors and the process of data collection.
Field Extraction from Forms with Unlabeled Data
Oct 08, 2021
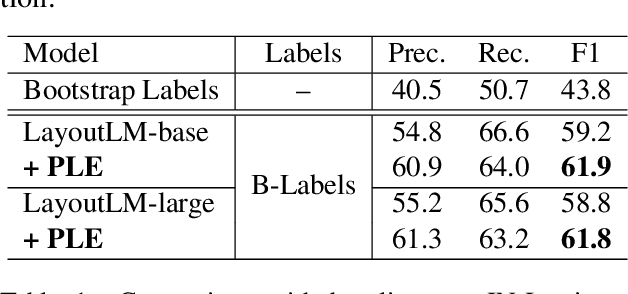
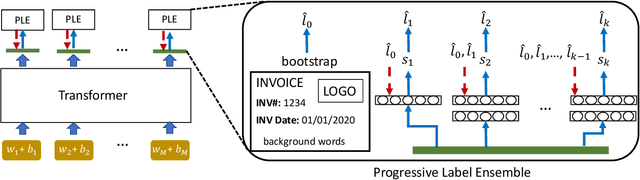
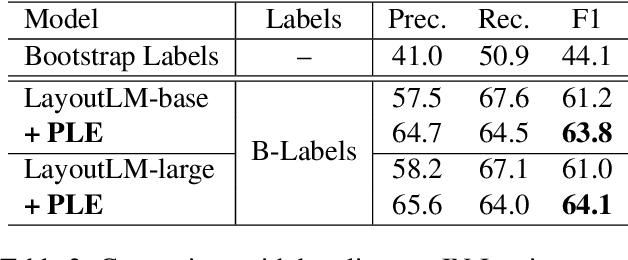
We propose a novel framework to conduct field extraction from forms with unlabeled data. To bootstrap the training process, we develop a rule-based method for mining noisy pseudo-labels from unlabeled forms. Using the supervisory signal from the pseudo-labels, we extract a discriminative token representation from a transformer-based model by modeling the interaction between text in the form. To prevent the model from overfitting to label noise, we introduce a refinement module based on a progressive pseudo-label ensemble. Experimental results demonstrate the effectiveness of our framework.
MiCo: Mixup Co-Training for Semi-Supervised Domain Adaptation
Jul 24, 2020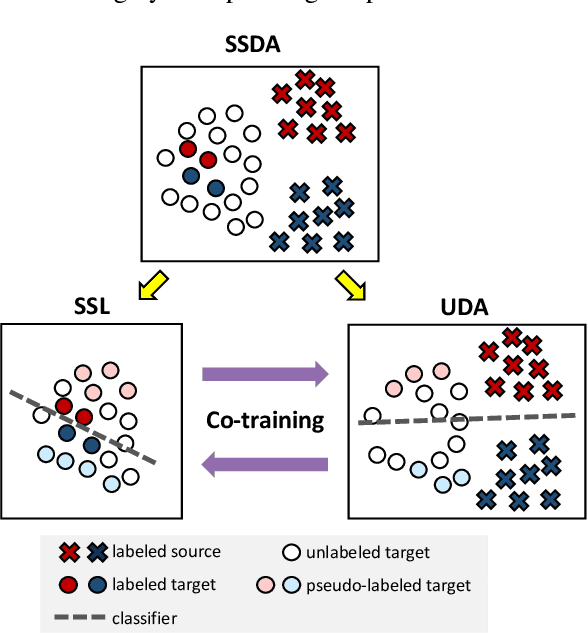
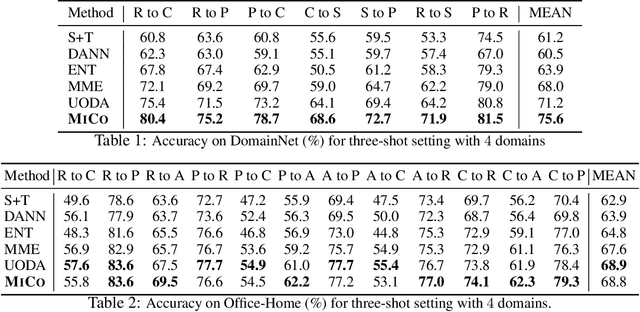
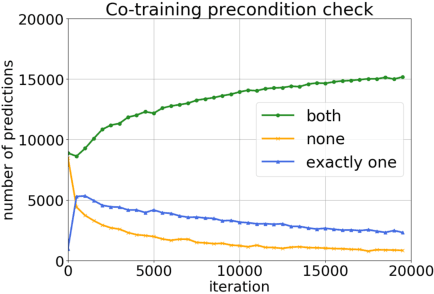
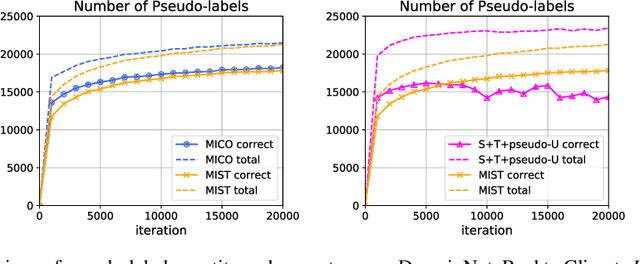
Semi-supervised domain adaptation (SSDA) aims to adapt models from a labeled source domain to a different but related target domain, from which unlabeled data and a small set of labeled data are provided. In this paper we propose a new approach for SSDA, which is to explicitly decompose SSDA into two sub-problems: a semi-supervised learning (SSL) problem in the target domain and an unsupervised domain adaptation (UDA) problem across domains. We show that these two sub-problems yield very different classifiers, which we leverage with our algorithm MixUp Co-training (MiCo). MiCo applies Mixup to bridge the gap between labeled and unlabeled data of each individual model and employs co-training to exchange the expertise between the two classifiers. MiCo needs no adversarial and minmax training, making it easily implementable and stable. MiCo achieves state-of-the-art results on SSDA datasets, outperforming the prior art by a notable 4% margin on DomainNet.
InfoFocus: 3D Object Detection for Autonomous Driving with Dynamic Information Modeling
Jul 16, 2020

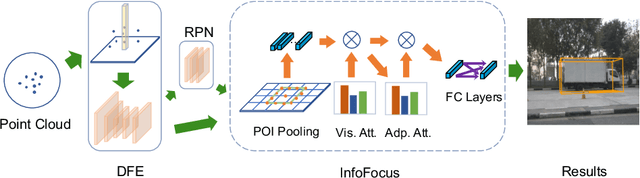
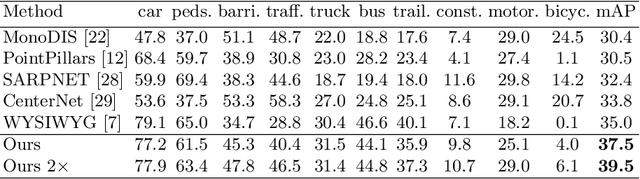
Real-time 3D object detection is crucial for autonomous cars. Achieving promising performance with high efficiency, voxel-based approaches have received considerable attention. However, previous methods model the input space with features extracted from equally divided sub-regions without considering that point cloud is generally non-uniformly distributed over the space. To address this issue, we propose a novel 3D object detection framework with dynamic information modeling. The proposed framework is designed in a coarse-to-fine manner. Coarse predictions are generated in the first stage via a voxel-based region proposal network. We introduce InfoFocus, which improves the coarse detections by adaptively refining features guided by the information of point cloud density. Experiments are conducted on the large-scale nuScenes 3D detection benchmark. Results show that our framework achieves the state-of-the-art performance with 31 FPS and improves our baseline significantly by 9.0% mAP on the nuScenes test set.
WOAD: Weakly Supervised Online Action Detection in Untrimmed Videos
Jun 05, 2020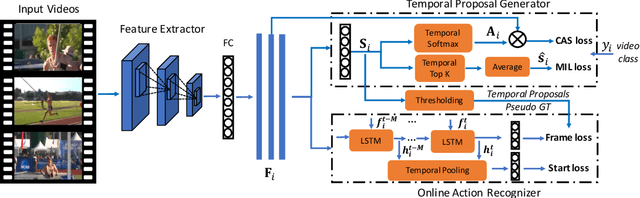
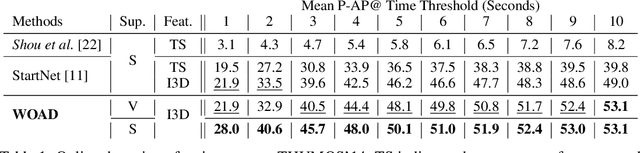
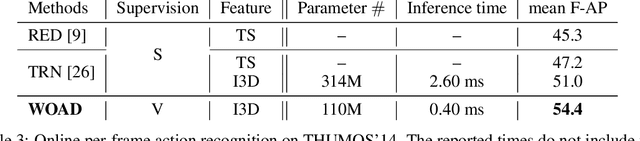
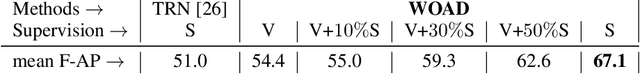
Online action detection in untrimmed videos aims to identify an action as it happens, which makes it very important for real-time applications. Previous methods rely on tedious annotations of temporal action boundaries for model training, which hinders the scalability of online action detection systems. We propose WOAD, a weakly supervised framework that can be trained using only video-class labels. WOAD contains two jointly-trained modules, i.e., temporal proposal generator (TPG) and online action recognizer (OAR). Supervised by video-class labels, TPG works offline and targets on accurately mining pseudo frame-level labels for OAR. With the supervisory signals from TPG, OAR learns to conduct action detection in an online fashion. Experimental results on THUMOS'14 and ActivityNet1.2 show that our weakly-supervised method achieves competitive performance compared to previous strongly-supervised methods. Beyond that, our method is flexible to leverage strong supervision when it is available. When strongly supervised, our method sets new state-of-the-art results in the online action detection tasks including online per-frame action recognition and online detection of action start.
Consistency-Based Semi-Supervised Active Learning: Towards Minimizing Labeling Cost
Oct 16, 2019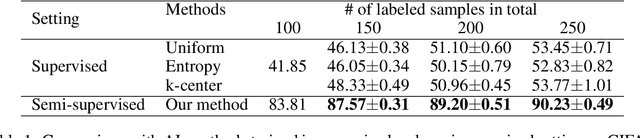
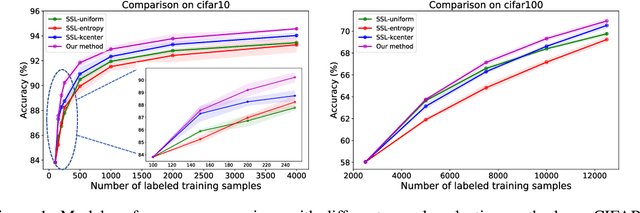
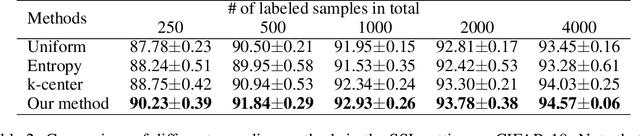
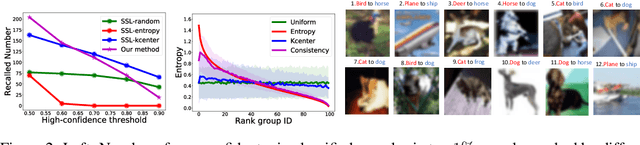
Active learning (AL) integrates data labeling and model training to minimize the labeling cost by prioritizing the selection of high value data that can best improve model performance. Readily-available unlabeled data are used for selection mechanisms, but are not used for model training in most conventional pool-based AL methods. To minimize the labeling cost, we unify unlabeled sample selection and model training based on two principles. First, we exploit both labeled and unlabeled data using semi-supervised learning (SSL) to distill information from unlabeled data that improves representation learning and sample selection. Second, we propose a simple yet effective selection metric that is coherent with the training objective such that the selected samples are effective at improving model performance. Experimental results demonstrate superior performance of our proposed principles for limited labeled data compared to alternative AL and SSL combinations. In addition, we study an important problem -- "When can we start AL?". We propose a measure that is empirically correlated with the AL target loss and can be used to assist in determining the proper start point.