 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCTTA-T: Continual Test-Time Adaptation for Text Understanding via Teacher-Student with a Domain-aware and Generalized Teacher
Dec 20, 2025Text understanding often suffers from domain shifts. To handle testing domains, domain adaptation (DA) is trained to adapt to a fixed and observed testing domain; a more challenging paradigm, test-time adaptation (TTA), cannot access the testing domain during training and online adapts to the testing samples during testing, where the samples are from a fixed domain. We aim to explore a more practical and underexplored scenario, continual test-time adaptation (CTTA) for text understanding, which involves a sequence of testing (unobserved) domains in testing. Current CTTA methods struggle in reducing error accumulation over domains and enhancing generalization to handle unobserved domains: 1) Noise-filtering reduces accumulated errors but discards useful information, and 2) accumulating historical domains enhances generalization, but it is hard to achieve adaptive accumulation. In this paper, we propose a CTTA-T (continual test-time adaptation for text understanding) framework adaptable to evolving target domains: it adopts a teacher-student framework, where the teacher is domain-aware and generalized for evolving domains. To improve teacher predictions, we propose a refine-then-filter based on dropout-driven consistency, which calibrates predictions and removes unreliable guidance. For the adaptation-generalization trade-off, we construct a domain-aware teacher by dynamically accumulating cross-domain semantics via incremental PCA, which continuously tracks domain shifts. Experiments show CTTA-T excels baselines.
No Language is an Island: Unifying Chinese and English in Financial Large Language Models, Instruction Data, and Benchmarks
Mar 10, 2024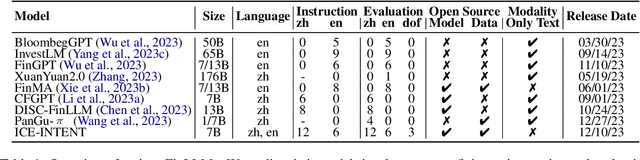
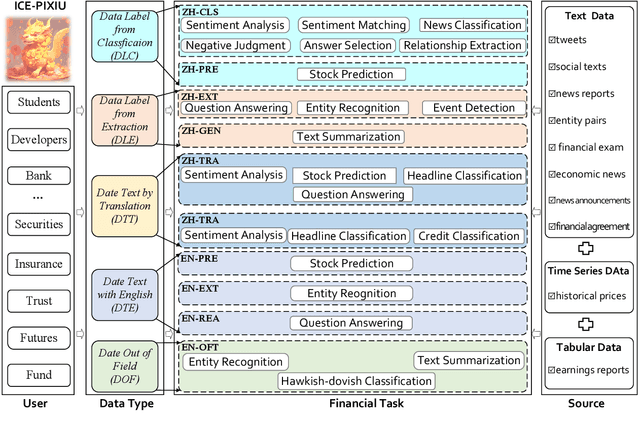
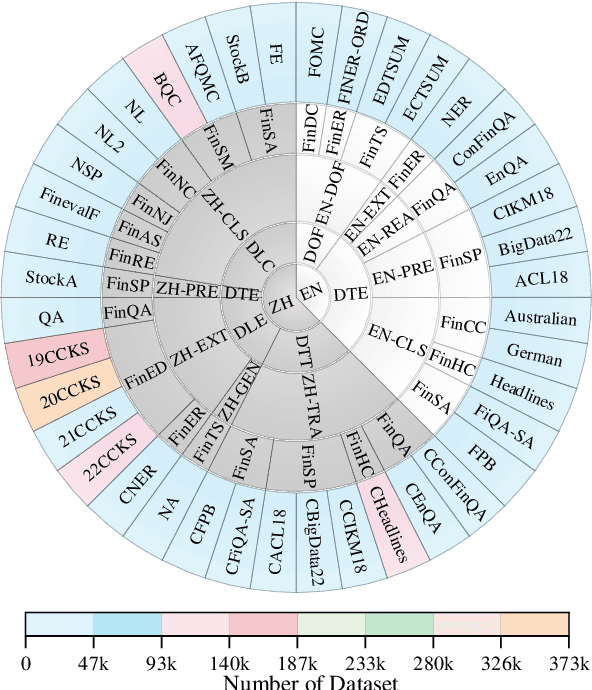
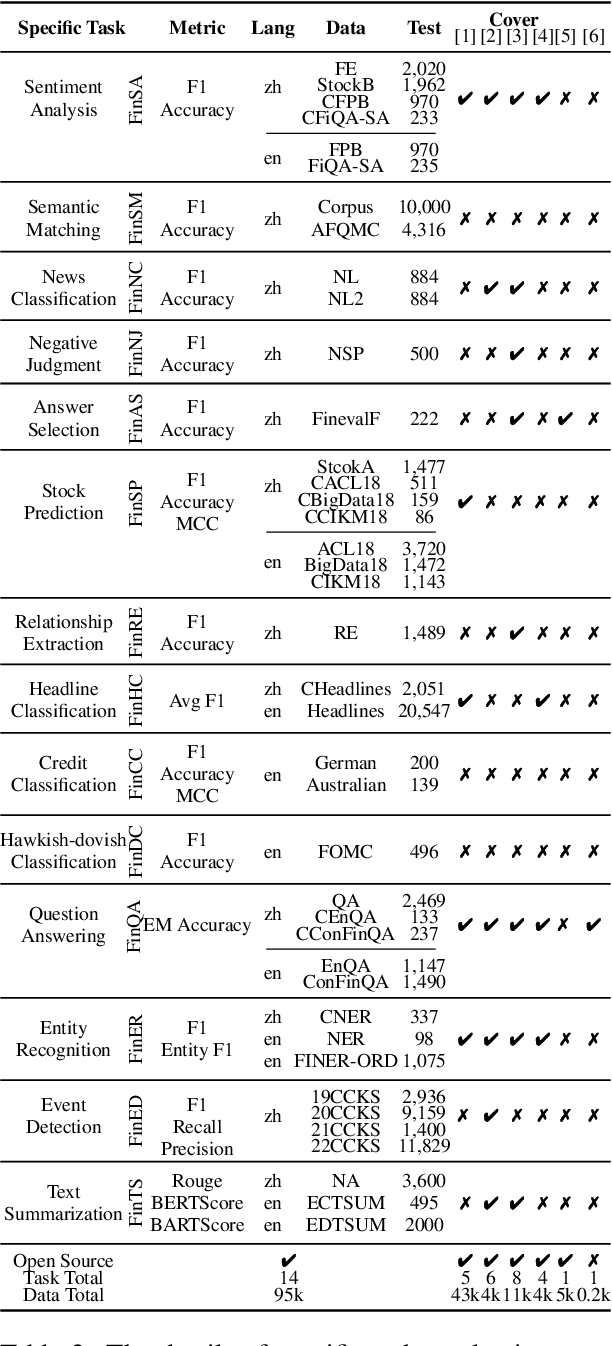
While the progression of Large Language Models (LLMs) has notably propelled financial analysis, their application has largely been confined to singular language realms, leaving untapped the potential of bilingual Chinese-English capacity. To bridge this chasm, we introduce ICE-PIXIU, seamlessly amalgamating the ICE-INTENT model and ICE-FLARE benchmark for bilingual financial analysis. ICE-PIXIU uniquely integrates a spectrum of Chinese tasks, alongside translated and original English datasets, enriching the breadth and depth of bilingual financial modeling. It provides unrestricted access to diverse model variants, a substantial compilation of diverse cross-lingual and multi-modal instruction data, and an evaluation benchmark with expert annotations, comprising 10 NLP tasks, 20 bilingual specific tasks, totaling 1,185k datasets. Our thorough evaluation emphasizes the advantages of incorporating these bilingual datasets, especially in translation tasks and utilizing original English data, enhancing both linguistic flexibility and analytical acuity in financial contexts. Notably, ICE-INTENT distinguishes itself by showcasing significant enhancements over conventional LLMs and existing financial LLMs in bilingual milieus, underscoring the profound impact of robust bilingual data on the accuracy and efficacy of financial NLP.