 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTheoretical Error Performance Analysis for Variational Quantum Circuit Based Functional Regression
Jun 08, 2022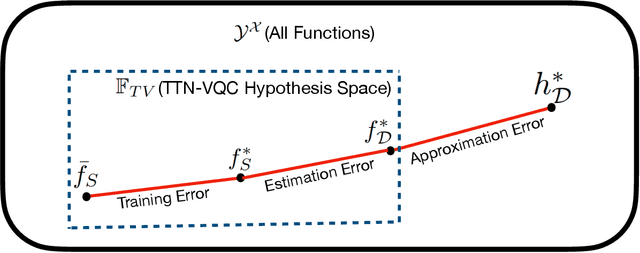

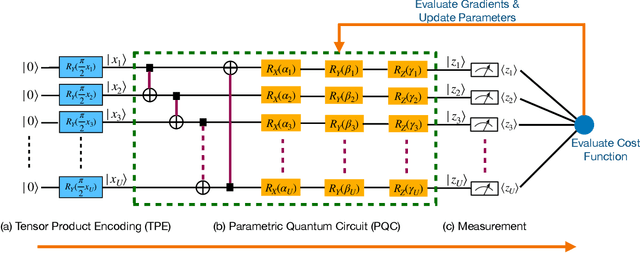
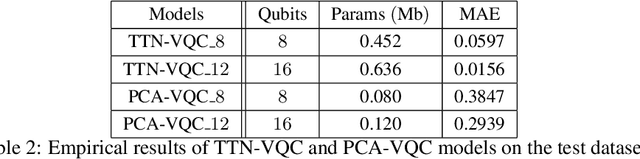
The noisy intermediate-scale quantum (NISQ) devices enable the implementation of the variational quantum circuit (VQC) for quantum neural networks (QNN). Although the VQC-based QNN has succeeded in many machine learning tasks, the representation and generalization powers of VQC still require further investigation, particularly when the dimensionality reduction of classical inputs is concerned. In this work, we first put forth an end-to-end quantum neural network, namely, TTN-VQC, which consists of a quantum tensor network based on a tensor-train network (TTN) for dimensionality reduction and a VQC for functional regression. Then, we aim at the error performance analysis for the TTN-VQC in terms of representation and generalization powers. We also characterize the optimization properties of TTN-VQC by leveraging the Polyak-Lojasiewicz (PL) condition. Moreover, we conduct the experiments of functional regression on a handwritten digit classification dataset to justify our theoretical analysis.
Recent Advances for Quantum Neural Networks in Generative Learning
Jun 07, 2022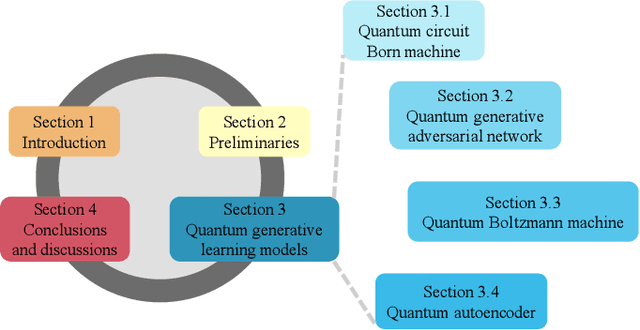

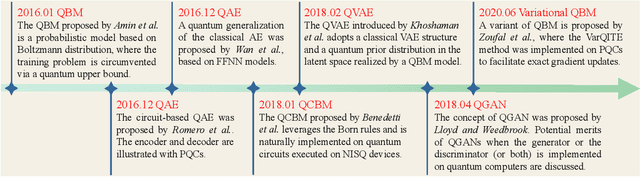
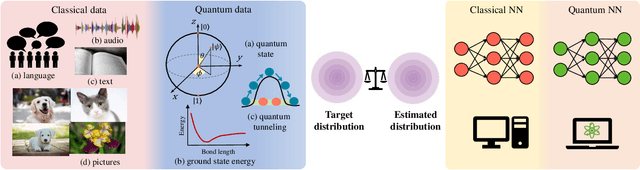
Quantum computers are next-generation devices that hold promise to perform calculations beyond the reach of classical computers. A leading method towards achieving this goal is through quantum machine learning, especially quantum generative learning. Due to the intrinsic probabilistic nature of quantum mechanics, it is reasonable to postulate that quantum generative learning models (QGLMs) may surpass their classical counterparts. As such, QGLMs are receiving growing attention from the quantum physics and computer science communities, where various QGLMs that can be efficiently implemented on near-term quantum machines with potential computational advantages are proposed. In this paper, we review the current progress of QGLMs from the perspective of machine learning. Particularly, we interpret these QGLMs, covering quantum circuit born machines, quantum generative adversarial networks, quantum Boltzmann machines, and quantum autoencoders, as the quantum extension of classical generative learning models. In this context, we explore their intrinsic relation and their fundamental differences. We further summarize the potential applications of QGLMs in both conventional machine learning tasks and quantum physics. Last, we discuss the challenges and further research directions for QGLMs.
Gaussian initializations help deep variational quantum circuits escape from the barren plateau
Mar 17, 2022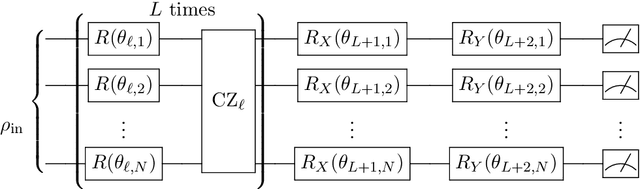
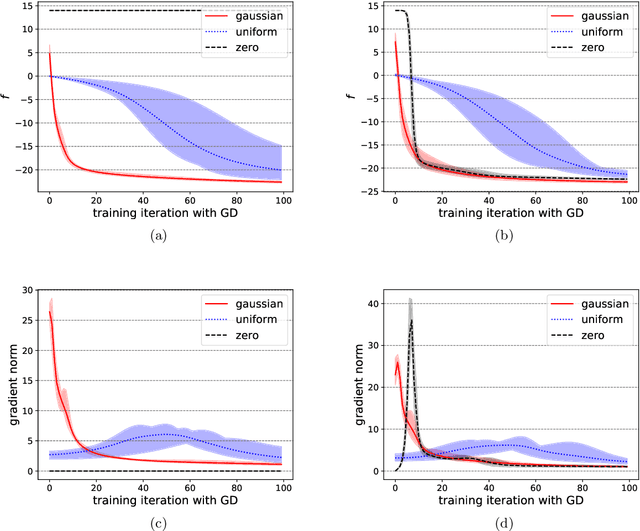
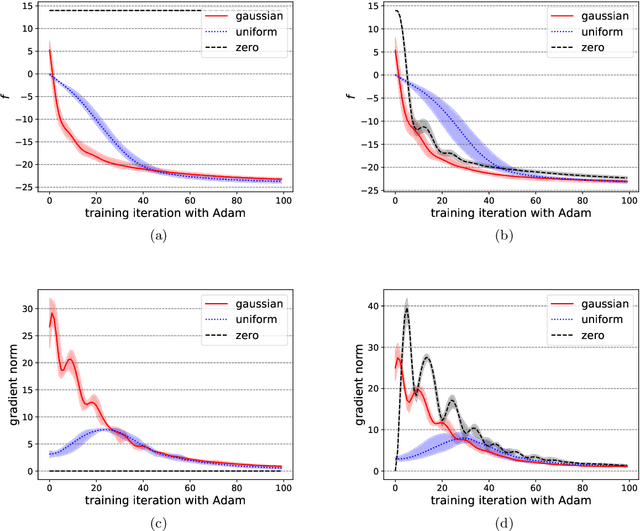
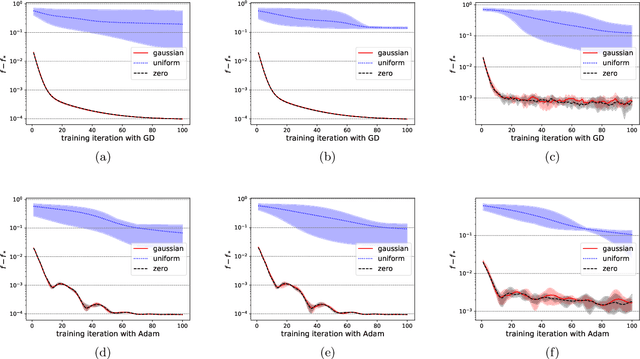
Variational quantum circuits have been widely employed in quantum simulation and quantum machine learning in recent years. However, quantum circuits with random structures have poor trainability due to the exponentially vanishing gradient with respect to the circuit depth and the qubit number. This result leads to a general belief that deep quantum circuits will not be feasible for practical tasks. In this work, we propose an initialization strategy with theoretical guarantees for the vanishing gradient problem in general deep circuits. Specifically, we prove that under proper Gaussian initialized parameters, the norm of the gradient decays at most polynomially when the qubit number and the circuit depth increase. Our theoretical results hold for both the local and the global observable cases, where the latter was believed to have vanishing gradients even for shallow circuits. Experimental results verify our theoretical findings in the quantum simulation and quantum chemistry.
Capacity of First Arrival Position Channel in Diffusion-Based Molecular Communication
Jan 27, 2022


In [1], the impulse response of the first arrival position (FAP) channel of 2D and 3D spaces in molecular communication (MC) is derived, but its Shannon capacity remains open. The main difficulty of depicting the FAP channel capacity comes from the fact that the FAP density becomes a multi-dimensional Cauchy distribution when the drift velocity approaches zero. As a result, the commonly used techniques in maximizing the mutual information no longer work because the first and second moments of Cauchy distributions do not exist. Our main contribution in this paper is a complete characterization of the zero-drift FAP channel capacity for the 2D and 3D spaces. The capacity formula for FAP channel turns out to have a similar form compared to the Gaussian channel case (under second-moment power constraint). It is also worth mentioning that the capacity value of 3D FAP channel is twice as large as 2D FAP channel. This is an evidence that the FAP channel has larger capacity as the spatial dimension grows. Finally, our technical contributions are the application of a modified logarithmic constraint as a replacement of the usual power constraint, and the choice of output signal constraint as a substitution to input signal constraint in order to keep the resulting formula concise.
First Arrival Position in Molecular Communication Via Generator of Diffusion Semigroup
Jan 14, 2022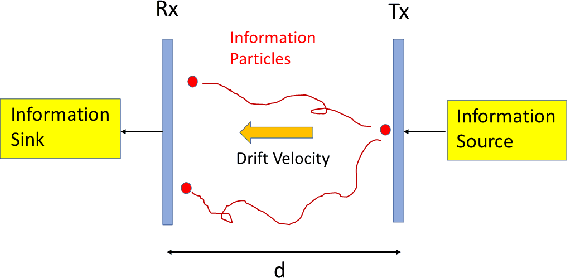
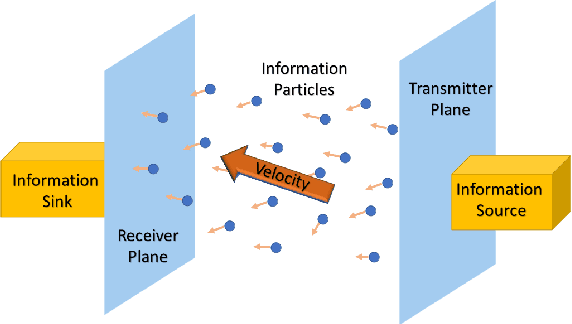
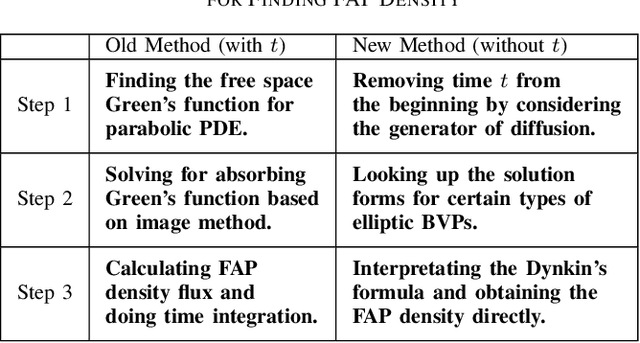
We consider the problem of characterizing the first arrival position (FAP) density in molecular communication (MC) with a diffusion-advection channel that permits a constant drift velocity pointed to arbitrary direction. The advantage of FAP modulation lies in the fact that it could encode more information into higher dimensional spatial variables, compared to other modulation techniques using time or molecule numbers. However, effective methods to characterize the FAP density in a general framework do not exist. In this paper, we devise a methodology that fully resolves the FAP density with planar absorbing receivers in arbitrary dimensions. Our work recovers existing results of FAP in 2D and 3D as special cases. The key insight of our approach is to remove the time dependence of the MC system evolution based on the generator of diffusion semigroups.
Quantum Optimization for Training Quantum Neural Networks
Mar 31, 2021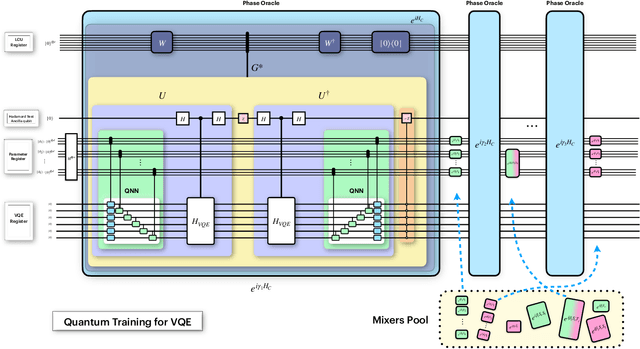
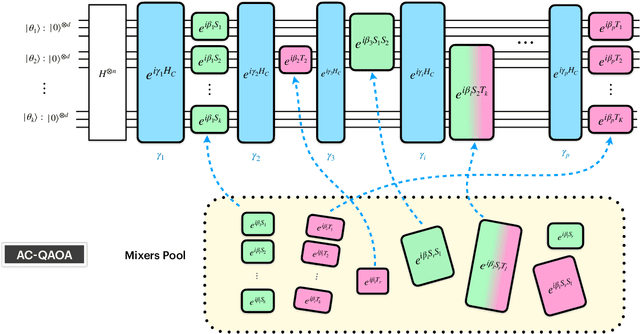
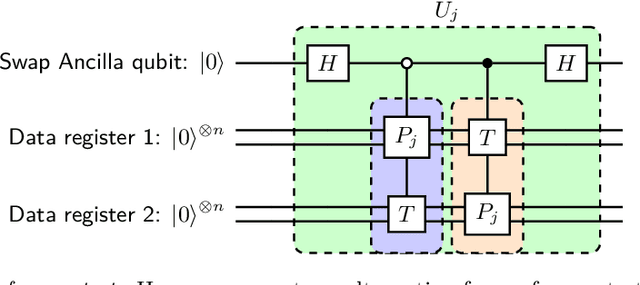
Training quantum neural networks (QNNs) using gradient-based or gradient-free classical optimisation approaches is severely impacted by the presence of barren plateaus in the cost landscapes. In this paper, we devise a framework for leveraging quantum optimisation algorithms to find optimal parameters of QNNs for certain tasks. To achieve this, we coherently encode the cost function of QNNs onto relative phases of a superposition state in the Hilbert space of the network parameters. The parameters are tuned with an iterative quantum optimisation structure using adaptively selected Hamiltonians. The quantum mechanism of this framework exploits hidden structure in the QNN optimisation problem and hence is expected to provide beyond-Grover speed up, mitigating the barren plateau issue.
Quantum circuit architecture search: error mitigation and trainability enhancement for variational quantum solvers
Nov 12, 2020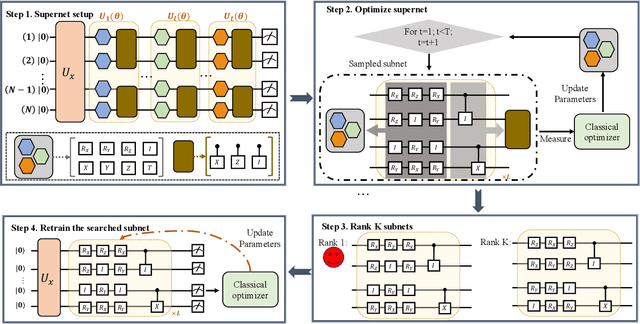
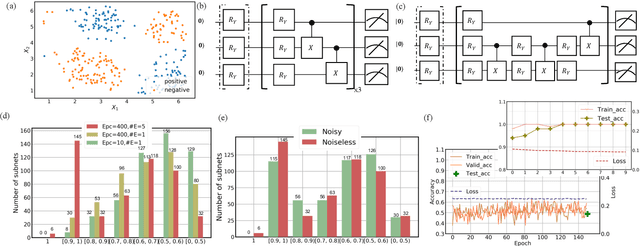
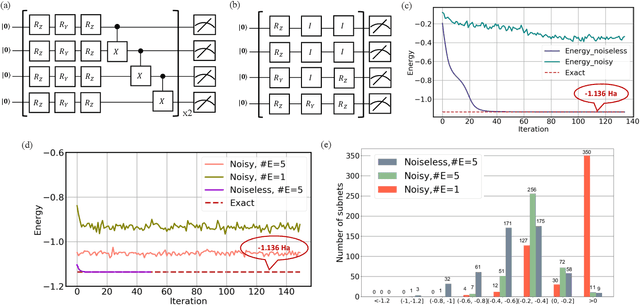
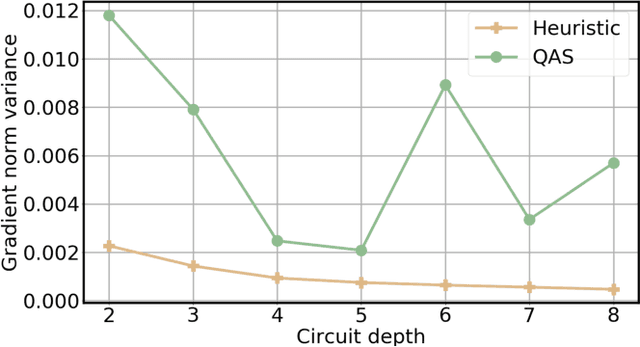
Quantum error mitigation techniques are at the heart of quantum hardware implementation, and are the key to performance improvement of the variational quantum learning scheme (VQLS). Although VQLS is partially robust to noise, both empirical and theoretical results exhibit that noise would rapidly deteriorate the performance of most variational quantum algorithms in large-scale problems. Furthermore, VQLS suffers from the barren plateau phenomenon---the gradient generated by the classical optimizer vanishes exponentially with respect to the qubit number. Here we devise a resource and runtime efficient scheme, the quantum architecture search scheme (QAS), to maximally improve the robustness and trainability of VQLS. In particular, given a learning task, QAS actively seeks an optimal circuit architecture to balance benefits and side-effects brought by adding more quantum gates. Specifically, while more quantum gates enable a stronger expressive power of the quantum model, they introduce a larger amount of noise and a more serious barren plateau scenario. Consequently, QAS can effectively suppress the influence of quantum noise and barren plateaus. We implement QAS on both the numerical simulator and real quantum hardware, via the IBM cloud, to accomplish data classification and quantum chemistry tasks. Numerical and experimental results show that QAS significantly outperforms conventional variational quantum algorithms with heuristic circuit architectures. Our work provides practical guidance for developing advanced learning-based quantum error mitigation techniques on near-term quantum devices.
Experimental Quantum Generative Adversarial Networks for Image Generation
Oct 21, 2020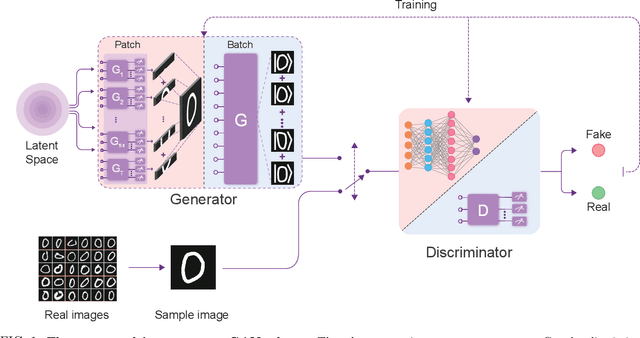

Quantum machine learning is expected to be one of the first practical applications of near-term quantum devices. Pioneer theoretical works suggest that quantum generative adversarial networks (GANs) may exhibit a potential exponential advantage over classical GANs, thus attracting widespread attention. However, it remains elusive whether quantum GANs implemented on near-term quantum devices can actually solve real-world learning tasks. Here, we devise a flexible quantum GAN scheme to narrow this knowledge gap, which could accomplish image generation with arbitrarily high-dimensional features, and could also take advantage of quantum superposition to train multiple examples in parallel. For the first time, we experimentally achieve the learning and generation of real-world hand-written digit images on a superconducting quantum processor. Moreover, we utilize a gray-scale bar dataset to exhibit the competitive performance between quantum GANs and the classical GANs based on multilayer perceptron and convolutional neural network architectures, respectively, benchmarked by the Fr\'echet Distance score. Our work provides guidance for developing advanced quantum generative models on near-term quantum devices and opens up an avenue for exploring quantum advantages in various GAN-related learning tasks.
Quantum differentially private sparse regression learning
Jul 23, 2020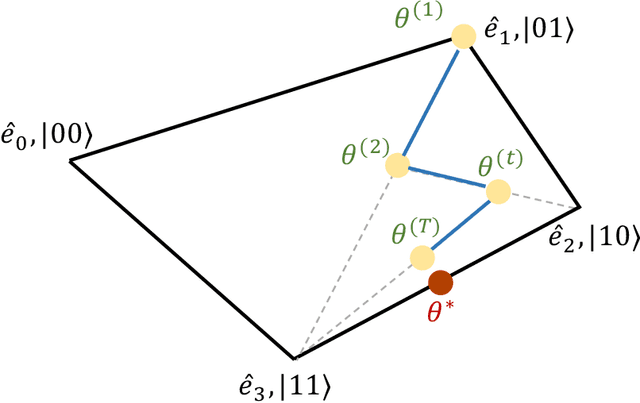
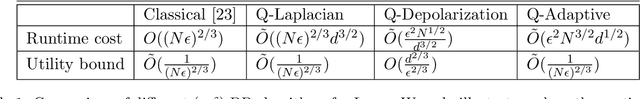
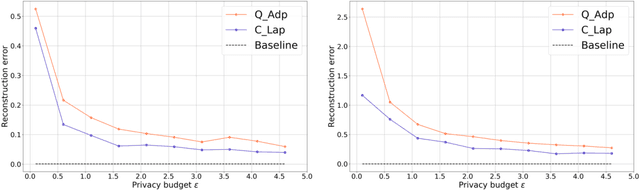
Differentially private (DP) learning, which aims to accurately extract patterns from the given dataset without exposing individual information, is an important subfield in machine learning and has been extensively explored. However, quantum algorithms that could preserve privacy, while outperform their classical counterparts, are still lacking. The difficulty arises from the distinct priorities in DP and quantum machine learning, i.e., the former concerns a low utility bound while the latter pursues a low runtime cost. These varied goals request that the proposed quantum DP algorithm should achieve the runtime speedup over the best known classical results while preserving the optimal utility bound. The Lasso estimator is broadly employed to tackle the high dimensional sparse linear regression tasks. The main contribution of this paper is devising a quantum DP Lasso estimator to earn the runtime speedup with the privacy preservation, i.e., the runtime complexity is $\tilde{O}(N^{3/2}\sqrt{d})$ with a nearly optimal utility bound $\tilde{O}(1/N^{2/3})$, where $N$ is the sample size and $d$ is the data dimension with $N\ll d$. Since the optimal classical (private) Lasso takes $\Omega(N+d)$ runtime, our proposal achieves quantum speedups when $N<O(d^{1/3})$. There are two key components in our algorithm. First, we extend the Frank-Wolfe algorithm from the classical Lasso to the quantum scenario, {where the proposed quantum non-private Lasso achieves a quadratic runtime speedup over the optimal classical Lasso.} Second, we develop an adaptive privacy mechanism to ensure the privacy guarantee of the non-private Lasso. Our proposal opens an avenue to design various learning tasks with both the proven runtime speedups and the privacy preservation.
Quantum noise protects quantum classifiers against adversaries
Mar 20, 2020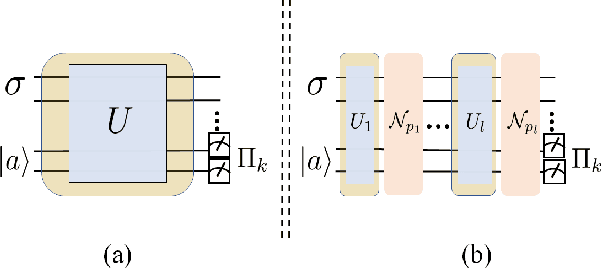
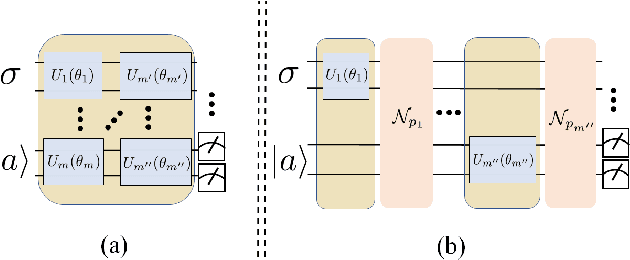

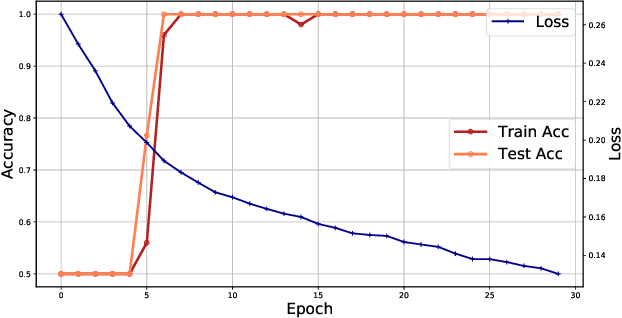
Noise in quantum information processing is often viewed as a disruptive and difficult-to-avoid feature, especially in near-term quantum technologies. However, noise has often played beneficial roles, from enhancing weak signals in stochastic resonance to protecting the privacy of data in differential privacy. It is then natural to ask, can we harness the power of quantum noise that is beneficial to quantum computing? An important current direction for quantum computing is its application to machine learning, such as classification problems. One outstanding problem in machine learning for classification is its sensitivity to adversarial examples. These are small, undetectable perturbations from the original data where the perturbed data is completely misclassified in otherwise extremely accurate classifiers. They can also be considered as `worst-case' perturbations by unknown noise sources. We show that by taking advantage of depolarisation noise in quantum circuits for classification, a robustness bound against adversaries can be derived where the robustness improves with increasing noise. This robustness property is intimately connected with an important security concept called differential privacy which can be extended to quantum differential privacy. For the protection of quantum data, this is the first quantum protocol that can be used against the most general adversaries. Furthermore, we show how the robustness in the classical case can be sensitive to the details of the classification model, but in the quantum case the details of classification model are absent, thus also providing a potential quantum advantage for classical data that is independent of quantum speedups. This opens the opportunity to explore other ways in which quantum noise can be used in our favour, as well as identifying other ways quantum algorithms can be helpful that is independent of quantum speedups.