 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMICA: Multivariate Infini Compressive Attention for Time Series Forecasting
Apr 07, 2026Multivariate forecasting with Transformers faces a core scalability challenge: modeling cross-channel dependencies via attention compounds attention's quadratic sequence complexity with quadratic channel scaling, making full cross-channel attention impractical for high-dimensional time series. We propose Multivariate Infini Compressive Attention (MICA), an architectural design to extend channel-independent Transformers to channel-dependent forecasting. By adapting efficient attention techniques from the sequence dimension to the channel dimension, MICA adds a cross-channel attention mechanism to channel-independent backbones that scales linearly with channel count and context length. We evaluate channel-independent Transformer architectures with and without MICA across multiple forecasting benchmarks. MICA reduces forecast error over its channel-independent counterparts by 5.4% on average and up to 25.4% on individual datasets, highlighting the importance of explicit cross-channel modeling. Moreover, models with MICA rank first among deep multivariate Transformer and MLP baselines. MICA models also scale more efficiently with respect to both channel count and context length than Transformer baselines that compute attention across both the temporal and channel dimensions, establishing compressive attention as a practical solution for scalable multivariate forecasting.
Forking-Sequences
Oct 06, 2025



While accuracy is a critical requirement for time series forecasting models, an equally important (yet often overlooked) desideratum is forecast stability across forecast creation dates (FCDs). Even highly accurate models can produce erratic revisions between FCDs, undermining stakeholder trust and disrupting downstream decision-making. To improve forecast stability, models like MQCNN, MQT, and SPADE employ a little-known but highly effective technique: forking-sequences. Unlike standard statistical and neural forecasting methods that treat each FCD independently, the forking-sequences method jointly encodes and decodes the entire time series across all FCDs, in a way mirroring time series cross-validation. Since forking sequences remains largely unknown in the broader neural forecasting community, in this work, we formalize the forking-sequences approach, and we make a case for its broader adoption. We demonstrate three key benefits of forking-sequences: (i) more stable and consistent gradient updates during training; (ii) reduced forecast variance through ensembling; and (iii) improved inference computational efficiency. We validate forking-sequences' benefits using 16 datasets from the M1, M3, M4, and Tourism competitions, showing improvements in forecast percentage change stability of 28.8%, 28.8%, 37.9%, and 31.3%, and 8.8%, on average, for MLP, RNN, LSTM, CNN, and Transformer-based architectures, respectively.
Investigating Compositional Reasoning in Time Series Foundation Models
Feb 09, 2025



Large pre-trained time series foundation models (TSFMs) have demonstrated promising zero-shot performance across a wide range of domains. However, a question remains: Do TSFMs succeed solely by memorizing training patterns, or do they possess the ability to reason? While reasoning is a topic of great interest in the study of Large Language Models (LLMs), it is undefined and largely unexplored in the context of TSFMs. In this work, inspired by language modeling literature, we formally define compositional reasoning in forecasting and distinguish it from in-distribution generalization. We evaluate the reasoning and generalization capabilities of 23 popular deep learning forecasting models on multiple synthetic and real-world datasets. Additionally, through controlled studies, we systematically examine which design choices in TSFMs contribute to improved reasoning abilities. Our study yields key insights into the impact of TSFM architecture design on compositional reasoning and generalization. We find that patch-based Transformers have the best reasoning performance, closely followed by residualized MLP-based architectures, which are 97\% less computationally complex in terms of FLOPs and 86\% smaller in terms of the number of trainable parameters. Interestingly, in some zero-shot out-of-distribution scenarios, these models can outperform moving average and exponential smoothing statistical baselines trained on in-distribution data. Only a few design choices, such as the tokenization method, had a significant (negative) impact on Transformer model performance.
Implicit Reasoning in Deep Time Series Forecasting
Sep 18, 2024



Recently, time series foundation models have shown promising zero-shot forecasting performance on time series from a wide range of domains. However, it remains unclear whether their success stems from a true understanding of temporal dynamics or simply from memorizing the training data. While implicit reasoning in language models has been studied, similar evaluations for time series models have been largely unexplored. This work takes an initial step toward assessing the reasoning abilities of deep time series forecasting models. We find that certain linear, MLP-based, and patch-based Transformer models generalize effectively in systematically orchestrated out-of-distribution scenarios, suggesting underexplored reasoning capabilities beyond simple pattern memorization.
Forecasting Response to Treatment with Deep Learning and Pharmacokinetic Priors
Sep 22, 2023Forecasting healthcare time series is crucial for early detection of adverse outcomes and for patient monitoring. Forecasting, however, can be difficult in practice due to noisy and intermittent data. The challenges are often exacerbated by change points induced via extrinsic factors, such as the administration of medication. We propose a novel encoder that informs deep learning models of the pharmacokinetic effects of drugs to allow for accurate forecasting of time series affected by treatment. We showcase the effectiveness of our approach in a task to forecast blood glucose using both realistically simulated and real-world data. Our pharmacokinetic encoder helps deep learning models surpass baselines by approximately 11% on simulated data and 8% on real-world data. The proposed approach can have multiple beneficial applications in clinical practice, such as issuing early warnings about unexpected treatment responses, or helping to characterize patient-specific treatment effects in terms of drug absorption and elimination characteristics.
auton-survival: an Open-Source Package for Regression, Counterfactual Estimation, Evaluation and Phenotyping with Censored Time-to-Event Data
Apr 15, 2022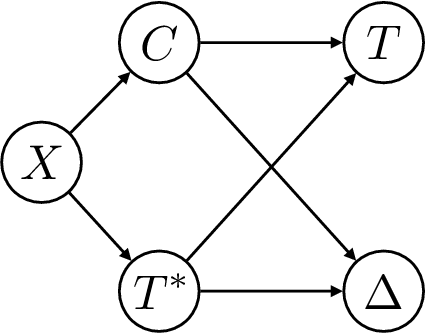
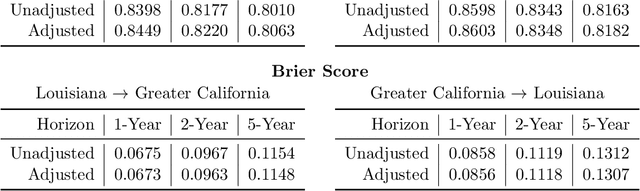
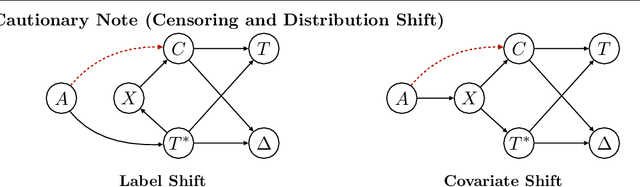
Applications of machine learning in healthcare often require working with time-to-event prediction tasks including prognostication of an adverse event, re-hospitalization or death. Such outcomes are typically subject to censoring due to loss of follow up. Standard machine learning methods cannot be applied in a straightforward manner to datasets with censored outcomes. In this paper, we present auton-survival, an open-source repository of tools to streamline working with censored time-to-event or survival data. auton-survival includes tools for survival regression, adjustment in the presence of domain shift, counterfactual estimation, phenotyping for risk stratification, evaluation, as well as estimation of treatment effects. Through real world case studies employing a large subset of the SEER oncology incidence data, we demonstrate the ability of auton-survival to rapidly support data scientists in answering complex health and epidemiological questions.
The World as a Graph: Improving El Niño Forecasts with Graph Neural Networks
Apr 11, 2021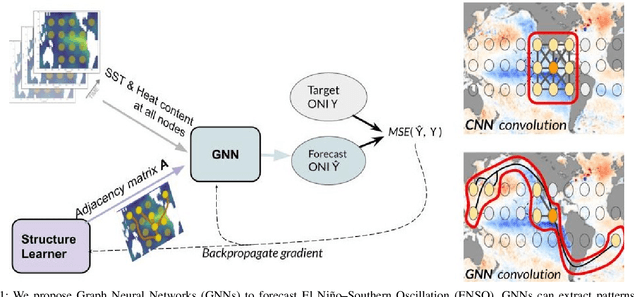
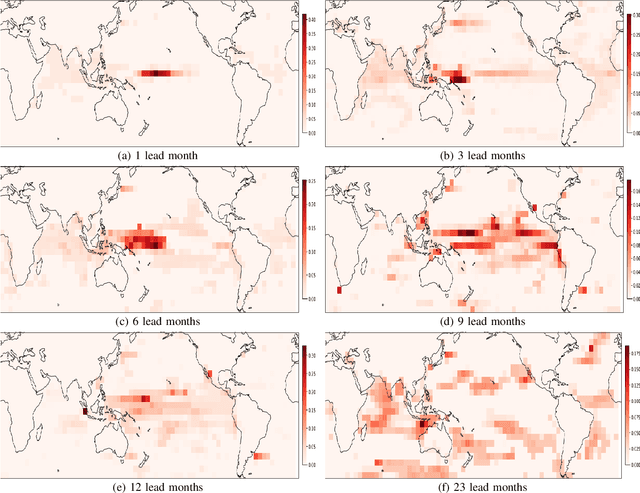
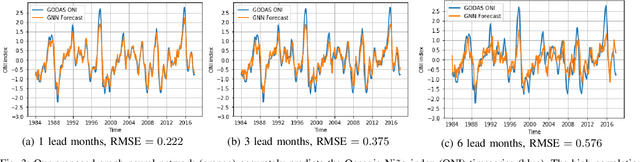
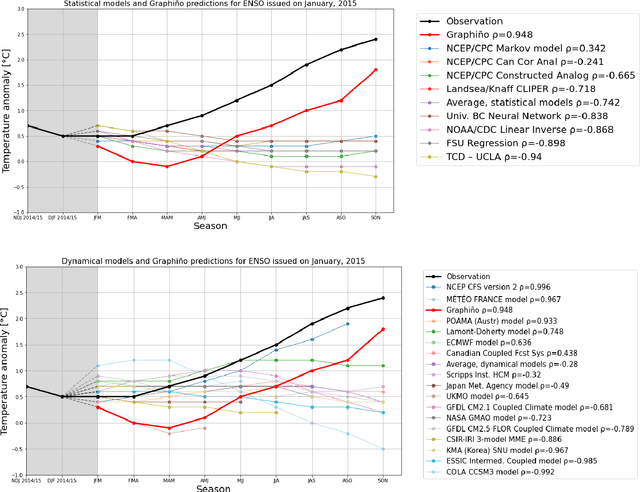
Deep learning-based models have recently outperformed state-of-the-art seasonal forecasting models, such as for predicting El Ni\~no-Southern Oscillation (ENSO). However, current deep learning models are based on convolutional neural networks which are difficult to interpret and can fail to model large-scale atmospheric patterns. In comparison, graph neural networks (GNNs) are capable of modeling large-scale spatial dependencies and are more interpretable due to the explicit modeling of information flow through edge connections. We propose the first application of graph neural networks to seasonal forecasting. We design a novel graph connectivity learning module that enables our GNN model to learn large-scale spatial interactions jointly with the actual ENSO forecasting task. Our model, \graphino, outperforms state-of-the-art deep learning-based models for forecasts up to six months ahead. Additionally, we show that our model is more interpretable as it learns sensible connectivity structures that correlate with the ENSO anomaly pattern.
Graph Neural Networks for Improved El Niño Forecasting
Dec 10, 2020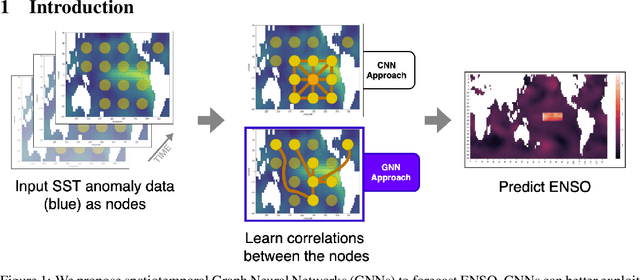

Deep learning-based models have recently outperformed state-of-the-art seasonal forecasting models, such as for predicting El Ni\~no-Southern Oscillation (ENSO). However, current deep learning models are based on convolutional neural networks which are difficult to interpret and can fail to model large-scale atmospheric patterns called teleconnections. Hence, we propose the application of spatiotemporal Graph Neural Networks (GNN) to forecast ENSO at long lead times, finer granularity and improved predictive skill than current state-of-the-art methods. The explicit modeling of information flow via edges may also allow for more interpretable forecasts. Preliminary results are promising and outperform state-of-the art systems for projections 1 and 3 months ahead.