 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBudgeted Online Influence Maximization
Apr 21, 2026We introduce a new budgeted framework for online influence maximization, considering the total cost of an advertising campaign instead of the common cardinality constraint on a chosen influencer set. Our approach better models the real-world setting where the cost of influencers varies and advertisers want to find the best value for their overall social advertising budget. We propose an algorithm assuming an independent cascade diffusion model and edge level semi-bandit feedback, and provide both theoretical and experimental results. Our analysis is also valid for the cardinality constraint setting and improves the state of the art regret bound in this case.
Covariance-adapting algorithm for semi-bandits with application to sparse rewards
Apr 15, 2026We investigate stochastic combinatorial semi-bandits, where the entire joint distribution of outcomes impacts the complexity of the problem instance (unlike in the standard bandits). Typical distributions considered depend on specific parameter values, whose prior knowledge is required in theory but quite difficult to estimate in practice; an example is the commonly assumed sub-Gaussian family. We alleviate this issue by instead considering a new general family of sub-exponential distributions, which contains bounded and Gaussian ones. We prove a new lower bound on the expected regret on this family, that is parameterized by the unknown covariance matrix of outcomes, a tighter quantity than the sub-Gaussian matrix. We then construct an algorithm that uses covariance estimates, and provide a tight asymptotic analysis of the regret. Finally, we apply and extend our results to the family of sparse outcomes, which has applications in many recommender systems.
* Published at Conference on Learning Theory (COLT) 2020
Sharper Perturbed-Kullback-Leibler Exponential Tail Bounds for Beta and Dirichlet Distributions
Aug 11, 2025This paper presents an improved exponential tail bound for Beta distributions, refining a result in [15]. This improvement is achieved by interpreting their bound as a regular Kullback-Leibler (KL) divergence one, while introducing a specific perturbation $\eta$ that shifts the mean of the Beta distribution closer to zero within the KL bound. Our contribution is to show that a larger perturbation can be chosen, thereby tightening the bound. We then extend this result from the Beta distribution to Dirichlet distributions and Dirichlet processes (DPs).
Limitations of (Procrustes) Alignment in Assessing Multi-Person Human Pose and Shape Estimation
Sep 25, 2024



We delve into the challenges of accurately estimating 3D human pose and shape in video surveillance scenarios. Beginning with the advocacy for metrics like W-MPJPE and W-PVE, which omit the (Procrustes) realignment step, to improve model evaluation, we then introduce RotAvat. This technique aims to enhance these metrics by refining the alignment of 3D meshes with the ground plane. Through qualitative comparisons, we demonstrate RotAvat's effectiveness in addressing the limitations of existing aproaches.
Model-free Posterior Sampling via Learning Rate Randomization
Oct 27, 2023



In this paper, we introduce Randomized Q-learning (RandQL), a novel randomized model-free algorithm for regret minimization in episodic Markov Decision Processes (MDPs). To the best of our knowledge, RandQL is the first tractable model-free posterior sampling-based algorithm. We analyze the performance of RandQL in both tabular and non-tabular metric space settings. In tabular MDPs, RandQL achieves a regret bound of order $\widetilde{\mathcal{O}}(\sqrt{H^{5}SAT})$, where $H$ is the planning horizon, $S$ is the number of states, $A$ is the number of actions, and $T$ is the number of episodes. For a metric state-action space, RandQL enjoys a regret bound of order $\widetilde{\mathcal{O}}(H^{5/2} T^{(d_z+1)/(d_z+2)})$, where $d_z$ denotes the zooming dimension. Notably, RandQL achieves optimistic exploration without using bonuses, relying instead on a novel idea of learning rate randomization. Our empirical study shows that RandQL outperforms existing approaches on baseline exploration environments.
Demonstration-Regularized RL
Oct 26, 2023
Incorporating expert demonstrations has empirically helped to improve the sample efficiency of reinforcement learning (RL). This paper quantifies theoretically to what extent this extra information reduces RL's sample complexity. In particular, we study the demonstration-regularized reinforcement learning that leverages the expert demonstrations by KL-regularization for a policy learned by behavior cloning. Our findings reveal that using $N^{\mathrm{E}}$ expert demonstrations enables the identification of an optimal policy at a sample complexity of order $\widetilde{\mathcal{O}}(\mathrm{Poly}(S,A,H)/(\varepsilon^2 N^{\mathrm{E}}))$ in finite and $\widetilde{\mathcal{O}}(\mathrm{Poly}(d,H)/(\varepsilon^2 N^{\mathrm{E}}))$ in linear Markov decision processes, where $\varepsilon$ is the target precision, $H$ the horizon, $A$ the number of action, $S$ the number of states in the finite case and $d$ the dimension of the feature space in the linear case. As a by-product, we provide tight convergence guarantees for the behaviour cloning procedure under general assumptions on the policy classes. Additionally, we establish that demonstration-regularized methods are provably efficient for reinforcement learning from human feedback (RLHF). In this respect, we provide theoretical evidence showing the benefits of KL-regularization for RLHF in tabular and linear MDPs. Interestingly, we avoid pessimism injection by employing computationally feasible regularization to handle reward estimation uncertainty, thus setting our approach apart from the prior works.
Fast Rates for Maximum Entropy Exploration
Mar 14, 2023



We consider the reinforcement learning (RL) setting, in which the agent has to act in unknown environment driven by a Markov Decision Process (MDP) with sparse or even reward free signals. In this situation, exploration becomes the main challenge. In this work, we study the maximum entropy exploration problem of two different types. The first type is visitation entropy maximization that was previously considered by Hazan et al. (2019) in the discounted setting. For this type of exploration, we propose an algorithm based on a game theoretic representation that has $\widetilde{\mathcal{O}}(H^3 S^2 A / \varepsilon^2)$ sample complexity thus improving the $\varepsilon$-dependence of Hazan et al. (2019), where $S$ is a number of states, $A$ is a number of actions, $H$ is an episode length, and $\varepsilon$ is a desired accuracy. The second type of entropy we study is the trajectory entropy. This objective function is closely related to the entropy-regularized MDPs, and we propose a simple modification of the UCBVI algorithm that has a sample complexity of order $\widetilde{\mathcal{O}}(1/\varepsilon)$ ignoring dependence in $S, A, H$. Interestingly enough, it is the first theoretical result in RL literature establishing that the exploration problem for the regularized MDPs can be statistically strictly easier (in terms of sample complexity) than for the ordinary MDPs.
When Combinatorial Thompson Sampling meets Approximation Regret
Feb 22, 2023We study the Combinatorial Thompson Sampling policy (CTS) for combinatorial multi-armed bandit problems (CMAB), within an approximation regret setting. Although CTS has attracted a lot of interest, it has a drawback that other usual CMAB policies do not have when considering non-exact oracles: for some oracles, CTS has a poor approximation regret (scaling linearly with the time horizon $T$) [Wang and Chen, 2018]. A study is then necessary to discriminate the oracles on which CTS could learn. This study was started by Kong et al. [2021]: they gave the first approximation regret analysis of CTS for the greedy oracle, obtaining an upper bound of order $\mathcal{O}(\log(T)/\Delta^2)$, where $\Delta$ is some minimal reward gap. In this paper, our objective is to push this study further than the simple case of the greedy oracle. We provide the first $\mathcal{O}(\log(T)/\Delta)$ approximation regret upper bound for CTS, obtained under a specific condition on the approximation oracle, allowing a reduction to the exact oracle analysis. We thus term this condition REDUCE2EXACT, and observe that it is satisfied in many concrete examples. Moreover, it can be extended to the probabilistically triggered arms setting, thus capturing even more problems, such as online influence maximization.
Statistical Efficiency of Thompson Sampling for Combinatorial Semi-Bandits
Jun 11, 2020
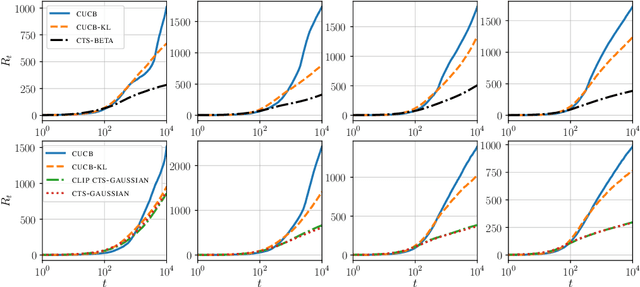
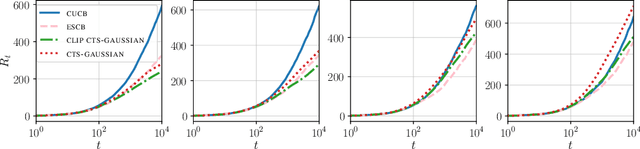
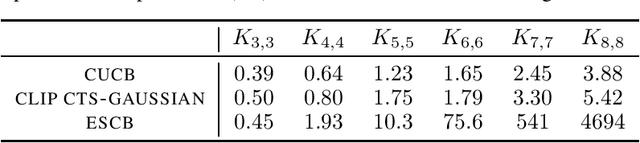
We investigate stochastic combinatorial multi-armed bandit with semi-bandit feedback (CMAB). In CMAB, the question of the existence of an efficient policy with an optimal asymptotic regret (up to a factor poly-logarithmic with the action size) is still open for many families of distributions, including mutually independent outcomes, and more generally the multivariate sub-Gaussian family. We propose to answer the above question for these two families by analyzing variants of the Combinatorial Thompson Sampling policy (CTS). For mutually independent outcomes in $[0,1]$, we propose a tight analysis of CTS using Beta priors. We then look at the more general setting of multivariate sub-Gaussian outcomes and propose a tight analysis of CTS using Gaussian priors. This last result gives us an alternative to the Efficient Sampling for Combinatorial Bandit policy (ESCB), which, although optimal, is not computationally efficient.
Active Linear Regression
Jun 20, 2019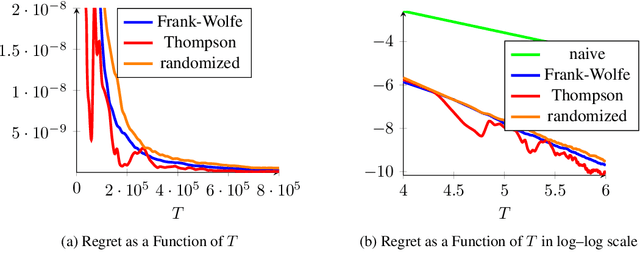
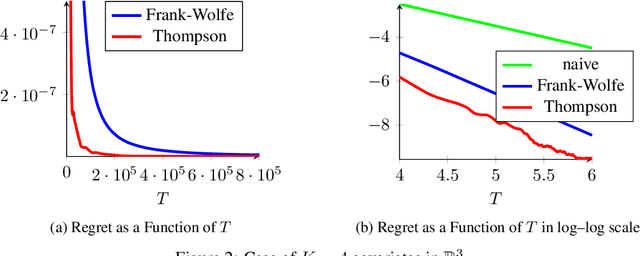
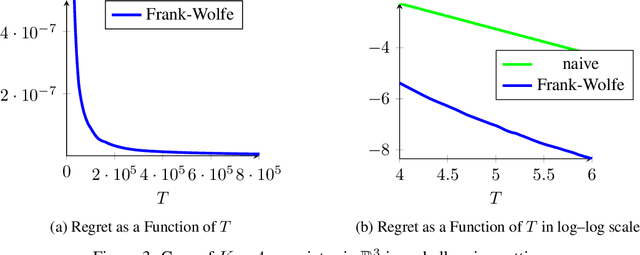
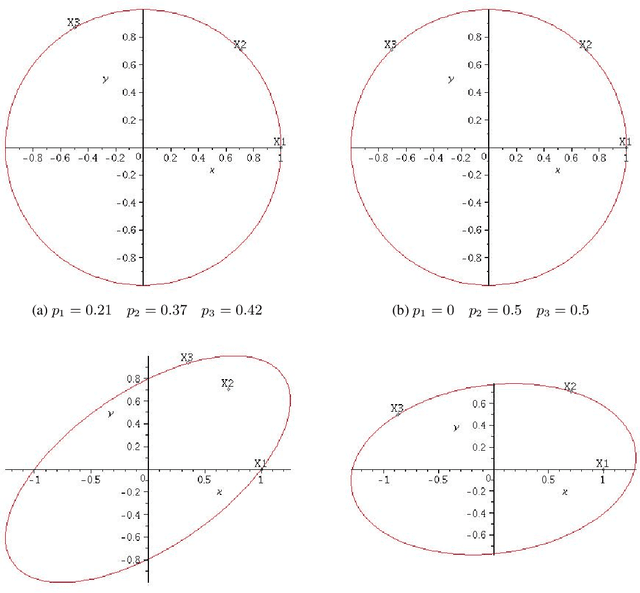
We consider the problem of active linear regression where a decision maker has to choose between several covariates to sample in order to obtain the best estimate $\hat{\beta}$ of the parameter $\beta^{\star}$ of the linear model, in the sense of minimizing $\mathbb{E} \lVert\hat{\beta}-\beta^{\star}\rVert^2$. Using bandit and convex optimization techniques we propose an algorithm to define the sampling strategy of the decision maker and we compare it with other algorithms. We provide theoretical guarantees of our algorithm in different settings, including a $\mathcal{O}(T^{-2})$ regret bound in the case where the covariates form a basis of the feature space, generalizing and improving existing results. Numerical experiments validate our theoretical findings.