 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJOLT-SQL: Joint Loss Tuning of Text-to-SQL with Confusion-aware Noisy Schema Sampling
May 20, 2025



Text-to-SQL, which maps natural language to SQL queries, has benefited greatly from recent advances in Large Language Models (LLMs). While LLMs offer various paradigms for this task, including prompting and supervised fine-tuning (SFT), SFT approaches still face challenges such as complex multi-stage pipelines and poor robustness to noisy schema information. To address these limitations, we present JOLT-SQL, a streamlined single-stage SFT framework that jointly optimizes schema linking and SQL generation via a unified loss. JOLT-SQL employs discriminative schema linking, enhanced by local bidirectional attention, alongside a confusion-aware noisy schema sampling strategy with selective attention to improve robustness under noisy schema conditions. Experiments on the Spider and BIRD benchmarks demonstrate that JOLT-SQL achieves state-of-the-art execution accuracy among comparable-size open-source models, while significantly improving both training and inference efficiency.
One Size doesn't Fit All: A Personalized Conversational Tutoring Agent for Mathematics Instruction
Feb 19, 2025Large language models (LLMs) have been increasingly employed in various intelligent educational systems, simulating human tutors to facilitate effective human-machine interaction. However, previous studies often overlook the significance of recognizing and adapting to individual learner characteristics. Such adaptation is crucial for enhancing student engagement and learning efficiency, particularly in mathematics instruction, where diverse learning styles require personalized strategies to promote comprehension and enthusiasm. In this paper, we propose a \textbf{P}erson\textbf{A}lized \textbf{C}onversational tutoring ag\textbf{E}nt (PACE) for mathematics instruction. PACE simulates students' learning styles based on the Felder and Silverman learning style model, aligning with each student's persona. In this way, our PACE can effectively assess the personality of students, allowing to develop individualized teaching strategies that resonate with their unique learning styles. To further enhance students' comprehension, PACE employs the Socratic teaching method to provide instant feedback and encourage deep thinking. By constructing personalized teaching data and training models, PACE demonstrates the ability to identify and adapt to the unique needs of each student, significantly improving the overall learning experience and outcomes. Moreover, we establish multi-aspect evaluation criteria and conduct extensive analysis to assess the performance of personalized teaching. Experimental results demonstrate the superiority of our model in personalizing the educational experience and motivating students compared to existing methods.
Enhancing Financial Time-Series Forecasting with Retrieval-Augmented Large Language Models
Feb 11, 2025



Stock movement prediction, a critical task in financial time-series forecasting, relies on identifying and retrieving key influencing factors from vast and complex datasets. However, traditional text-trained or numeric similarity-based retrieval methods often struggle to handle the intricacies of financial data. To address this, we propose the first retrieval-augmented generation (RAG) framework specifically designed for financial time-series forecasting. Our framework incorporates three key innovations: a fine-tuned 1B large language model (StockLLM) as its backbone, a novel candidate selection method enhanced by LLM feedback, and a training objective that maximizes the similarity between queries and historically significant sequences. These advancements enable our retriever, FinSeer, to uncover meaningful patterns while effectively minimizing noise in complex financial datasets. To support robust evaluation, we also construct new datasets that integrate financial indicators and historical stock prices. Experimental results demonstrate that our RAG framework outperforms both the baseline StockLLM and random retrieval methods, showcasing its effectiveness. FinSeer, as the retriever, achieves an 8% higher accuracy on the BIGDATA22 benchmark and retrieves more impactful sequences compared to existing retrieval methods. This work highlights the importance of tailored retrieval models in financial forecasting and provides a novel, scalable framework for future research in the field.
Retrieval-augmented Large Language Models for Financial Time Series Forecasting
Feb 09, 2025Stock movement prediction, a fundamental task in financial time-series forecasting, requires identifying and retrieving critical influencing factors from vast amounts of time-series data. However, existing text-trained or numeric similarity-based retrieval methods fall short in handling complex financial analysis. To address this, we propose the first retrieval-augmented generation (RAG) framework for financial time-series forecasting, featuring three key innovations: a fine-tuned 1B parameter large language model (StockLLM) as the backbone, a novel candidate selection method leveraging LLM feedback, and a training objective that maximizes similarity between queries and historically significant sequences. This enables our retriever, FinSeer, to uncover meaningful patterns while minimizing noise in complex financial data. We also construct new datasets integrating financial indicators and historical stock prices to train FinSeer and ensure robust evaluation. Experimental results demonstrate that our RAG framework outperforms bare StockLLM and random retrieval, highlighting its effectiveness, while FinSeer surpasses existing retrieval methods, achieving an 8\% higher accuracy on BIGDATA22 and retrieving more impactful sequences. This work underscores the importance of tailored retrieval models in financial forecasting and provides a novel framework for future research.
SymAgent: A Neural-Symbolic Self-Learning Agent Framework for Complex Reasoning over Knowledge Graphs
Feb 05, 2025Recent advancements have highlighted that Large Language Models (LLMs) are prone to hallucinations when solving complex reasoning problems, leading to erroneous results. To tackle this issue, researchers incorporate Knowledge Graphs (KGs) to improve the reasoning ability of LLMs. However, existing methods face two limitations: 1) they typically assume that all answers to the questions are contained in KGs, neglecting the incompleteness issue of KGs, and 2) they treat the KG as a static repository and overlook the implicit logical reasoning structures inherent in KGs. In this paper, we introduce SymAgent, an innovative neural-symbolic agent framework that achieves collaborative augmentation between KGs and LLMs. We conceptualize KGs as dynamic environments and transform complex reasoning tasks into a multi-step interactive process, enabling KGs to participate deeply in the reasoning process. SymAgent consists of two modules: Agent-Planner and Agent-Executor. The Agent-Planner leverages LLM's inductive reasoning capability to extract symbolic rules from KGs, guiding efficient question decomposition. The Agent-Executor autonomously invokes predefined action tools to integrate information from KGs and external documents, addressing the issues of KG incompleteness. Furthermore, we design a self-learning framework comprising online exploration and offline iterative policy updating phases, enabling the agent to automatically synthesize reasoning trajectories and improve performance. Experimental results demonstrate that SymAgent with weak LLM backbones (i.e., 7B series) yields better or comparable performance compared to various strong baselines. Further analysis reveals that our agent can identify missing triples, facilitating automatic KG updates.
SILC-EFSA: Self-aware In-context Learning Correction for Entity-level Financial Sentiment Analysis
Dec 26, 2024



In recent years, fine-grained sentiment analysis in finance has gained significant attention, but the scarcity of entity-level datasets remains a key challenge. To address this, we have constructed the largest English and Chinese financial entity-level sentiment analysis datasets to date. Building on this foundation, we propose a novel two-stage sentiment analysis approach called Self-aware In-context Learning Correction (SILC). The first stage involves fine-tuning a base large language model to generate pseudo-labeled data specific to our task. In the second stage, we train a correction model using a GNN-based example retriever, which is informed by the pseudo-labeled data. This two-stage strategy has allowed us to achieve state-of-the-art performance on the newly constructed datasets, advancing the field of financial sentiment analysis. In a case study, we demonstrate the enhanced practical utility of our data and methods in monitoring the cryptocurrency market. Our datasets and code are available at https://github.com/NLP-Bin/SILC-EFSA.
Filter-then-Generate: Large Language Models with Structure-Text Adapter for Knowledge Graph Completion
Dec 12, 2024



Large Language Models (LLMs) present massive inherent knowledge and superior semantic comprehension capability, which have revolutionized various tasks in natural language processing. Despite their success, a critical gap remains in enabling LLMs to perform knowledge graph completion (KGC). Empirical evidence suggests that LLMs consistently perform worse than conventional KGC approaches, even through sophisticated prompt design or tailored instruction-tuning. Fundamentally, applying LLMs on KGC introduces several critical challenges, including a vast set of entity candidates, hallucination issue of LLMs, and under-exploitation of the graph structure. To address these challenges, we propose a novel instruction-tuning-based method, namely FtG. Specifically, we present a \textit{filter-then-generate} paradigm and formulate the KGC task into a multiple-choice question format. In this way, we can harness the capability of LLMs while mitigating the issue casused by hallucinations. Moreover, we devise a flexible ego-graph serialization prompt and employ a structure-text adapter to couple structure and text information in a contextualized manner. Experimental results demonstrate that FtG achieves substantial performance gain compared to existing state-of-the-art methods. The instruction dataset and code are available at \url{https://github.com/LB0828/FtG}.
Open-FinLLMs: Open Multimodal Large Language Models for Financial Applications
Aug 20, 2024



Large language models (LLMs) have advanced financial applications, yet they often lack sufficient financial knowledge and struggle with tasks involving multi-modal inputs like tables and time series data. To address these limitations, we introduce \textit{Open-FinLLMs}, a series of Financial LLMs. We begin with FinLLaMA, pre-trained on a 52 billion token financial corpus, incorporating text, tables, and time-series data to embed comprehensive financial knowledge. FinLLaMA is then instruction fine-tuned with 573K financial instructions, resulting in FinLLaMA-instruct, which enhances task performance. Finally, we present FinLLaVA, a multimodal LLM trained with 1.43M image-text instructions to handle complex financial data types. Extensive evaluations demonstrate FinLLaMA's superior performance over LLaMA3-8B, LLaMA3.1-8B, and BloombergGPT in both zero-shot and few-shot settings across 19 and 4 datasets, respectively. FinLLaMA-instruct outperforms GPT-4 and other Financial LLMs on 15 datasets. FinLLaVA excels in understanding tables and charts across 4 multimodal tasks. Additionally, FinLLaMA achieves impressive Sharpe Ratios in trading simulations, highlighting its robust financial application capabilities. We will continually maintain and improve our models and benchmarks to support ongoing innovation in academia and industry.
Deja vu: Contrastive Historical Modeling with Prefix-tuning for Temporal Knowledge Graph Reasoning
Mar 25, 2024



Temporal Knowledge Graph Reasoning (TKGR) is the task of inferring missing facts for incomplete TKGs in complex scenarios (e.g., transductive and inductive settings), which has been gaining increasing attention. Recently, to mitigate dependence on structured connections in TKGs, text-based methods have been developed to utilize rich linguistic information from entity descriptions. However, suffering from the enormous parameters and inflexibility of pre-trained language models, existing text-based methods struggle to balance the textual knowledge and temporal information with computationally expensive purpose-built training strategies. To tap the potential of text-based models for TKGR in various complex scenarios, we propose ChapTER, a Contrastive historical modeling framework with prefix-tuning for TEmporal Reasoning. ChapTER feeds history-contextualized text into the pseudo-Siamese encoders to strike a textual-temporal balance via contrastive estimation between queries and candidates. By introducing virtual time prefix tokens, it applies a prefix-based tuning method to facilitate the frozen PLM capable for TKGR tasks under different settings. We evaluate ChapTER on four transductive and three few-shot inductive TKGR benchmarks, and experimental results demonstrate that ChapTER achieves superior performance compared to competitive baselines with only 0.17% tuned parameters. We conduct thorough analysis to verify the effectiveness, flexibility and efficiency of ChapTER.
No Language is an Island: Unifying Chinese and English in Financial Large Language Models, Instruction Data, and Benchmarks
Mar 10, 2024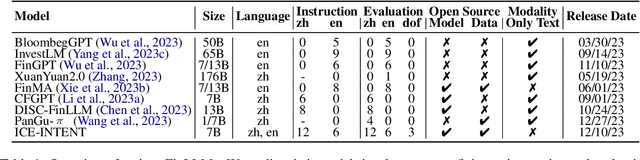
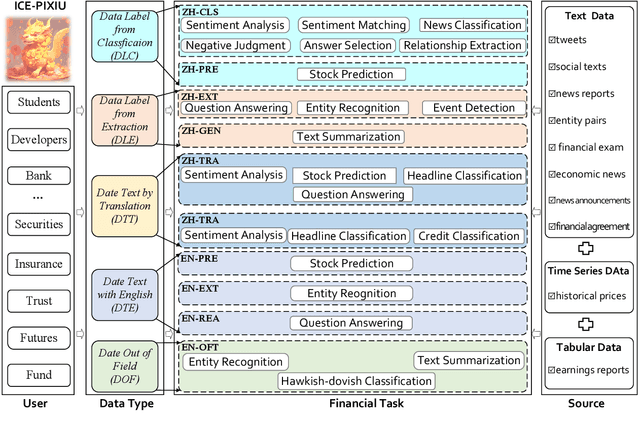
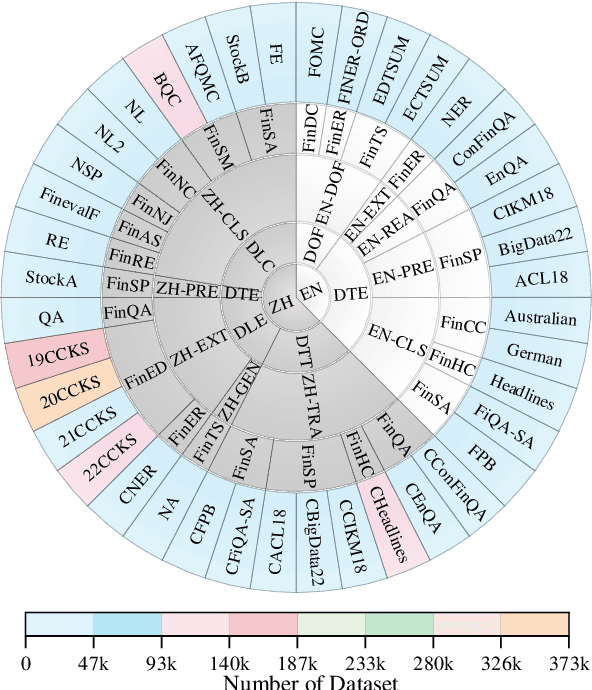
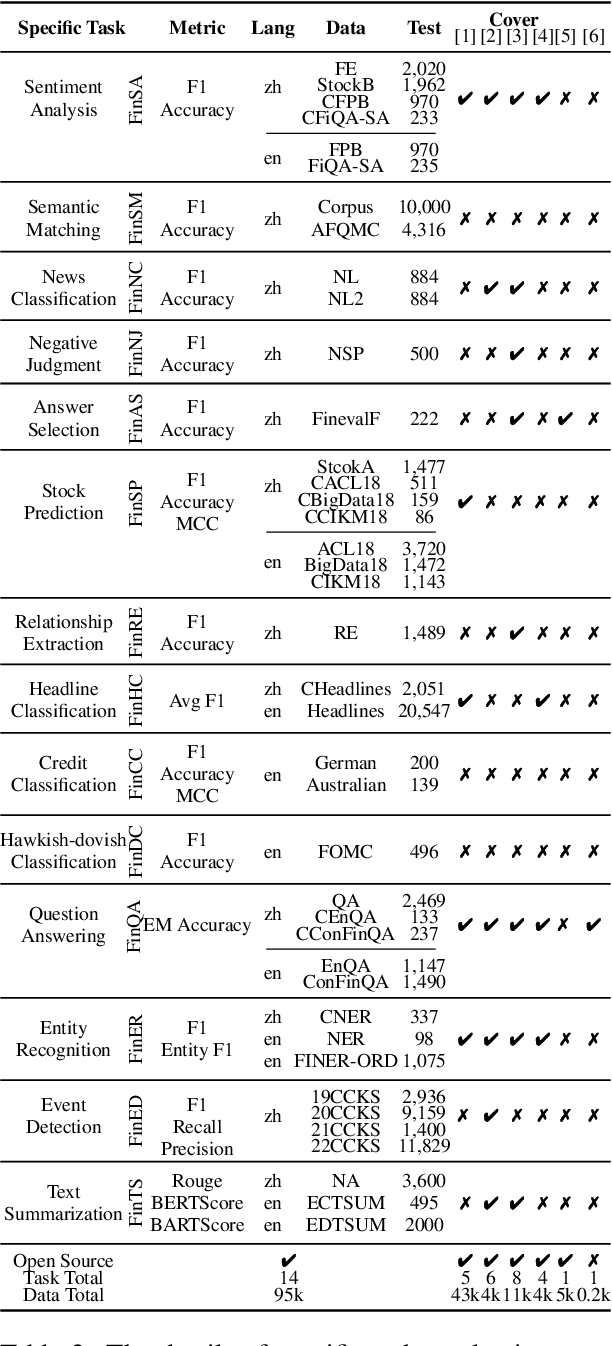
While the progression of Large Language Models (LLMs) has notably propelled financial analysis, their application has largely been confined to singular language realms, leaving untapped the potential of bilingual Chinese-English capacity. To bridge this chasm, we introduce ICE-PIXIU, seamlessly amalgamating the ICE-INTENT model and ICE-FLARE benchmark for bilingual financial analysis. ICE-PIXIU uniquely integrates a spectrum of Chinese tasks, alongside translated and original English datasets, enriching the breadth and depth of bilingual financial modeling. It provides unrestricted access to diverse model variants, a substantial compilation of diverse cross-lingual and multi-modal instruction data, and an evaluation benchmark with expert annotations, comprising 10 NLP tasks, 20 bilingual specific tasks, totaling 1,185k datasets. Our thorough evaluation emphasizes the advantages of incorporating these bilingual datasets, especially in translation tasks and utilizing original English data, enhancing both linguistic flexibility and analytical acuity in financial contexts. Notably, ICE-INTENT distinguishes itself by showcasing significant enhancements over conventional LLMs and existing financial LLMs in bilingual milieus, underscoring the profound impact of robust bilingual data on the accuracy and efficacy of financial NLP.