 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModeling Behavioral Intensity and Transitions for Generative Recommendation
Apr 27, 2026Multi-behavior recommendation aims to predict user conversions by modeling various interaction types that carry distinct intent signals. Recently, generative sequence modeling methods have emerged as an important paradigm for multi-behavior recommendation by achieving flexible sequence generation. However, existing generative methods typically treat behaviors as auxiliary token features and feed them into unified attention mechanisms. These models implicitly assume uniform activation of dependencies among historical behaviors, thereby failing to discern differences in intensity or capture transition patterns. To address these limitations, we propose BITRec, a novel generative multi-behavior recommendation framework that introduces structured behavioral modeling through selective dependency activation. BITRec incorporates (i) Hierarchical Behavior Aggregation (HBA), which explicitly models behavioral intensity differences through separated exploration and commitment pathways, and (ii) Transition Relation Encoding (TRE), which encodes transition structures through explicit learnable relation matrices. Experiments on four large-scale datasets (RetailRocket, Taobao, Tmall, Insurance Dataset) with millions of interactions achieve consistent improvements of 15-23% across multiple metrics, with peak gains of 22.79% MRR on Tmall and 17.83% HR@10, 17.55% NDCG@10 on Taobao.
GLM-5: from Vibe Coding to Agentic Engineering
Feb 17, 2026We present GLM-5, a next-generation foundation model designed to transition the paradigm of vibe coding to agentic engineering. Building upon the agentic, reasoning, and coding (ARC) capabilities of its predecessor, GLM-5 adopts DSA to significantly reduce training and inference costs while maintaining long-context fidelity. To advance model alignment and autonomy, we implement a new asynchronous reinforcement learning infrastructure that drastically improves post-training efficiency by decoupling generation from training. Furthermore, we propose novel asynchronous agent RL algorithms that further improve RL quality, enabling the model to learn from complex, long-horizon interactions more effectively. Through these innovations, GLM-5 achieves state-of-the-art performance on major open benchmarks. Most critically, GLM-5 demonstrates unprecedented capability in real-world coding tasks, surpassing previous baselines in handling end-to-end software engineering challenges. Code, models, and more information are available at https://github.com/zai-org/GLM-5.
Tabular Incremental Inference
Jan 27, 2026Tabular data is a fundamental form of data structure. The evolution of table analysis tools reflects humanity's continuous progress in data acquisition, management, and processing. The dynamic changes in table columns arise from technological advancements, changing needs, data integration, etc. However, the standard process of training AI models on tables with fixed columns and then performing inference is not suitable for handling dynamically changed tables. Therefore, new methods are needed for efficiently handling such tables in an unsupervised manner. In this paper, we introduce a new task, Tabular Incremental Inference (TabII), which aims to enable trained models to incorporate new columns during the inference stage, enhancing the practicality of AI models in scenarios where tables are dynamically changed. Furthermore, we demonstrate that this new task can be framed as an optimization problem based on the information bottleneck theory, which emphasizes that the key to an ideal tabular incremental inference approach lies in minimizing mutual information between tabular data and representation while maximizing between representation and task labels. Under this guidance, we design a TabII method with Large Language Model placeholders and Pretrained TabAdapter to provide external knowledge and Incremental Sample Condensation blocks to condense the task-relevant information given by incremental column attributes. Experimental results across eight public datasets show that TabII effectively utilizes incremental attributes, achieving state-of-the-art performance.
The Forecast Critic: Leveraging Large Language Models for Poor Forecast Identification
Dec 12, 2025



Monitoring forecasting systems is critical for customer satisfaction, profitability, and operational efficiency in large-scale retail businesses. We propose The Forecast Critic, a system that leverages Large Language Models (LLMs) for automated forecast monitoring, taking advantage of their broad world knowledge and strong ``reasoning'' capabilities. As a prerequisite for this, we systematically evaluate the ability of LLMs to assess time series forecast quality, focusing on three key questions. (1) Can LLMs be deployed to perform forecast monitoring and identify obviously unreasonable forecasts? (2) Can LLMs effectively incorporate unstructured exogenous features to assess what a reasonable forecast looks like? (3) How does performance vary across model sizes and reasoning capabilities, measured across state-of-the-art LLMs? We present three experiments, including on both synthetic and real-world forecasting data. Our results show that LLMs can reliably detect and critique poor forecasts, such as those plagued by temporal misalignment, trend inconsistencies, and spike errors. The best-performing model we evaluated achieves an F1 score of 0.88, somewhat below human-level performance (F1 score: 0.97). We also demonstrate that multi-modal LLMs can effectively incorporate unstructured contextual signals to refine their assessment of the forecast. Models correctly identify missing or spurious promotional spikes when provided with historical context about past promotions (F1 score: 0.84). Lastly, we demonstrate that these techniques succeed in identifying inaccurate forecasts on the real-world M5 time series dataset, with unreasonable forecasts having an sCRPS at least 10% higher than that of reasonable forecasts. These findings suggest that LLMs, even without domain-specific fine-tuning, may provide a viable and scalable option for automated forecast monitoring and evaluation.
Mind the Gaps: Auditing and Reducing Group Inequity in Large-Scale Mobility Prediction
Oct 30, 2025Next location prediction underpins a growing number of mobility, retail, and public-health applications, yet its societal impacts remain largely unexplored. In this paper, we audit state-of-the-art mobility prediction models trained on a large-scale dataset, highlighting hidden disparities based on user demographics. Drawing from aggregate census data, we compute the difference in predictive performance on racial and ethnic user groups and show a systematic disparity resulting from the underlying dataset, resulting in large differences in accuracy based on location and user groups. To address this, we propose Fairness-Guided Incremental Sampling (FGIS), a group-aware sampling strategy designed for incremental data collection settings. Because individual-level demographic labels are unavailable, we introduce Size-Aware K-Means (SAKM), a clustering method that partitions users in latent mobility space while enforcing census-derived group proportions. This yields proxy racial labels for the four largest groups in the state: Asian, Black, Hispanic, and White. Built on these labels, our sampling algorithm prioritizes users based on expected performance gains and current group representation. This method incrementally constructs training datasets that reduce demographic performance gaps while preserving overall accuracy. Our method reduces total disparity between groups by up to 40\% with minimal accuracy trade-offs, as evaluated on a state-of-art MetaPath2Vec model and a transformer-encoder model. Improvements are most significant in early sampling stages, highlighting the potential for fairness-aware strategies to deliver meaningful gains even in low-resource settings. Our findings expose structural inequities in mobility prediction pipelines and demonstrate how lightweight, data-centric interventions can improve fairness with little added complexity, especially for low-data applications.
Efficiently Generating Correlated Sample Paths from Multi-step Time Series Foundation Models
Oct 02, 2025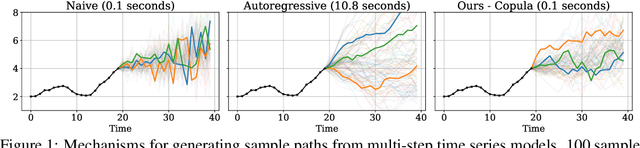
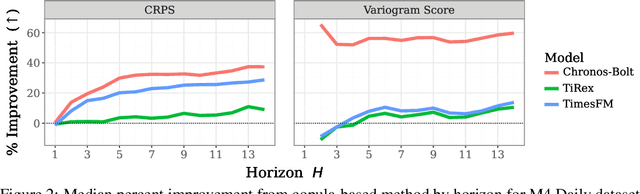
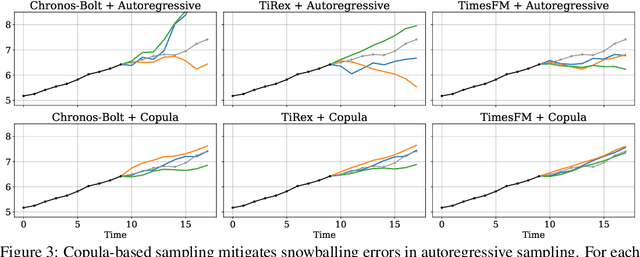
Many time series applications require access to multi-step forecast trajectories in the form of sample paths. Recently, time series foundation models have leveraged multi-step lookahead predictions to improve the quality and efficiency of multi-step forecasts. However, these models only predict independent marginal distributions for each time step, rather than a full joint predictive distribution. To generate forecast sample paths with realistic correlation structures, one typically resorts to autoregressive sampling, which can be extremely expensive. In this paper, we present a copula-based approach to efficiently generate accurate, correlated sample paths from existing multi-step time series foundation models in one forward pass. Our copula-based approach generates correlated sample paths orders of magnitude faster than autoregressive sampling, and it yields improved sample path quality by mitigating the snowballing error phenomenon.
GLM-4.5: Agentic, Reasoning, and Coding (ARC) Foundation Models
Aug 08, 2025We present GLM-4.5, an open-source Mixture-of-Experts (MoE) large language model with 355B total parameters and 32B activated parameters, featuring a hybrid reasoning method that supports both thinking and direct response modes. Through multi-stage training on 23T tokens and comprehensive post-training with expert model iteration and reinforcement learning, GLM-4.5 achieves strong performance across agentic, reasoning, and coding (ARC) tasks, scoring 70.1% on TAU-Bench, 91.0% on AIME 24, and 64.2% on SWE-bench Verified. With much fewer parameters than several competitors, GLM-4.5 ranks 3rd overall among all evaluated models and 2nd on agentic benchmarks. We release both GLM-4.5 (355B parameters) and a compact version, GLM-4.5-Air (106B parameters), to advance research in reasoning and agentic AI systems. Code, models, and more information are available at https://github.com/zai-org/GLM-4.5.
Gradient-Adaptive Policy Optimization: Towards Multi-Objective Alignment of Large Language Models
Jul 02, 2025Reinforcement Learning from Human Feedback (RLHF) has emerged as a powerful technique for aligning large language models (LLMs) with human preferences. However, effectively aligning LLMs with diverse human preferences remains a significant challenge, particularly when they are conflict. To address this issue, we frame human value alignment as a multi-objective optimization problem, aiming to maximize a set of potentially conflicting objectives. We introduce Gradient-Adaptive Policy Optimization (GAPO), a novel fine-tuning paradigm that employs multiple-gradient descent to align LLMs with diverse preference distributions. GAPO adaptively rescales the gradients for each objective to determine an update direction that optimally balances the trade-offs between objectives. Additionally, we introduce P-GAPO, which incorporates user preferences across different objectives and achieves Pareto solutions that better align with the user's specific needs. Our theoretical analysis demonstrates that GAPO converges towards a Pareto optimal solution for multiple objectives. Empirical results on Mistral-7B show that GAPO outperforms current state-of-the-art methods, achieving superior performance in both helpfulness and harmlessness.
Non-Uniform Class-Wise Coreset Selection: Characterizing Category Difficulty for Data-Efficient Transfer Learning
Apr 17, 2025



As transfer learning models and datasets grow larger, efficient adaptation and storage optimization have become critical needs. Coreset selection addresses these challenges by identifying and retaining the most informative samples, constructing a compact subset for target domain training. However, current methods primarily rely on instance-level difficulty assessments, overlooking crucial category-level characteristics and consequently under-representing minority classes. To overcome this limitation, we propose Non-Uniform Class-Wise Coreset Selection (NUCS), a novel framework that integrates both class-level and instance-level criteria. NUCS automatically allocates data selection budgets for each class based on intrinsic category difficulty and adaptively selects samples within optimal difficulty ranges. By explicitly incorporating category-specific insights, our approach achieves a more balanced and representative coreset, addressing key shortcomings of prior methods. Comprehensive theoretical analysis validates the rationale behind adaptive budget allocation and sample selection, while extensive experiments across 14 diverse datasets and model architectures demonstrate NUCS's consistent improvements over state-of-the-art methods, achieving superior accuracy and computational efficiency. Notably, on CIFAR100 and Food101, NUCS matches full-data training accuracy while retaining just 30% of samples and reducing computation time by 60%. Our work highlights the importance of characterizing category difficulty in coreset selection, offering a robust and data-efficient solution for transfer learning.
Controlling Large Language Models Through Concept Activation Vectors
Jan 10, 2025



As large language models (LLMs) are widely deployed across various domains, the ability to control their generated outputs has become more critical. This control involves aligning LLMs outputs with human values and ethical principles or customizing LLMs on specific topics or styles for individual users. Existing controlled generation methods either require significant computational resources and extensive trial-and-error or provide coarse-grained control. In this paper, we propose Generation with Concept Activation Vector (GCAV), a lightweight model control framework that ensures accurate control without requiring resource-extensive fine-tuning. Specifically, GCAV first trains a concept activation vector for specified concepts to be controlled, such as toxicity. During inference, GCAV steers the concept vector in LLMs, for example, by removing the toxicity concept vector from the activation layers. Control experiments from different perspectives, including toxicity reduction, sentiment control, linguistic style, and topic control, demonstrate that our framework achieves state-of-the-art performance with granular control, allowing for fine-grained adjustments of both the steering layers and the steering magnitudes for individual samples.