 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Joint and Domain-Adaptive Approach to Spoken Language Understanding
Jul 25, 2021
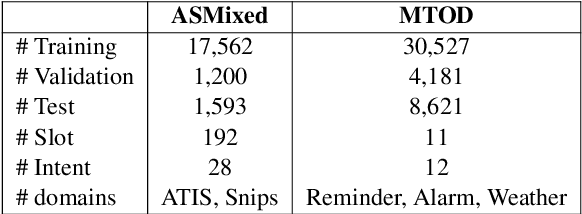
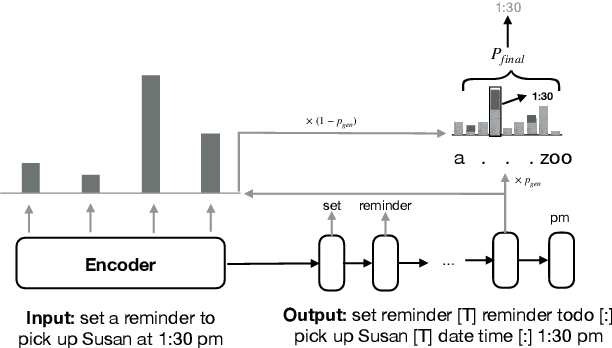
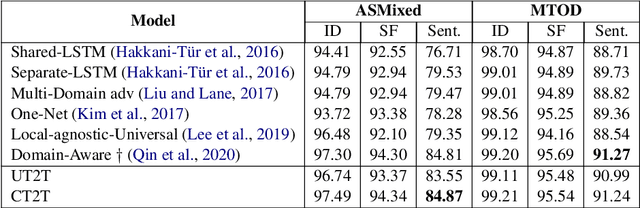
Spoken Language Understanding (SLU) is composed of two subtasks: intent detection (ID) and slot filling (SF). There are two lines of research on SLU. One jointly tackles these two subtasks to improve their prediction accuracy, and the other focuses on the domain-adaptation ability of one of the subtasks. In this paper, we attempt to bridge these two lines of research and propose a joint and domain adaptive approach to SLU. We formulate SLU as a constrained generation task and utilize a dynamic vocabulary based on domain-specific ontology. We conduct experiments on the ASMixed and MTOD datasets and achieve competitive performance with previous state-of-the-art joint models. Besides, results show that our joint model can be effectively adapted to a new domain.
Retrieval Enhanced Model for Commonsense Generation
May 24, 2021
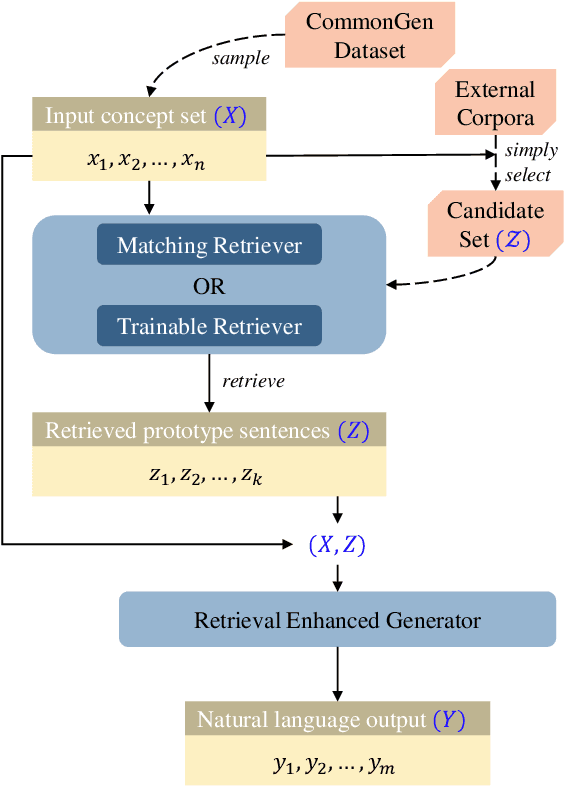
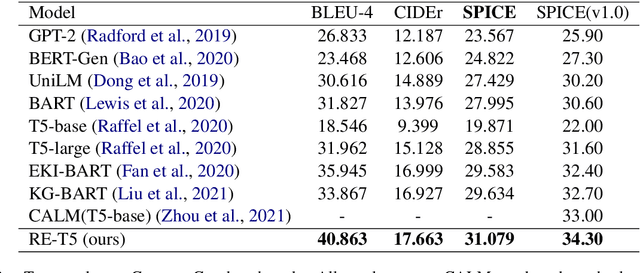

Commonsense generation is a challenging task of generating a plausible sentence describing an everyday scenario using provided concepts. Its requirement of reasoning over commonsense knowledge and compositional generalization ability even puzzles strong pre-trained language generation models. We propose a novel framework using retrieval methods to enhance both the pre-training and fine-tuning for commonsense generation. We retrieve prototype sentence candidates by concept matching and use them as auxiliary input. For fine-tuning, we further boost its performance with a trainable sentence retriever. We demonstrate experimentally on the large-scale CommonGen benchmark that our approach achieves new state-of-the-art results.
MediaSum: A Large-scale Media Interview Dataset for Dialogue Summarization
Mar 12, 2021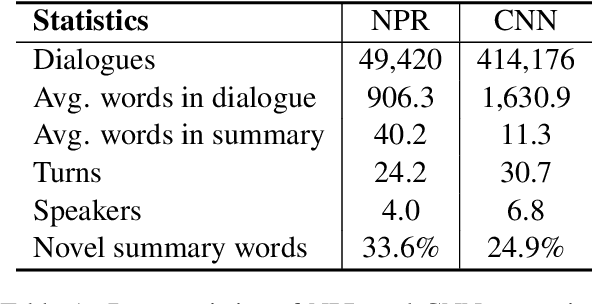
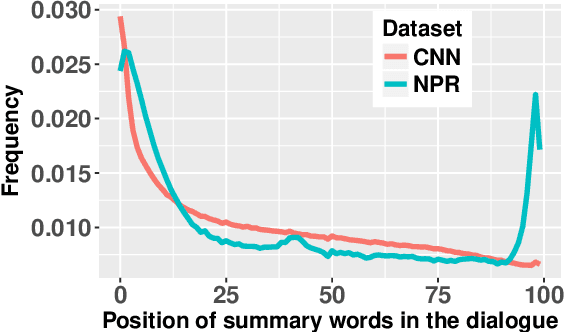
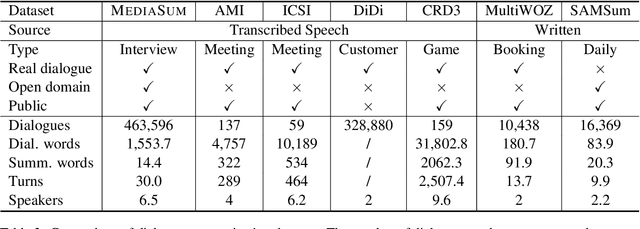
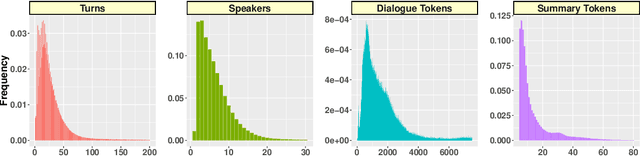
MediaSum, a large-scale media interview dataset consisting of 463.6K transcripts with abstractive summaries. To create this dataset, we collect interview transcripts from NPR and CNN and employ the overview and topic descriptions as summaries. Compared with existing public corpora for dialogue summarization, our dataset is an order of magnitude larger and contains complex multi-party conversations from multiple domains. We conduct statistical analysis to demonstrate the unique positional bias exhibited in the transcripts of televised and radioed interviews. We also show that MediaSum can be used in transfer learning to improve a model's performance on other dialogue summarization tasks.
* Dataset: https://github.com/zcgzcgzcg1/MediaSum/
Generating Human Readable Transcript for Automatic Speech Recognition with Pre-trained Language Model
Feb 22, 2021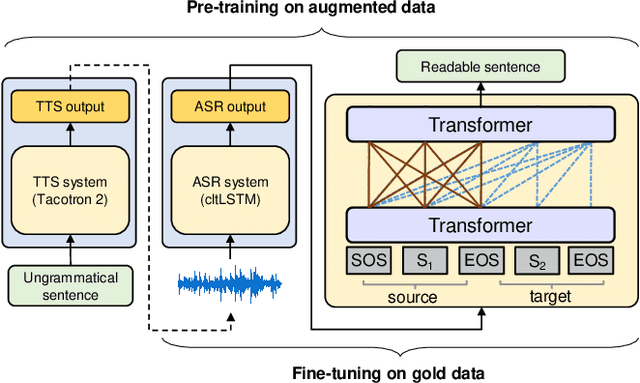
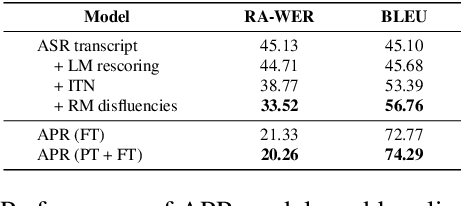

Modern Automatic Speech Recognition (ASR) systems can achieve high performance in terms of recognition accuracy. However, a perfectly accurate transcript still can be challenging to read due to disfluency, filter words, and other errata common in spoken communication. Many downstream tasks and human readers rely on the output of the ASR system; therefore, errors introduced by the speaker and ASR system alike will be propagated to the next task in the pipeline. In this work, we propose an ASR post-processing model that aims to transform the incorrect and noisy ASR output into a readable text for humans and downstream tasks. We leverage the Metadata Extraction (MDE) corpus to construct a task-specific dataset for our study. Since the dataset is small, we propose a novel data augmentation method and use a two-stage training strategy to fine-tune the RoBERTa pre-trained model. On the constructed test set, our model outperforms a production two-step pipeline-based post-processing method by a large margin of 13.26 on readability-aware WER (RA-WER) and 17.53 on BLEU metrics. Human evaluation also demonstrates that our method can generate more human-readable transcripts than the baseline method.
Improving Zero-shot Neural Machine Translation on Language-specific Encoders-Decoders
Feb 12, 2021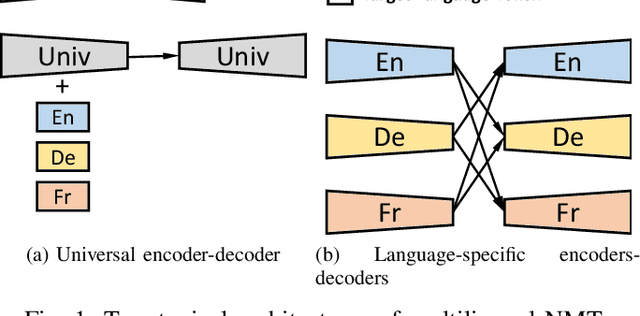
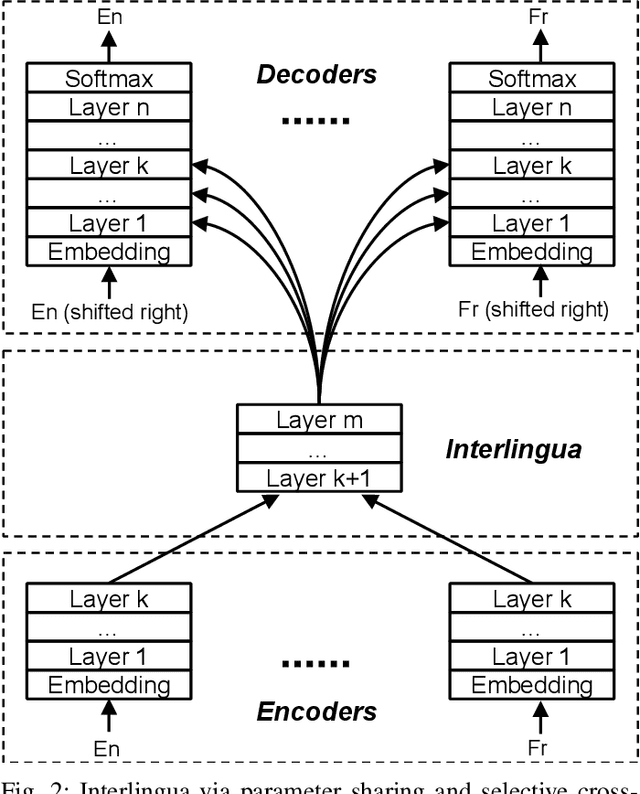

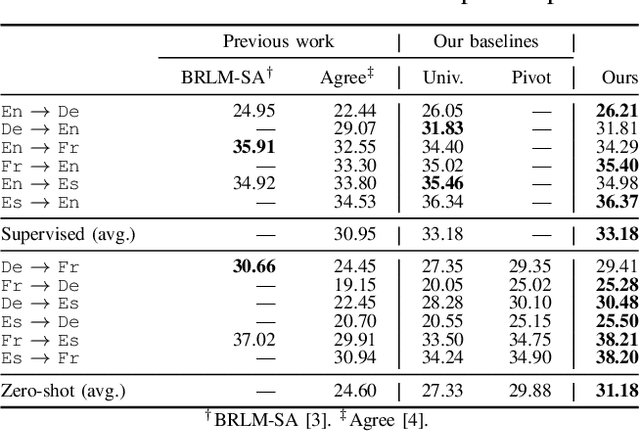
Recently, universal neural machine translation (NMT) with shared encoder-decoder gained good performance on zero-shot translation. Unlike universal NMT, jointly trained language-specific encoders-decoders aim to achieve universal representation across non-shared modules, each of which is for a language or language family. The non-shared architecture has the advantage of mitigating internal language competition, especially when the shared vocabulary and model parameters are restricted in their size. However, the performance of using multiple encoders and decoders on zero-shot translation still lags behind universal NMT. In this work, we study zero-shot translation using language-specific encoders-decoders. We propose to generalize the non-shared architecture and universal NMT by differentiating the Transformer layers between language-specific and interlingua. By selectively sharing parameters and applying cross-attentions, we explore maximizing the representation universality and realizing the best alignment of language-agnostic information. We also introduce a denoising auto-encoding (DAE) objective to jointly train the model with the translation task in a multi-task manner. Experiments on two public multilingual parallel datasets show that our proposed model achieves a competitive or better results than universal NMT and strong pivot baseline. Moreover, we experiment incrementally adding new language to the trained model by only updating the new model parameters. With this little effort, the zero-shot translation between this newly added language and existing languages achieves a comparable result with the model trained jointly from scratch on all languages.
Speech-language Pre-training for End-to-end Spoken Language Understanding
Feb 11, 2021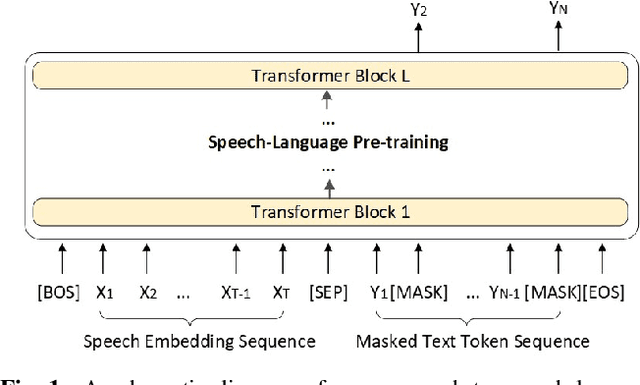
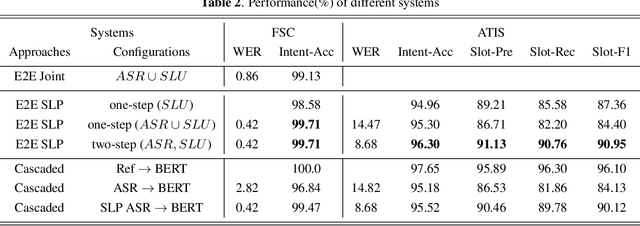
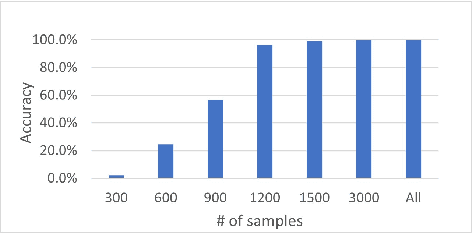
End-to-end (E2E) spoken language understanding (SLU) can infer semantics directly from speech signal without cascading an automatic speech recognizer (ASR) with a natural language understanding (NLU) module. However, paired utterance recordings and corresponding semantics may not always be available or sufficient to train an E2E SLU model in a real production environment. In this paper, we propose to unify a well-optimized E2E ASR encoder (speech) and a pre-trained language model encoder (language) into a transformer decoder. The unified speech-language pre-trained model (SLP) is continually enhanced on limited labeled data from a target domain by using a conditional masked language model (MLM) objective, and thus can effectively generate a sequence of intent, slot type, and slot value for given input speech in the inference. The experimental results on two public corpora show that our approach to E2E SLU is superior to the conventional cascaded method. It also outperforms the present state-of-the-art approaches to E2E SLU with much less paired data.
UniSpeech: Unified Speech Representation Learning with Labeled and Unlabeled Data
Jan 19, 2021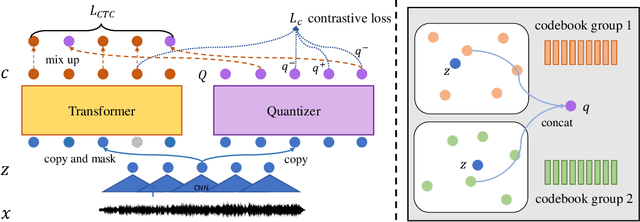
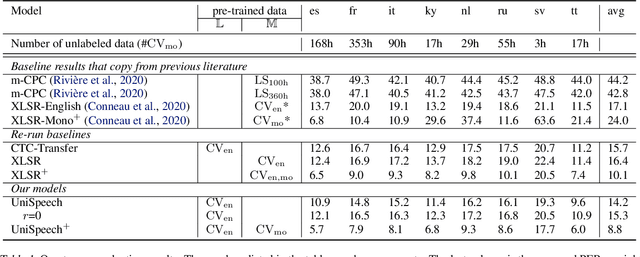

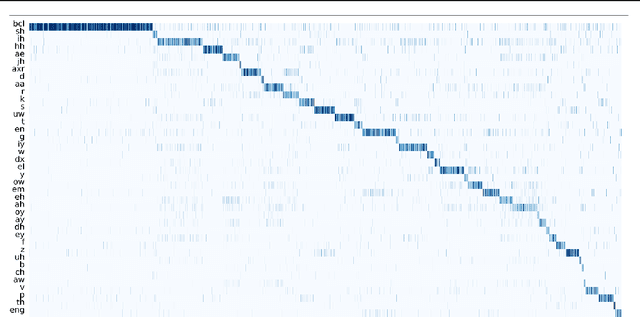
In this paper, we propose a unified pre-training approach called UniSpeech to learn speech representations with both unlabeled and labeled data, in which supervised phonetic CTC learning and phonetically-aware contrastive self-supervised learning are conducted in a multi-task learning manner. The resultant representations can capture information more correlated with phonetic structures and improve the generalization across languages and domains. We evaluate the effectiveness of UniSpeech for cross-lingual representation learning on public CommonVoice corpus. The results show that UniSpeech outperforms self-supervised pretraining and supervised transfer learning for speech recognition by a maximum of 13.4% and 17.8% relative phone error rate reductions respectively (averaged over all testing languages). The transferability of UniSpeech is also demonstrated on a domain-shift speech recognition task, i.e., a relative word error rate reduction of 6% against the previous approach.
Fusing Context Into Knowledge Graph for Commonsense Reasoning
Dec 09, 2020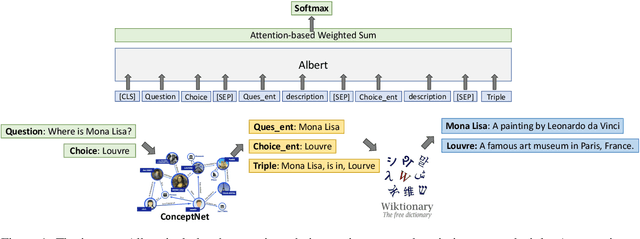

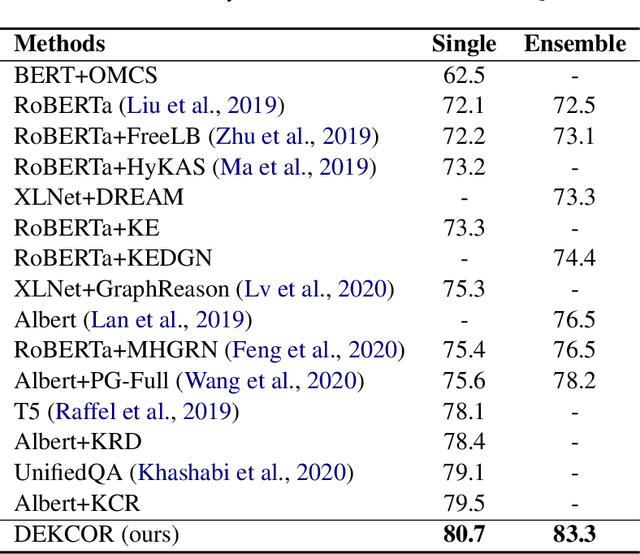

Commonsense reasoning requires a model to make presumptions about world events via language understanding. Many methods couple pre-trained language models with knowledge graphs in order to combine the merits in language modeling and entity-based relational learning. However, although a knowledge graph contains rich structural information, it lacks the context to provide a more precise understanding of the concepts and relations. This creates a gap when fusing knowledge graphs into language modeling, especially in the scenario of insufficient paired text-knowledge data. In this paper, we propose to utilize external entity description to provide contextual information for graph entities. For the CommonsenseQA task, our model first extracts concepts from the question and choice, and then finds a related triple between these concepts. Next, it retrieves the descriptions of these concepts from Wiktionary and feed them as additional input to a pre-trained language model, together with the triple. The resulting model can attain much more effective commonsense reasoning capability, achieving state-of-the-art results in the CommonsenseQA dataset with an accuracy of 80.7% (single model) and 83.3% (ensemble model) on the official leaderboard.
LSTM-LM with Long-Term History for First-Pass Decoding in Conversational Speech Recognition
Oct 21, 2020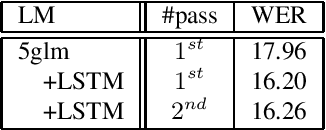
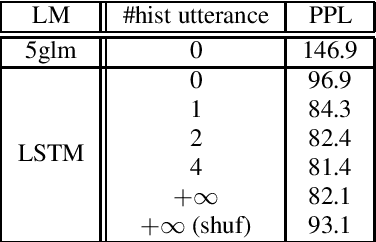
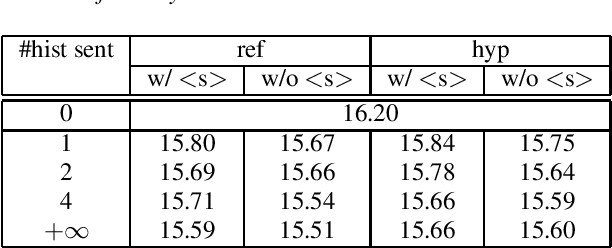

LSTM language models (LSTM-LMs) have been proven to be powerful and yielded significant performance improvements over count based n-gram LMs in modern speech recognition systems. Due to its infinite history states and computational load, most previous studies focus on applying LSTM-LMs in the second-pass for rescoring purpose. Recent work shows that it is feasible and computationally affordable to adopt the LSTM-LMs in the first-pass decoding within a dynamic (or tree based) decoder framework. In this work, the LSTM-LM is composed with a WFST decoder on-the-fly for the first-pass decoding. Furthermore, motivated by the long-term history nature of LSTM-LMs, the use of context beyond the current utterance is explored for the first-pass decoding in conversational speech recognition. The context information is captured by the hidden states of LSTM-LMs across utterance and can be used to guide the first-pass search effectively. The experimental results in our internal meeting transcription system show that significant performance improvements can be obtained by incorporating the contextual information with LSTM-LMs in the first-pass decoding, compared to applying the contextual information in the second-pass rescoring.
Mixed-Lingual Pre-training for Cross-lingual Summarization
Oct 18, 2020
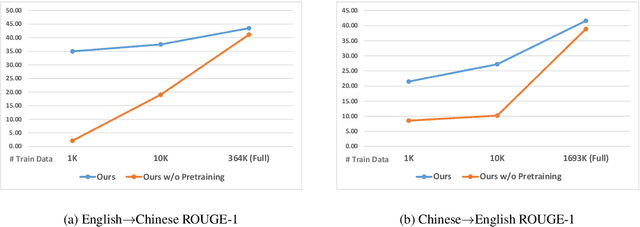
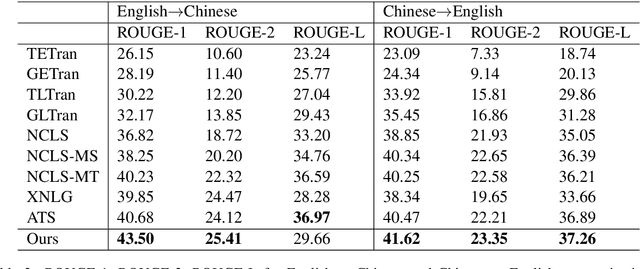
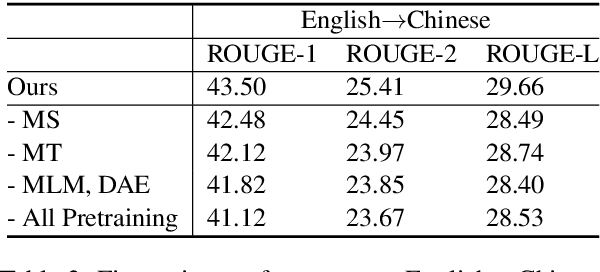
Cross-lingual Summarization (CLS) aims at producing a summary in the target language for an article in the source language. Traditional solutions employ a two-step approach, i.e. translate then summarize or summarize then translate. Recently, end-to-end models have achieved better results, but these approaches are mostly limited by their dependence on large-scale labeled data. We propose a solution based on mixed-lingual pre-training that leverages both cross-lingual tasks such as translation and monolingual tasks like masked language models. Thus, our model can leverage the massive monolingual data to enhance its modeling of language. Moreover, the architecture has no task-specific components, which saves memory and increases optimization efficiency. We show in experiments that this pre-training scheme can effectively boost the performance of cross-lingual summarization. In Neural Cross-Lingual Summarization (NCLS) dataset, our model achieves an improvement of 2.82 (English to Chinese) and 1.15 (Chinese to English) ROUGE-1 scores over state-of-the-art results.