 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMAMMA: Markerless & Automatic Multi-Person Motion Action Capture
Jun 16, 2025We present MAMMA, a markerless motion-capture pipeline that accurately recovers SMPL-X parameters from multi-view video of two-person interaction sequences. Traditional motion-capture systems rely on physical markers. Although they offer high accuracy, their requirements of specialized hardware, manual marker placement, and extensive post-processing make them costly and time-consuming. Recent learning-based methods attempt to overcome these limitations, but most are designed for single-person capture, rely on sparse keypoints, or struggle with occlusions and physical interactions. In this work, we introduce a method that predicts dense 2D surface landmarks conditioned on segmentation masks, enabling person-specific correspondence estimation even under heavy occlusion. We employ a novel architecture that exploits learnable queries for each landmark. We demonstrate that our approach can handle complex person--person interaction and offers greater accuracy than existing methods. To train our network, we construct a large, synthetic multi-view dataset combining human motions from diverse sources, including extreme poses, hand motions, and close interactions. Our dataset yields high-variability synthetic sequences with rich body contact and occlusion, and includes SMPL-X ground-truth annotations with dense 2D landmarks. The result is a system capable of capturing human motion without the need for markers. Our approach offers competitive reconstruction quality compared to commercial marker-based motion-capture solutions, without the extensive manual cleanup. Finally, we address the absence of common benchmarks for dense-landmark prediction and markerless motion capture by introducing two evaluation settings built from real multi-view sequences. We will release our dataset, benchmark, method, training code, and pre-trained model weights for research purposes.
NIL: No-data Imitation Learning by Leveraging Pre-trained Video Diffusion Models
Mar 13, 2025



Acquiring physically plausible motor skills across diverse and unconventional morphologies-including humanoid robots, quadrupeds, and animals-is essential for advancing character simulation and robotics. Traditional methods, such as reinforcement learning (RL) are task- and body-specific, require extensive reward function engineering, and do not generalize well. Imitation learning offers an alternative but relies heavily on high-quality expert demonstrations, which are difficult to obtain for non-human morphologies. Video diffusion models, on the other hand, are capable of generating realistic videos of various morphologies, from humans to ants. Leveraging this capability, we propose a data-independent approach for skill acquisition that learns 3D motor skills from 2D-generated videos, with generalization capability to unconventional and non-human forms. Specifically, we guide the imitation learning process by leveraging vision transformers for video-based comparisons by calculating pair-wise distance between video embeddings. Along with video-encoding distance, we also use a computed similarity between segmented video frames as a guidance reward. We validate our method on locomotion tasks involving unique body configurations. In humanoid robot locomotion tasks, we demonstrate that 'No-data Imitation Learning' (NIL) outperforms baselines trained on 3D motion-capture data. Our results highlight the potential of leveraging generative video models for physically plausible skill learning with diverse morphologies, effectively replacing data collection with data generation for imitation learning.
Toward Human Understanding with Controllable Synthesis
Nov 13, 2024



Training methods to perform robust 3D human pose and shape (HPS) estimation requires diverse training images with accurate ground truth. While BEDLAM demonstrates the potential of traditional procedural graphics to generate such data, the training images are clearly synthetic. In contrast, generative image models produce highly realistic images but without ground truth. Putting these methods together seems straightforward: use a generative model with the body ground truth as controlling signal. However, we find that, the more realistic the generated images, the more they deviate from the ground truth, making them inappropriate for training and evaluation. Enhancements of realistic details, such as clothing and facial expressions, can lead to subtle yet significant deviations from the ground truth, potentially misleading training models. We empirically verify that this misalignment causes the accuracy of HPS networks to decline when trained with generated images. To address this, we design a controllable synthesis method that effectively balances image realism with precise ground truth. We use this to create the Generative BEDLAM (Gen-B) dataset, which improves the realism of the existing synthetic BEDLAM dataset while preserving ground truth accuracy. We perform extensive experiments, with various noise-conditioning strategies, to evaluate the tradeoff between visual realism and HPS accuracy. We show, for the first time, that generative image models can be controlled by traditional graphics methods to produce training data that increases the accuracy of HPS methods.
OpenCapBench: A Benchmark to Bridge Pose Estimation and Biomechanics
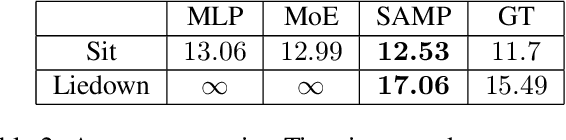
Jun 14, 2024Pose estimation has promised to impact healthcare by enabling more practical methods to quantify nuances of human movement and biomechanics. However, despite the inherent connection between pose estimation and biomechanics, these disciplines have largely remained disparate. For example, most current pose estimation benchmarks use metrics such as Mean Per Joint Position Error, Percentage of Correct Keypoints, or mean Average Precision to assess performance, without quantifying kinematic and physiological correctness - key aspects for biomechanics. To alleviate this challenge, we develop OpenCapBench to offer an easy-to-use unified benchmark to assess common tasks in human pose estimation, evaluated under physiological constraints. OpenCapBench computes consistent kinematic metrics through joints angles provided by an open-source musculoskeletal modeling software (OpenSim). Through OpenCapBench, we demonstrate that current pose estimation models use keypoints that are too sparse for accurate biomechanics analysis. To mitigate this challenge, we introduce SynthPose, a new approach that enables finetuning of pre-trained 2D human pose models to predict an arbitrarily denser set of keypoints for accurate kinematic analysis through the use of synthetic data. Incorporating such finetuning on synthetic data of prior models leads to twofold reduced joint angle errors. Moreover, OpenCapBench allows users to benchmark their own developed models on our clinically relevant cohort. Overall, OpenCapBench bridges the computer vision and biomechanics communities, aiming to drive simultaneous advances in both areas.
Generative Proxemics: A Prior for 3D Social Interaction from Images
Jun 15, 2023Social interaction is a fundamental aspect of human behavior and communication. The way individuals position themselves in relation to others, also known as proxemics, conveys social cues and affects the dynamics of social interaction. We present a novel approach that learns a 3D proxemics prior of two people in close social interaction. Since collecting a large 3D dataset of interacting people is a challenge, we rely on 2D image collections where social interactions are abundant. We achieve this by reconstructing pseudo-ground truth 3D meshes of interacting people from images with an optimization approach using existing ground-truth contact maps. We then model the proxemics using a novel denoising diffusion model called BUDDI that learns the joint distribution of two people in close social interaction directly in the SMPL-X parameter space. Sampling from our generative proxemics model produces realistic 3D human interactions, which we validate through a user study. Additionally, we introduce a new optimization method that uses the diffusion prior to reconstruct two people in close proximity from a single image without any contact annotation. Our approach recovers more accurate and plausible 3D social interactions from noisy initial estimates and outperforms state-of-the-art methods. See our project site for code, data, and model: muelea.github.io/buddi.
Synthesizing Physical Character-Scene Interactions
Feb 02, 2023Movement is how people interact with and affect their environment. For realistic character animation, it is necessary to synthesize such interactions between virtual characters and their surroundings. Despite recent progress in character animation using machine learning, most systems focus on controlling an agent's movements in fairly simple and homogeneous environments, with limited interactions with other objects. Furthermore, many previous approaches that synthesize human-scene interactions require significant manual labeling of the training data. In contrast, we present a system that uses adversarial imitation learning and reinforcement learning to train physically-simulated characters that perform scene interaction tasks in a natural and life-like manner. Our method learns scene interaction behaviors from large unstructured motion datasets, without manual annotation of the motion data. These scene interactions are learned using an adversarial discriminator that evaluates the realism of a motion within the context of a scene. The key novelty involves conditioning both the discriminator and the policy networks on scene context. We demonstrate the effectiveness of our approach through three challenging scene interaction tasks: carrying, sitting, and lying down, which require coordination of a character's movements in relation to objects in the environment. Our policies learn to seamlessly transition between different behaviors like idling, walking, and sitting. By randomizing the properties of the objects and their placements during training, our method is able to generalize beyond the objects and scenarios depicted in the training dataset, producing natural character-scene interactions for a wide variety of object shapes and placements. The approach takes physics-based character motion generation a step closer to broad applicability.
Stochastic Scene-Aware Motion Prediction
Aug 18, 2021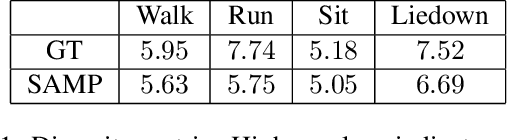


A long-standing goal in computer vision is to capture, model, and realistically synthesize human behavior. Specifically, by learning from data, our goal is to enable virtual humans to navigate within cluttered indoor scenes and naturally interact with objects. Such embodied behavior has applications in virtual reality, computer games, and robotics, while synthesized behavior can be used as a source of training data. This is challenging because real human motion is diverse and adapts to the scene. For example, a person can sit or lie on a sofa in many places and with varying styles. It is necessary to model this diversity when synthesizing virtual humans that realistically perform human-scene interactions. We present a novel data-driven, stochastic motion synthesis method that models different styles of performing a given action with a target object. Our method, called SAMP, for Scene-Aware Motion Prediction, generalizes to target objects of various geometries while enabling the character to navigate in cluttered scenes. To train our method, we collected MoCap data covering various sitting, lying down, walking, and running styles. We demonstrate our method on complex indoor scenes and achieve superior performance compared to existing solutions. Our code and data are available for research at https://samp.is.tue.mpg.de.
GIF: Generative Interpretable Faces
Aug 31, 2020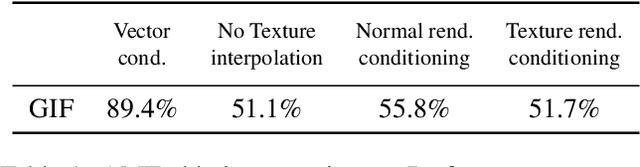
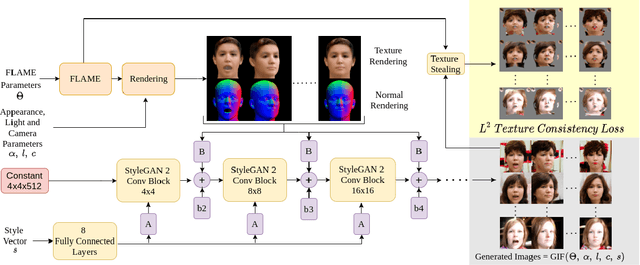
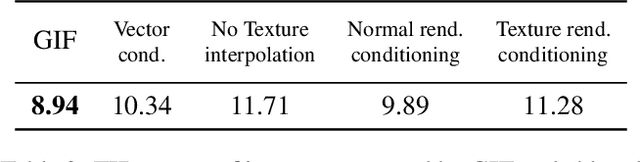

Photo-realistic visualization and animation of expressive human faces have been a long standing challenge. On one end of the spectrum, 3D face modeling methods provide parametric control but tend to generate unrealistic images, while on the other end, generative 2D models like GANs (Generative Adversarial Networks) output photo-realistic face images, but lack explicit control. Recent methods gain partial control, either by attempting to disentangle different factors in an unsupervised manner, or by adding control post hoc to a pre-trained model. Trained GANs without pre-defined control, however, may entangle factors that are hard to undo later. To guarantee some disentanglement that provides us with desired kinds of control, we train our generative model conditioned on pre-defined control parameters. Specifically, we condition StyleGAN2 on FLAME, a generative 3D face model. However, we found out that a naive conditioning on FLAME parameters yields rather unsatisfactory results. Instead we render out geometry and photo-metric details of the FLAME mesh and use these for conditioning instead. This gives us a generative 2D face model named GIF (Generative Interpretable Faces) that shares FLAME's parametric control. Given FLAME parameters for shape, pose, and expressions, parameters for appearance and lighting, and an additional style vector, GIF outputs photo-realistic face images. To evaluate how well GIF follows its conditioning and the impact of different design choices, we perform a perceptual study. The code and trained model are publicly available for research purposes at https://github.com/ParthaEth/GIF.
Grasping Field: Learning Implicit Representations for Human Grasps
Aug 12, 2020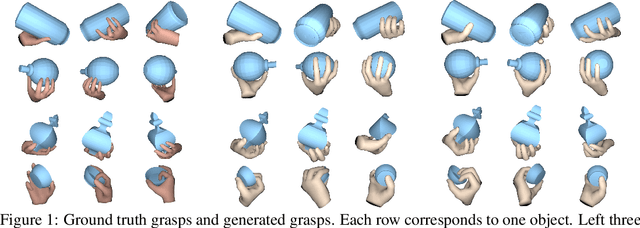
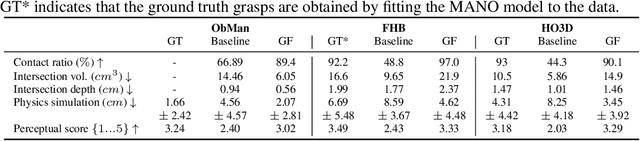
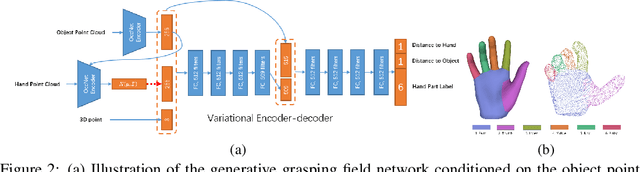
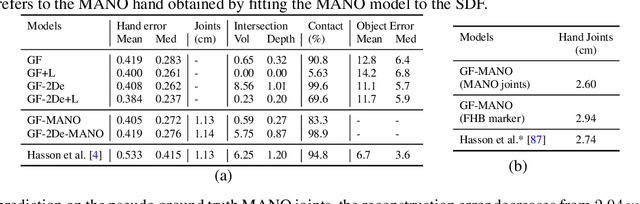
In recent years, substantial progress has been made on robotic grasping of household objects. Yet, human grasps are still difficult to synthesize realistically. There are several key reasons: (1) the human hand has many degrees of freedom (more than robotic manipulators); (2) the synthesized hand should conform naturally to the object surface; and (3) it must interact with the object in a semantically and physical plausible manner. To make progress in this direction, we draw inspiration from the recent progress on learning-based implicit representations for 3D object reconstruction. Specifically, we propose an expressive representation for human grasp modelling that is efficient and easy to integrate with deep neural networks. Our insight is that every point in a three-dimensional space can be characterized by the signed distances to the surface of the hand and the object, respectively. Consequently, the hand, the object, and the contact area can be represented by implicit surfaces in a common space, in which the proximity between the hand and the object can be modelled explicitly. We name this 3D to 2D mapping as Grasping Field, parameterize it with a deep neural network, and learn it from data. We demonstrate that the proposed grasping field is an effective and expressive representation for human grasp generation. Specifically, our generative model is able to synthesize high-quality human grasps, given only on a 3D object point cloud. The extensive experiments demonstrate that our generative model compares favorably with a strong baseline. Furthermore, based on the grasping field representation, we propose a deep network for the challenging task of 3D hand and object reconstruction from a single RGB image. Our method improves the physical plausibility of the 3D hand-object reconstruction task over baselines.
From Variational to Deterministic Autoencoders
Apr 01, 2019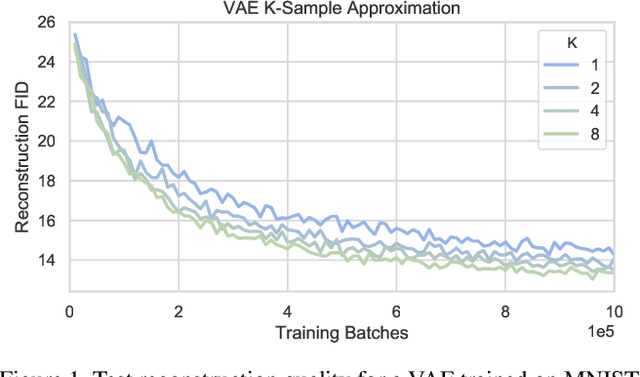
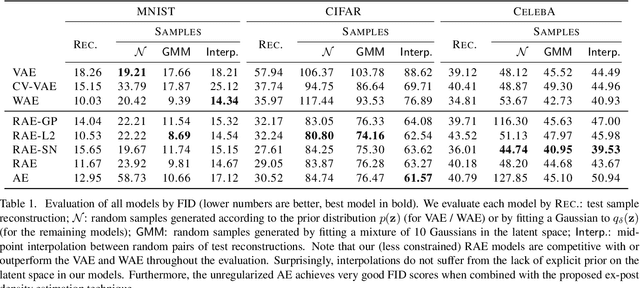
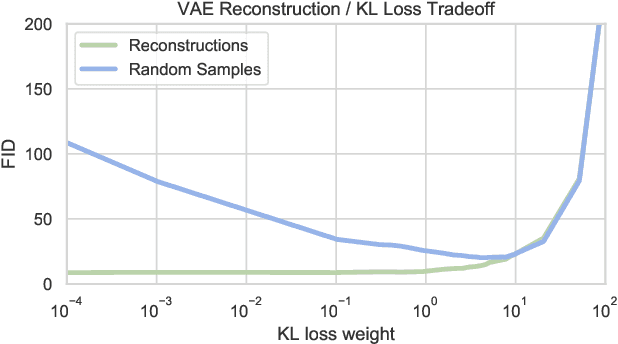
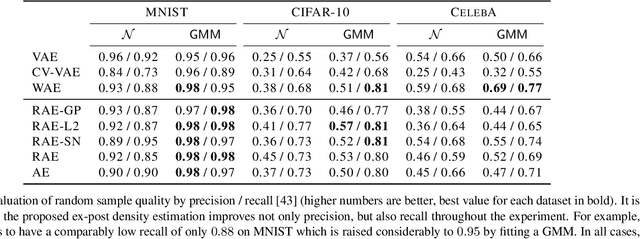
Variational Autoencoders (VAEs) provide a theoretically-backed framework for deep generative models. However, they often produce "blurry" images, which is linked to their training objective. Sampling in the most popular implementation, the Gaussian VAE, can be interpreted as simply injecting noise to the input of a deterministic decoder. In practice, this simply enforces a smooth latent space structure. We challenge the adoption of the full VAE framework on this specific point in favor of a simpler, deterministic one. Specifically, we investigate how substituting stochasticity with other explicit and implicit regularization schemes can lead to a meaningful latent space without having to force it to conform to an arbitrarily chosen prior. To retrieve a generative mechanism for sampling new data points, we propose to employ an efficient ex-post density estimation step that can be readily adopted both for the proposed deterministic autoencoders as well as to improve sample quality of existing VAEs. We show in a rigorous empirical study that regularized deterministic autoencoding achieves state-of-the-art sample quality on the common MNIST, CIFAR-10 and CelebA datasets.