 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Forecast Critic: Leveraging Large Language Models for Poor Forecast Identification
Dec 12, 2025



Monitoring forecasting systems is critical for customer satisfaction, profitability, and operational efficiency in large-scale retail businesses. We propose The Forecast Critic, a system that leverages Large Language Models (LLMs) for automated forecast monitoring, taking advantage of their broad world knowledge and strong ``reasoning'' capabilities. As a prerequisite for this, we systematically evaluate the ability of LLMs to assess time series forecast quality, focusing on three key questions. (1) Can LLMs be deployed to perform forecast monitoring and identify obviously unreasonable forecasts? (2) Can LLMs effectively incorporate unstructured exogenous features to assess what a reasonable forecast looks like? (3) How does performance vary across model sizes and reasoning capabilities, measured across state-of-the-art LLMs? We present three experiments, including on both synthetic and real-world forecasting data. Our results show that LLMs can reliably detect and critique poor forecasts, such as those plagued by temporal misalignment, trend inconsistencies, and spike errors. The best-performing model we evaluated achieves an F1 score of 0.88, somewhat below human-level performance (F1 score: 0.97). We also demonstrate that multi-modal LLMs can effectively incorporate unstructured contextual signals to refine their assessment of the forecast. Models correctly identify missing or spurious promotional spikes when provided with historical context about past promotions (F1 score: 0.84). Lastly, we demonstrate that these techniques succeed in identifying inaccurate forecasts on the real-world M5 time series dataset, with unreasonable forecasts having an sCRPS at least 10% higher than that of reasonable forecasts. These findings suggest that LLMs, even without domain-specific fine-tuning, may provide a viable and scalable option for automated forecast monitoring and evaluation.
Accelerating scientific discovery with the common task framework
Nov 06, 2025Machine learning (ML) and artificial intelligence (AI) algorithms are transforming and empowering the characterization and control of dynamic systems in the engineering, physical, and biological sciences. These emerging modeling paradigms require comparative metrics to evaluate a diverse set of scientific objectives, including forecasting, state reconstruction, generalization, and control, while also considering limited data scenarios and noisy measurements. We introduce a common task framework (CTF) for science and engineering, which features a growing collection of challenge data sets with a diverse set of practical and common objectives. The CTF is a critically enabling technology that has contributed to the rapid advance of ML/AI algorithms in traditional applications such as speech recognition, language processing, and computer vision. There is a critical need for the objective metrics of a CTF to compare the diverse algorithms being rapidly developed and deployed in practice today across science and engineering.
Understanding the Implicit Biases of Design Choices for Time Series Foundation Models
Oct 22, 2025Time series foundation models (TSFMs) are a class of potentially powerful, general-purpose tools for time series forecasting and related temporal tasks, but their behavior is strongly shaped by subtle inductive biases in their design. Rather than developing a new model and claiming that it is better than existing TSFMs, e.g., by winning on existing well-established benchmarks, our objective is to understand how the various ``knobs'' of the training process affect model quality. Using a mix of theory and controlled empirical evaluation, we identify several design choices (patch size, embedding choice, training objective, etc.) and show how they lead to implicit biases in fundamental model properties (temporal behavior, geometric structure, how aggressively or not the model regresses to the mean, etc.); and we show how these biases can be intuitive or very counterintuitive, depending on properties of the model and data. We also illustrate in a case study on outlier handling how multiple biases can interact in complex ways; and we discuss implications of our results for learning the bitter lesson and building TSFMs.
Forking-Sequences
Oct 06, 2025



While accuracy is a critical requirement for time series forecasting models, an equally important (yet often overlooked) desideratum is forecast stability across forecast creation dates (FCDs). Even highly accurate models can produce erratic revisions between FCDs, undermining stakeholder trust and disrupting downstream decision-making. To improve forecast stability, models like MQCNN, MQT, and SPADE employ a little-known but highly effective technique: forking-sequences. Unlike standard statistical and neural forecasting methods that treat each FCD independently, the forking-sequences method jointly encodes and decodes the entire time series across all FCDs, in a way mirroring time series cross-validation. Since forking sequences remains largely unknown in the broader neural forecasting community, in this work, we formalize the forking-sequences approach, and we make a case for its broader adoption. We demonstrate three key benefits of forking-sequences: (i) more stable and consistent gradient updates during training; (ii) reduced forecast variance through ensembling; and (iii) improved inference computational efficiency. We validate forking-sequences' benefits using 16 datasets from the M1, M3, M4, and Tourism competitions, showing improvements in forecast percentage change stability of 28.8%, 28.8%, 37.9%, and 31.3%, and 8.8%, on average, for MLP, RNN, LSTM, CNN, and Transformer-based architectures, respectively.
Efficiently Generating Correlated Sample Paths from Multi-step Time Series Foundation Models
Oct 02, 2025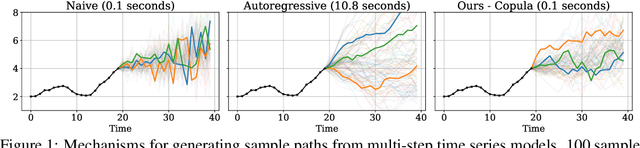
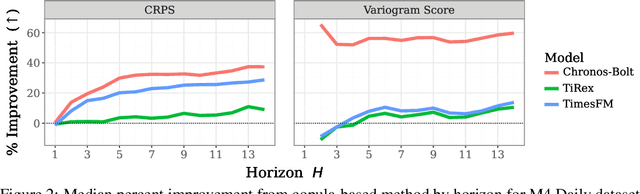
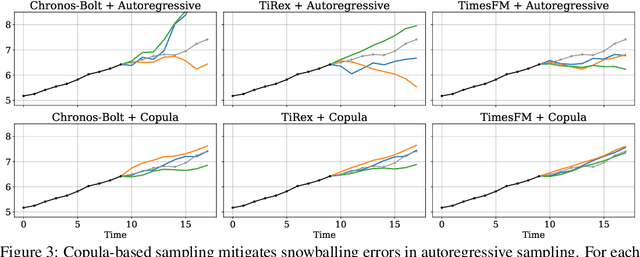
Many time series applications require access to multi-step forecast trajectories in the form of sample paths. Recently, time series foundation models have leveraged multi-step lookahead predictions to improve the quality and efficiency of multi-step forecasts. However, these models only predict independent marginal distributions for each time step, rather than a full joint predictive distribution. To generate forecast sample paths with realistic correlation structures, one typically resorts to autoregressive sampling, which can be extremely expensive. In this paper, we present a copula-based approach to efficiently generate accurate, correlated sample paths from existing multi-step time series foundation models in one forward pass. Our copula-based approach generates correlated sample paths orders of magnitude faster than autoregressive sampling, and it yields improved sample path quality by mitigating the snowballing error phenomenon.
XQuant: Breaking the Memory Wall for LLM Inference with KV Cache Rematerialization
Aug 14, 2025Although LLM inference has emerged as a critical workload for many downstream applications, efficiently inferring LLMs is challenging due to the substantial memory footprint and bandwidth requirements. In parallel, compute capabilities have steadily outpaced both memory capacity and bandwidth over the last few decades, a trend that remains evident in modern GPU hardware and exacerbates the challenge of LLM inference. As such, new algorithms are emerging that trade increased computation for reduced memory operations. To that end, we present XQuant, which takes advantage of this trend, enabling an order-of-magnitude reduction in memory consumption through low-bit quantization with substantial accuracy benefits relative to state-of-the-art KV cache quantization methods. We accomplish this by quantizing and caching the layer input activations X, instead of using standard KV caching, and then rematerializing the Keys and Values on-the-fly during inference. This results in an immediate 2$\times$ memory savings compared to KV caching. By applying XQuant, we achieve up to $\sim 7.7\times$ memory savings with $<0.1$ perplexity degradation compared to the FP16 baseline. Furthermore, our approach leverages the fact that X values are similar across layers. Building on this observation, we introduce XQuant-CL, which exploits the cross-layer similarity in the X embeddings for extreme compression. Across different models, XQuant-CL attains up to 10$\times$ memory savings relative to the FP16 baseline with only 0.01 perplexity degradation, and 12.5$\times$ memory savings with only $0.1$ perplexity degradation. XQuant exploits the rapidly increasing compute capabilities of hardware platforms to eliminate the memory bottleneck, while surpassing state-of-the-art KV cache quantization methods and achieving near-FP16 accuracy across a wide range of models.
Multipole Attention for Efficient Long Context Reasoning
Jun 16, 2025



Large Reasoning Models (LRMs) have shown promising accuracy improvements on complex problem-solving tasks. While these models have attained high accuracy by leveraging additional computation at test time, they need to generate long chain-of-thought reasoning in order to think before answering, which requires generating thousands of tokens. While sparse attention methods can help reduce the KV cache pressure induced by this long autoregressive reasoning, these methods can introduce errors which disrupt the reasoning process. Additionally, prior methods often pre-process the input to make it easier to identify the important prompt tokens when computing attention during generation, and this pre-processing is challenging to perform online for newly generated reasoning tokens. Our work addresses these challenges by introducing Multipole Attention, which accelerates autoregressive reasoning by only computing exact attention for the most important tokens, while maintaining approximate representations for the remaining tokens. Our method first performs clustering to group together semantically similar key vectors, and then uses the cluster centroids both to identify important key vectors and to approximate the remaining key vectors in order to retain high accuracy. We design a fast cluster update process to quickly re-cluster the input and previously generated tokens, thereby allowing for accelerating attention to the previous output tokens. We evaluate our method using emerging LRMs such as Qwen-8B, demonstrating that our approach can maintain accuracy on complex reasoning tasks even with aggressive attention sparsity settings. We also provide kernel implementations to demonstrate the practical efficiency gains from our method, achieving up to 4.5$\times$ speedup for attention in long-context reasoning applications. Our code is available at https://github.com/SqueezeAILab/MultipoleAttention.
Random Matrix Theory for Deep Learning: Beyond Eigenvalues of Linear Models
Jun 16, 2025Modern Machine Learning (ML) and Deep Neural Networks (DNNs) often operate on high-dimensional data and rely on overparameterized models, where classical low-dimensional intuitions break down. In particular, the proportional regime where the data dimension, sample size, and number of model parameters are all large and comparable, gives rise to novel and sometimes counterintuitive behaviors. This paper extends traditional Random Matrix Theory (RMT) beyond eigenvalue-based analysis of linear models to address the challenges posed by nonlinear ML models such as DNNs in this regime. We introduce the concept of High-dimensional Equivalent, which unifies and generalizes both Deterministic Equivalent and Linear Equivalent, to systematically address three technical challenges: high dimensionality, nonlinearity, and the need to analyze generic eigenspectral functionals. Leveraging this framework, we provide precise characterizations of the training and generalization performance of linear models, nonlinear shallow networks, and deep networks. Our results capture rich phenomena, including scaling laws, double descent, and nonlinear learning dynamics, offering a unified perspective on the theoretical understanding of deep learning in high dimensions.
Spectral Estimation with Free Decompression
Jun 13, 2025



Computing eigenvalues of very large matrices is a critical task in many machine learning applications, including the evaluation of log-determinants, the trace of matrix functions, and other important metrics. As datasets continue to grow in scale, the corresponding covariance and kernel matrices become increasingly large, often reaching magnitudes that make their direct formation impractical or impossible. Existing techniques typically rely on matrix-vector products, which can provide efficient approximations, if the matrix spectrum behaves well. However, in settings like distributed learning, or when the matrix is defined only indirectly, access to the full data set can be restricted to only very small sub-matrices of the original matrix. In these cases, the matrix of nominal interest is not even available as an implicit operator, meaning that even matrix-vector products may not be available. In such settings, the matrix is "impalpable," in the sense that we have access to only masked snapshots of it. We draw on principles from free probability theory to introduce a novel method of "free decompression" to estimate the spectrum of such matrices. Our method can be used to extrapolate from the empirical spectral densities of small submatrices to infer the eigenspectrum of extremely large (impalpable) matrices (that we cannot form or even evaluate with full matrix-vector products). We demonstrate the effectiveness of this approach through a series of examples, comparing its performance against known limiting distributions from random matrix theory in synthetic settings, as well as applying it to submatrices of real-world datasets, matching them with their full empirical eigenspectra.
End-to-End Probabilistic Framework for Learning with Hard Constraints
Jun 08, 2025We present a general purpose probabilistic forecasting framework, ProbHardE2E, to learn systems that can incorporate operational/physical constraints as hard requirements. ProbHardE2E enforces hard constraints by exploiting variance information in a novel way; and thus it is also capable of performing uncertainty quantification (UQ) on the model. Our methodology uses a novel differentiable probabilistic projection layer (DPPL) that can be combined with a wide range of neural network architectures. This DPPL allows the model to learn the system in an end-to-end manner, compared to other approaches where the constraints are satisfied either through a post-processing step or at inference. In addition, ProbHardE2E can optimize a strictly proper scoring rule, without making any distributional assumptions on the target, which enables it to obtain robust distributional estimates (in contrast to existing approaches that generally optimize likelihood-based objectives, which are heavily biased by their distributional assumptions and model choices); and it can incorporate a range of non-linear constraints (increasing the power of modeling and flexibility). We apply ProbHardE2E to problems in learning partial differential equations with uncertainty estimates and to probabilistic time-series forecasting, showcasing it as a broadly applicable general setup that connects these seemingly disparate domains.