 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Provably Efficient Sample Collection Strategy for Reinforcement Learning
Jul 13, 2020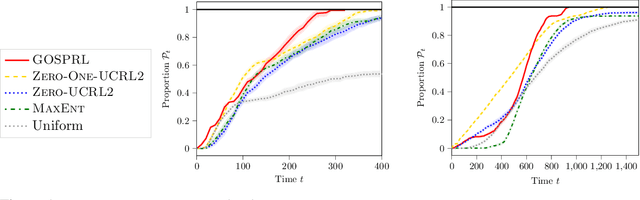
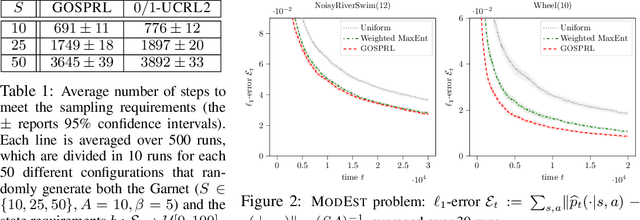
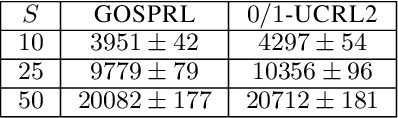
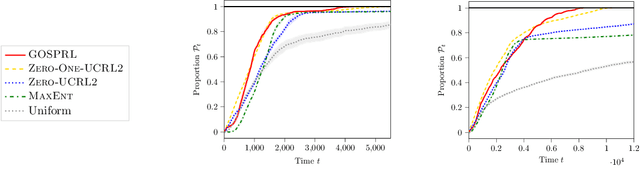
A common assumption in reinforcement learning (RL) is to have access to a generative model (i.e., a simulator of the environment), which allows to generate samples from any desired state-action pair. Nonetheless, in many settings a generative model may not be available and an adaptive exploration strategy is needed to efficiently collect samples from an unknown environment by direct interaction. In this paper, we study the scenario where an algorithm based on the generative model assumption defines the (possibly time-varying) amount of samples $b(s,a)$ required at each state-action pair $(s,a)$ and an exploration strategy has to learn how to generate $b(s,a)$ samples as fast as possible. Building on recent results for regret minimization in the stochastic shortest path (SSP) setting (Cohen et al., 2020; Tarbouriech et al., 2020), we derive an algorithm that requires $\tilde{O}( B D + D^{3/2} S^2 A)$ time steps to collect the $B = \sum_{s,a} b(s,a)$ desired samples, in any unknown and communicating MDP with $S$ states, $A$ actions and diameter $D$. Leveraging the generality of our strategy, we readily apply it to a variety of existing settings (e.g., model estimation, pure exploration in MDPs) for which we obtain improved sample-complexity guarantees, and to a set of new problems such as best-state identification and sparse reward discovery.
A Kernel-Based Approach to Non-Stationary Reinforcement Learning in Metric Spaces
Jul 09, 2020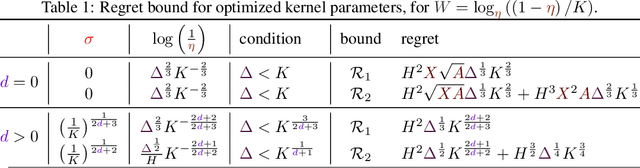
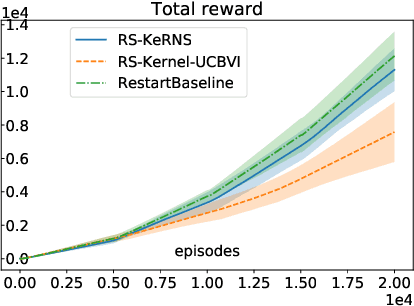


In this work, we propose KeRNS: an algorithm for episodic reinforcement learning in non-stationary Markov Decision Processes (MDPs) whose state-action set is endowed with a metric. Using a non-parametric model of the MDP built with time-dependent kernels, we prove a regret bound that scales with the covering dimension of the state-action space and the total variation of the MDP with time, which quantifies its level of non-stationarity. Our method generalizes previous approaches based on sliding windows and exponential discounting used to handle changing environments. We further propose a practical implementation of KeRNS, we analyze its regret and validate it experimentally.
Gamification of Pure Exploration for Linear Bandits
Jul 02, 2020

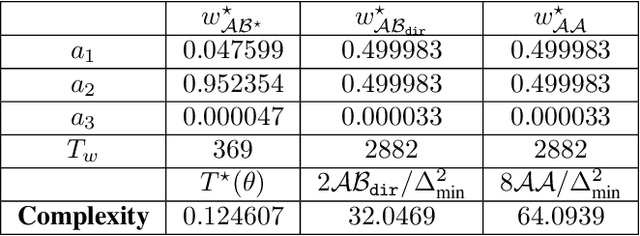
We investigate an active pure-exploration setting, that includes best-arm identification, in the context of linear stochastic bandits. While asymptotically optimal algorithms exist for standard multi-arm bandits, the existence of such algorithms for the best-arm identification in linear bandits has been elusive despite several attempts to address it. First, we provide a thorough comparison and new insight over different notions of optimality in the linear case, including G-optimality, transductive optimality from optimal experimental design and asymptotic optimality. Second, we design the first asymptotically optimal algorithm for fixed-confidence pure exploration in linear bandits. As a consequence, our algorithm naturally bypasses the pitfall caused by a simple but difficult instance, that most prior algorithms had to be engineered to deal with explicitly. Finally, we avoid the need to fully solve an optimal design problem by providing an approach that entails an efficient implementation.
Sampling from a $k$-DPP without looking at all items
Jun 30, 2020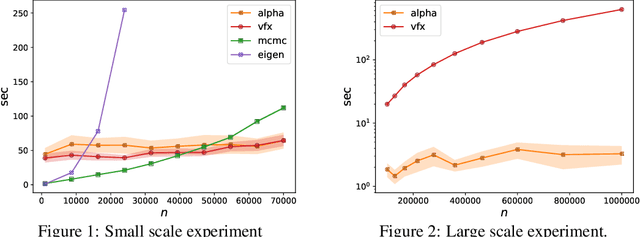
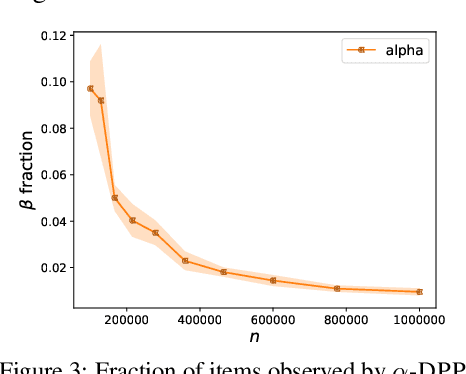
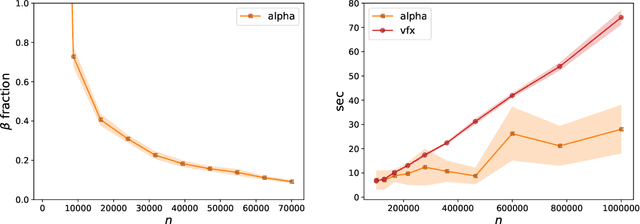
Determinantal point processes (DPPs) are a useful probabilistic model for selecting a small diverse subset out of a large collection of items, with applications in summarization, stochastic optimization, active learning and more. Given a kernel function and a subset size $k$, our goal is to sample $k$ out of $n$ items with probability proportional to the determinant of the kernel matrix induced by the subset (a.k.a. $k$-DPP). Existing $k$-DPP sampling algorithms require an expensive preprocessing step which involves multiple passes over all $n$ items, making it infeasible for large datasets. A na\"ive heuristic addressing this problem is to uniformly subsample a fraction of the data and perform $k$-DPP sampling only on those items, however this method offers no guarantee that the produced sample will even approximately resemble the target distribution over the original dataset. In this paper, we develop an algorithm which adaptively builds a sufficiently large uniform sample of data that is then used to efficiently generate a smaller set of $k$ items, while ensuring that this set is drawn exactly from the target distribution defined on all $n$ items. We show empirically that our algorithm produces a $k$-DPP sample after observing only a small fraction of all elements, leading to several orders of magnitude faster performance compared to the state-of-the-art.
Stochastic bandits with arm-dependent delays
Jun 18, 2020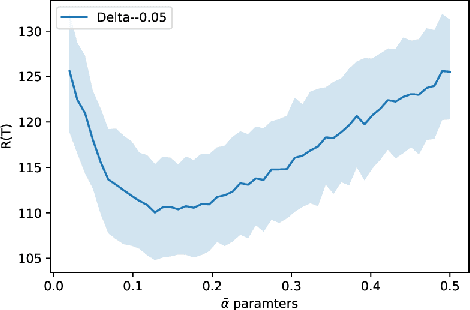
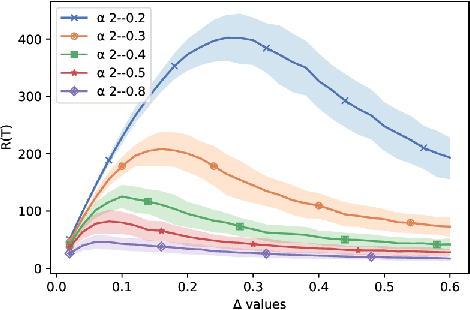
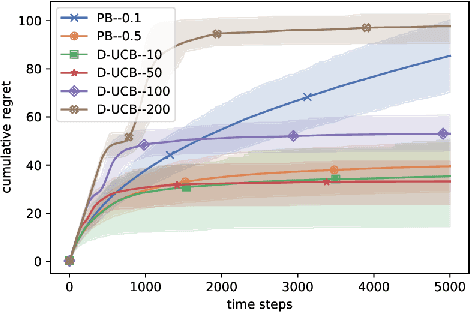
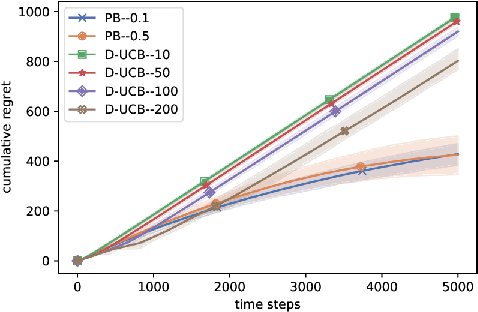
Significant work has been recently dedicated to the stochastic delayed bandit setting because of its relevance in applications. The applicability of existing algorithms is however restricted by the fact that strong assumptions are often made on the delay distributions, such as full observability, restrictive shape constraints, or uniformity over arms. In this work, we weaken them significantly and only assume that there is a bound on the tail of the delay. In particular, we cover the important case where the delay distributions vary across arms, and the case where the delays are heavy-tailed. Addressing these difficulties, we propose a simple but efficient UCB-based algorithm called the PatientBandits. We provide both problems-dependent and problems-independent bounds on the regret as well as performance lower bounds.
Bootstrap Your Own Latent: A New Approach to Self-Supervised Learning
Jun 13, 2020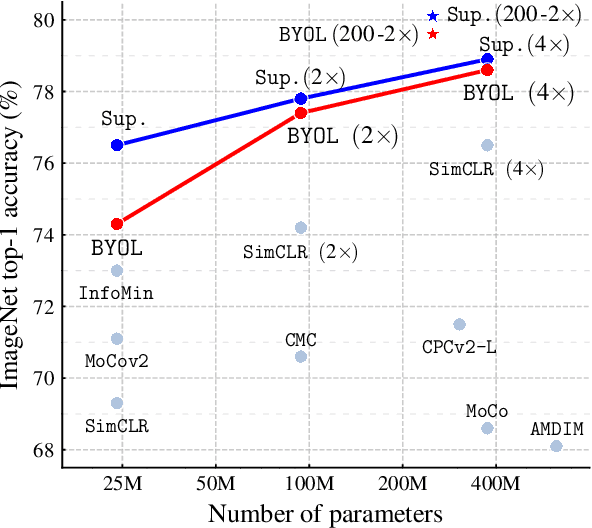

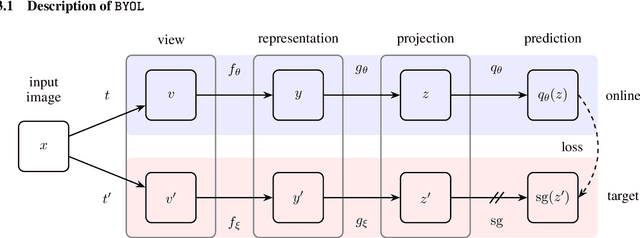
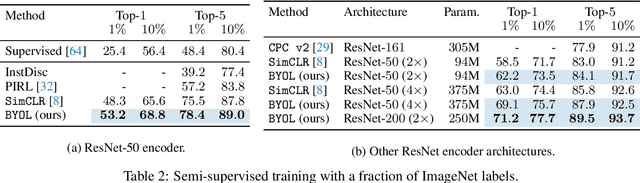
We introduce Bootstrap Your Own Latent (BYOL), a new approach to self-supervised image representation learning. BYOL relies on two neural networks, referred to as online and target networks, that interact and learn from each other. From an augmented view of an image, we train the online network to predict the target network representation of the same image under a different augmented view. At the same time, we update the target network with a slow-moving average of the online network. While state-of-the art methods intrinsically rely on negative pairs, BYOL achieves a new state of the art without them. BYOL reaches $74.3\%$ top-1 classification accuracy on ImageNet using the standard linear evaluation protocol with a ResNet-50 architecture and $79.6\%$ with a larger ResNet. We show that BYOL performs on par or better than the current state of the art on both transfer and semi-supervised benchmarks.
Statistical Efficiency of Thompson Sampling for Combinatorial Semi-Bandits
Jun 11, 2020
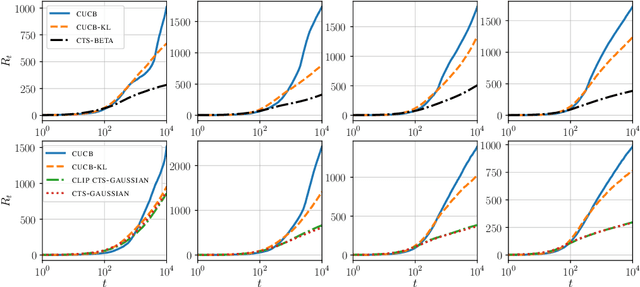
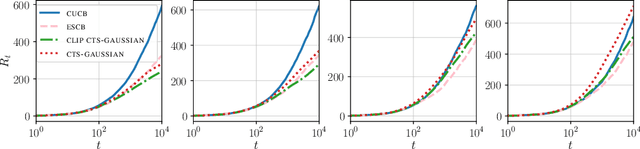
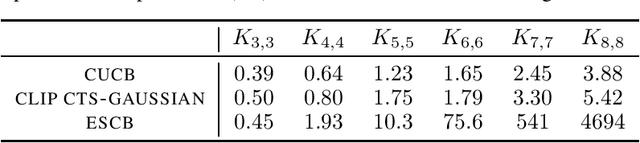
We investigate stochastic combinatorial multi-armed bandit with semi-bandit feedback (CMAB). In CMAB, the question of the existence of an efficient policy with an optimal asymptotic regret (up to a factor poly-logarithmic with the action size) is still open for many families of distributions, including mutually independent outcomes, and more generally the multivariate sub-Gaussian family. We propose to answer the above question for these two families by analyzing variants of the Combinatorial Thompson Sampling policy (CTS). For mutually independent outcomes in $[0,1]$, we propose a tight analysis of CTS using Beta priors. We then look at the more general setting of multivariate sub-Gaussian outcomes and propose a tight analysis of CTS using Gaussian priors. This last result gives us an alternative to the Efficient Sampling for Combinatorial Bandit policy (ESCB), which, although optimal, is not computationally efficient.
Adaptive Reward-Free Exploration
Jun 11, 2020
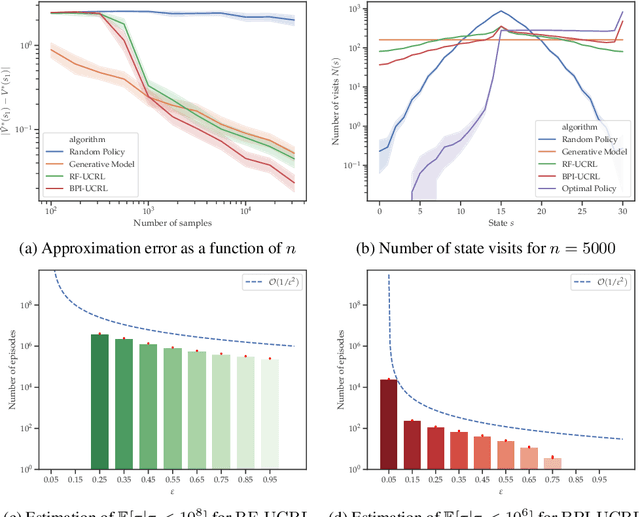
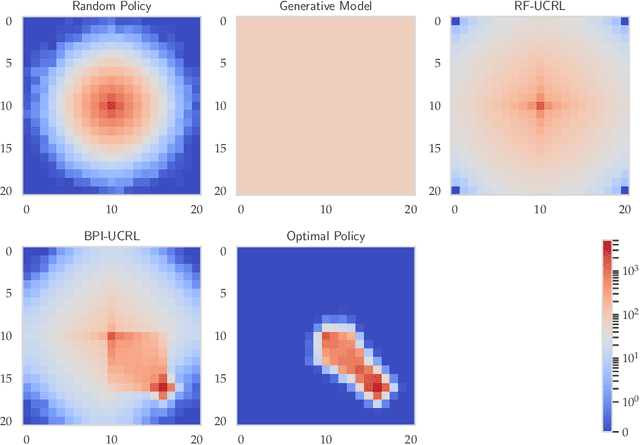
Reward-free exploration is a reinforcement learning setting recently studied by Jin et al., who address it by running several algorithms with regret guarantees in parallel. In our work, we instead propose a more adaptive approach for reward-free exploration which directly reduces upper bounds on the maximum MDP estimation error. We show that, interestingly, our reward-free UCRL algorithm can be seen as a variant of an algorithm of Fiechter from 1994, originally proposed for a different objective that we call best-policy identification. We prove that RF-UCRL needs $\mathcal{O}\left(({SAH^4}/{\varepsilon^2})\ln(1/\delta)\right)$ episodes to output, with probability $1-\delta$, an $\varepsilon$-approximation of the optimal policy for any reward function. We empirically compare it to oracle strategies using a generative model.
Planning in Markov Decision Processes with Gap-Dependent Sample Complexity
Jun 10, 2020
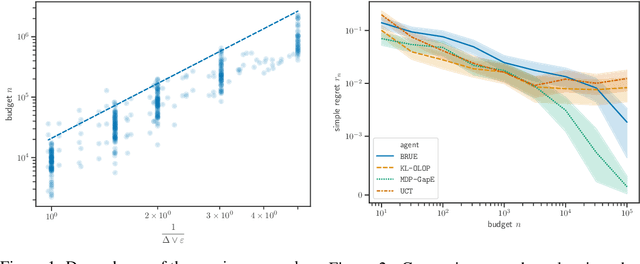


We propose MDP-GapE, a new trajectory-based Monte-Carlo Tree Search algorithm for planning in a Markov Decision Process in which transitions have a finite support. We prove an upper bound on the number of calls to the generative models needed for MDP-GapE to identify a near-optimal action with high probability. This problem-dependent sample complexity result is expressed in terms of the sub-optimality gaps of the state-action pairs that are visited during exploration. Our experiments reveal that MDP-GapE is also effective in practice, in contrast with other algorithms with sample complexity guarantees in the fixed-confidence setting, that are mostly theoretical.
Regret Bounds for Kernel-Based Reinforcement Learning
Apr 12, 2020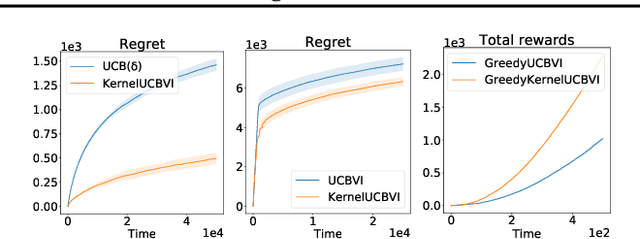

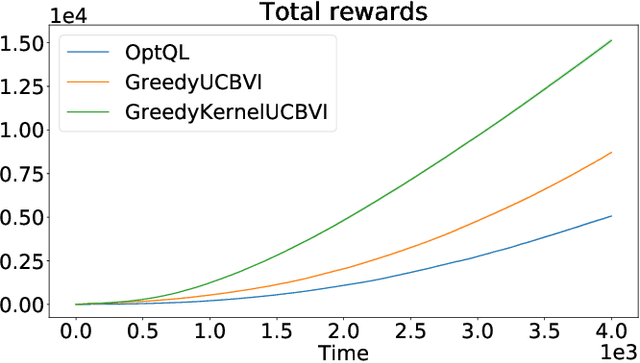
We consider the exploration-exploitation dilemma in finite-horizon reinforcement learning problems whose state-action space is endowed with a metric. We introduce Kernel-UCBVI, a model-based optimistic algorithm that leverages the smoothness of the MDP and a non-parametric kernel estimator of the rewards and transitions to efficiently balance exploration and exploitation. Unlike existing approaches with regret guarantees, it does not use any kind of partitioning of the state-action space. For problems with $K$ episodes and horizon $H$, we provide a regret bound of $O\left( H^3 K^{\max\left(\frac{1}{2}, \frac{2d}{2d+1}\right)}\right)$, where $d$ is the covering dimension of the joint state-action space. We empirically validate Kernel-UCBVI on discrete and continuous MDPs.