 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIs the Last Layer Sufficient for Uncertainty Quantification?
May 29, 2026Epistemic uncertainty quantification (UQ) for deep neural networks (DNNs) is a requirement for safe adoption of AI in mission-critical settings. Several leading methods for UQ linearize DNNs to form Bayesian Generalized Linear Models (GLMs), where epistemic uncertainty is modeled via the predictive posterior distribution. Linearizing around the parameters of the final connected layer of a DNN is a commonly used approximation for reducing the computational burden of such GLMs, though it is often believed to come at the cost of degraded performance. In this work, we compare GLMs arising from full-network and last-layer linearization using both theoretical and empirical approaches. We first employ tools from random matrix theory to conduct a theoretical comparison; this analysis reveals no meaningful improvement in the UQ capabilities of full linearization. Coupled with a large-scale empirical evaluation across a range of modern machine learning tasks, we arrive at the following conclusion: a last-layer approximation yields comparable UQ performance while offering substantially improved computational efficiency.
Free Decompression with Algebraic Spectral Curves
May 05, 2026Tools from random matrix theory have become central to deep learning theory, using spectral information to provide mechanisms for modeling generalization, robustness, scaling, and failure modes. While often capable of modeling empirical behavior, practical computations are limited by matrix size, often imposing a restriction to models that are too small to be realistic. This motivates the inference of properties of larger models from the behavior of smaller ones. Free decompression (FD) is a recently proposed method for extrapolating spectral information across matrix sizes, but its utility is currently limited by strong assumptions that preclude its implementation on more realistic machine learning (ML) models. We use algebraic spectral curve theory to provide a general FD methodology for spectral densities whose Stieltjes transform satisfies an algebraic relation, a modeling assumption that is more likely to hold in practice. This recasts FD as an evolution along spectral curves which can be readily integrated. Our framework enables the expansion of spectral densities that have multiple or multi-modal bulks, that exist at multiple scales, and that contain atoms, all characteristic of real-world data and popular ML models. We demonstrate the efficacy of our framework on models of interest in modern ML, including Hessian and activation matrices associated with neural networks and large-scale diffusion models.
Spectral Estimation with Free Decompression
Jun 13, 2025



Computing eigenvalues of very large matrices is a critical task in many machine learning applications, including the evaluation of log-determinants, the trace of matrix functions, and other important metrics. As datasets continue to grow in scale, the corresponding covariance and kernel matrices become increasingly large, often reaching magnitudes that make their direct formation impractical or impossible. Existing techniques typically rely on matrix-vector products, which can provide efficient approximations, if the matrix spectrum behaves well. However, in settings like distributed learning, or when the matrix is defined only indirectly, access to the full data set can be restricted to only very small sub-matrices of the original matrix. In these cases, the matrix of nominal interest is not even available as an implicit operator, meaning that even matrix-vector products may not be available. In such settings, the matrix is "impalpable," in the sense that we have access to only masked snapshots of it. We draw on principles from free probability theory to introduce a novel method of "free decompression" to estimate the spectrum of such matrices. Our method can be used to extrapolate from the empirical spectral densities of small submatrices to infer the eigenspectrum of extremely large (impalpable) matrices (that we cannot form or even evaluate with full matrix-vector products). We demonstrate the effectiveness of this approach through a series of examples, comparing its performance against known limiting distributions from random matrix theory in synthetic settings, as well as applying it to submatrices of real-world datasets, matching them with their full empirical eigenspectra.
Determinant Estimation under Memory Constraints and Neural Scaling Laws
Mar 06, 2025Calculating or accurately estimating log-determinants of large positive semi-definite matrices is of fundamental importance in many machine learning tasks. While its cubic computational complexity can already be prohibitive, in modern applications, even storing the matrices themselves can pose a memory bottleneck. To address this, we derive a novel hierarchical algorithm based on block-wise computation of the LDL decomposition for large-scale log-determinant calculation in memory-constrained settings. In extreme cases where matrices are highly ill-conditioned, accurately computing the full matrix itself may be infeasible. This is particularly relevant when considering kernel matrices at scale, including the empirical Neural Tangent Kernel (NTK) of neural networks trained on large datasets. Under the assumption of neural scaling laws in the test error, we show that the ratio of pseudo-determinants satisfies a power-law relationship, allowing us to derive corresponding scaling laws. This enables accurate estimation of NTK log-determinants from a tiny fraction of the full dataset; in our experiments, this results in a $\sim$100,000$\times$ speedup with improved accuracy over competing approximations. Using these techniques, we successfully estimate log-determinants for dense matrices of extreme sizes, which were previously deemed intractable and inaccessible due to their enormous scale and computational demands.
Uncertainty Quantification with the Empirical Neural Tangent Kernel
Feb 05, 2025



While neural networks have demonstrated impressive performance across various tasks, accurately quantifying uncertainty in their predictions is essential to ensure their trustworthiness and enable widespread adoption in critical systems. Several Bayesian uncertainty quantification (UQ) methods exist that are either cheap or reliable, but not both. We propose a post-hoc, sampling-based UQ method for over-parameterized networks at the end of training. Our approach constructs efficient and meaningful deep ensembles by employing a (stochastic) gradient-descent sampling process on appropriately linearized networks. We demonstrate that our method effectively approximates the posterior of a Gaussian process using the empirical Neural Tangent Kernel. Through a series of numerical experiments, we show that our method not only outperforms competing approaches in computational efficiency (often reducing costs by multiple factors) but also maintains state-of-the-art performance across a variety of UQ metrics for both regression and classification tasks.
Temperature Optimization for Bayesian Deep Learning
Oct 08, 2024



The Cold Posterior Effect (CPE) is a phenomenon in Bayesian Deep Learning (BDL), where tempering the posterior to a cold temperature often improves the predictive performance of the posterior predictive distribution (PPD). Although the term `CPE' suggests colder temperatures are inherently better, the BDL community increasingly recognizes that this is not always the case. Despite this, there remains no systematic method for finding the optimal temperature beyond grid search. In this work, we propose a data-driven approach to select the temperature that maximizes test log-predictive density, treating the temperature as a model parameter and estimating it directly from the data. We empirically demonstrate that our method performs comparably to grid search, at a fraction of the cost, across both regression and classification tasks. Finally, we highlight the differing perspectives on CPE between the BDL and Generalized Bayes communities: while the former primarily focuses on predictive performance of the PPD, the latter emphasizes calibrated uncertainty and robustness to model misspecification; these distinct objectives lead to different temperature preferences.
Gradient-enhanced deep Gaussian processes for multifidelity modelling
Feb 25, 2024



Multifidelity models integrate data from multiple sources to produce a single approximator for the underlying process. Dense low-fidelity samples are used to reduce interpolation error, while sparse high-fidelity samples are used to compensate for bias or noise in the low-fidelity samples. Deep Gaussian processes (GPs) are attractive for multifidelity modelling as they are non-parametric, robust to overfitting, perform well for small datasets, and, critically, can capture nonlinear and input-dependent relationships between data of different fidelities. Many datasets naturally contain gradient data, especially when they are generated by computational models that are compatible with automatic differentiation or have adjoint solutions. Principally, this work extends deep GPs to incorporate gradient data. We demonstrate this method on an analytical test problem and a realistic partial differential equation problem, where we predict the aerodynamic coefficients of a hypersonic flight vehicle over a range of flight conditions and geometries. In both examples, the gradient-enhanced deep GP outperforms a gradient-enhanced linear GP model and their non-gradient-enhanced counterparts.
A PAC-Bayesian Perspective on the Interpolating Information Criterion
Nov 13, 2023Deep learning is renowned for its theory-practice gap, whereby principled theory typically fails to provide much beneficial guidance for implementation in practice. This has been highlighted recently by the benign overfitting phenomenon: when neural networks become sufficiently large to interpolate the dataset perfectly, model performance appears to improve with increasing model size, in apparent contradiction with the well-known bias-variance tradeoff. While such phenomena have proven challenging to theoretically study for general models, the recently proposed Interpolating Information Criterion (IIC) provides a valuable theoretical framework to examine performance for overparameterized models. Using the IIC, a PAC-Bayes bound is obtained for a general class of models, characterizing factors which influence generalization performance in the interpolating regime. From the provided bound, we quantify how the test error for overparameterized models achieving effectively zero training error depends on the quality of the implicit regularization imposed by e.g. the combination of model, optimizer, and parameter-initialization scheme; the spectrum of the empirical neural tangent kernel; curvature of the loss landscape; and noise present in the data.
The Interpolating Information Criterion for Overparameterized Models
Jul 15, 2023

The problem of model selection is considered for the setting of interpolating estimators, where the number of model parameters exceeds the size of the dataset. Classical information criteria typically consider the large-data limit, penalizing model size. However, these criteria are not appropriate in modern settings where overparameterized models tend to perform well. For any overparameterized model, we show that there exists a dual underparameterized model that possesses the same marginal likelihood, thus establishing a form of Bayesian duality. This enables more classical methods to be used in the overparameterized setting, revealing the Interpolating Information Criterion, a measure of model quality that naturally incorporates the choice of prior into the model selection. Our new information criterion accounts for prior misspecification, geometric and spectral properties of the model, and is numerically consistent with known empirical and theoretical behavior in this regime.
Monotonicity and Double Descent in Uncertainty Estimation with Gaussian Processes
Oct 14, 2022
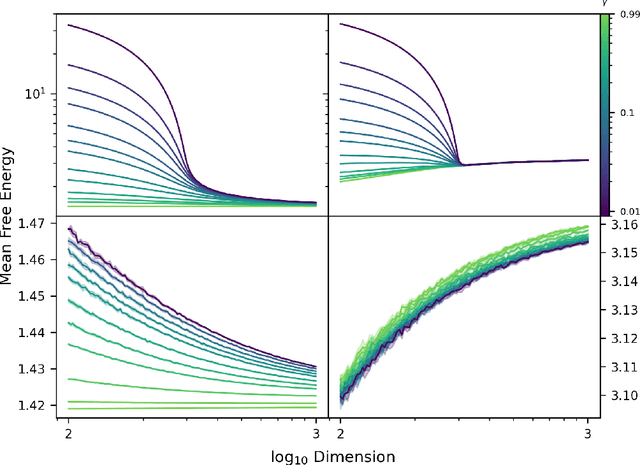
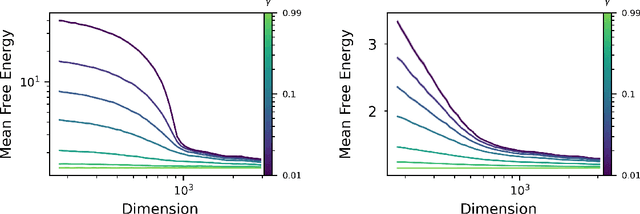
The quality of many modern machine learning models improves as model complexity increases, an effect that has been quantified, for predictive performance, with the non-monotonic double descent learning curve. Here, we address the overarching question: is there an analogous theory of double descent for models which estimate uncertainty? We provide a partially affirmative and partially negative answer in the setting of Gaussian processes (GP). Under standard assumptions, we prove that higher model quality for optimally-tuned GPs (including uncertainty prediction) under marginal likelihood is realized for larger input dimensions, and therefore exhibits a monotone error curve. After showing that marginal likelihood does not naturally exhibit double descent in the input dimension, we highlight related forms of posterior predictive loss that do exhibit non-monotonicity. Finally, we verify empirically that our results hold for real data, beyond our considered assumptions, and we explore consequences involving synthetic covariates.