 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTreeBoN: Enhancing Inference-Time Alignment with Speculative Tree-Search and Best-of-N Sampling
Oct 18, 2024



Inference-time alignment enhances the performance of large language models without requiring additional training or fine-tuning but presents challenges due to balancing computational efficiency with high-quality output. Best-of-N (BoN) sampling, as a simple yet powerful approach, generates multiple responses and selects the best one, achieving improved performance but with a high computational cost. We propose TreeBoN, a novel framework that integrates a speculative tree-search strategy into Best-of-N (BoN) Sampling. TreeBoN maintains a set of parent nodes, iteratively branching and pruning low-quality responses, thereby reducing computational overhead while maintaining high output quality. Our approach also leverages token-level rewards from Direct Preference Optimization (DPO) to guide tree expansion and prune low-quality paths. We evaluate TreeBoN using AlpacaFarm, UltraFeedback, GSM8K, HH-RLHF, and TutorEval datasets, demonstrating consistent improvements. Specifically, TreeBoN achieves a 65% win rate at maximum lengths of 192 and 384 tokens, outperforming standard BoN with the same computational cost. Furthermore, TreeBoN achieves around a 60% win rate across longer responses, showcasing its scalability and alignment efficacy.
A Common Pitfall of Margin-based Language Model Alignment: Gradient Entanglement
Oct 17, 2024Reinforcement Learning from Human Feedback (RLHF) has become the predominant approach for language model (LM) alignment. At its core, RLHF uses a margin-based loss for preference optimization, specifying ideal LM behavior only by the difference between preferred and dispreferred responses. In this paper, we identify a common pitfall of margin-based methods -- the under-specification of ideal LM behavior on preferred and dispreferred responses individually, which leads to two unintended consequences as the margin increases: (1) The probability of dispreferred (e.g., unsafe) responses may increase, resulting in potential safety alignment failures. (2) The probability of preferred responses may decrease, even when those responses are ideal. We demystify the reasons behind these problematic behaviors: margin-based losses couple the change in the preferred probability to the gradient of the dispreferred one, and vice versa, often preventing the preferred probability from increasing while the dispreferred one decreases, and thus causing a synchronized increase or decrease in both probabilities. We term this effect, inherent in margin-based objectives, gradient entanglement. Formally, we derive conditions for general margin-based alignment objectives under which gradient entanglement becomes concerning: the inner product of the gradients of preferred and dispreferred log-probabilities is large relative to the individual gradient norms. We theoretically investigate why such inner products can be large when aligning language models and empirically validate our findings. Empirical implications of our framework extend to explaining important differences in the training dynamics of various preference optimization algorithms, and suggesting potential algorithm designs to mitigate the under-specification issue of margin-based methods and thereby improving language model alignment.
COMET: Towards Partical W4A4KV4 LLMs Serving
Oct 16, 2024



Quantization is a widely-used compression technology to reduce the overhead of serving large language models (LLMs) on terminal devices and in cloud data centers. However, prevalent quantization methods, such as 8-bit weight-activation or 4-bit weight-only quantization, achieve limited performance improvements due to poor support for low-precision (e.g., 4-bit) activation. This work, for the first time, realizes practical W4A4KV4 serving for LLMs, fully utilizing the INT4 tensor cores on modern GPUs and reducing the memory bottleneck caused by the KV cache. Specifically, we propose a novel fine-grained mixed-precision quantization algorithm (FMPQ) that compresses most activations into 4-bit with negligible accuracy loss. To support mixed-precision matrix multiplication for W4A4 and W4A8, we develop a highly optimized W4Ax kernel. Our approach introduces a novel mixed-precision data layout to facilitate access and fast dequantization for activation and weight tensors, utilizing the GPU's software pipeline to hide the overhead of data loading and conversion. Additionally, we propose fine-grained streaming multiprocessor (SM) scheduling to achieve load balance across different SMs. We integrate the optimized W4Ax kernel into our inference framework, COMET, and provide efficient management to support popular LLMs such as LLaMA-3-70B. Extensive evaluations demonstrate that, when running LLaMA family models on a single A100-80G-SMX4, COMET achieves a kernel-level speedup of \textbf{$2.88\times$} over cuBLAS and a \textbf{$2.02 \times$} throughput improvement compared to TensorRT-LLM from an end-to-end framework perspective.
Rectified Diffusion: Straightness Is Not Your Need in Rectified Flow
Oct 09, 2024Diffusion models have greatly improved visual generation but are hindered by slow generation speed due to the computationally intensive nature of solving generative ODEs. Rectified flow, a widely recognized solution, improves generation speed by straightening the ODE path. Its key components include: 1) using the diffusion form of flow-matching, 2) employing $\boldsymbol v$-prediction, and 3) performing rectification (a.k.a. reflow). In this paper, we argue that the success of rectification primarily lies in using a pretrained diffusion model to obtain matched pairs of noise and samples, followed by retraining with these matched noise-sample pairs. Based on this, components 1) and 2) are unnecessary. Furthermore, we highlight that straightness is not an essential training target for rectification; rather, it is a specific case of flow-matching models. The more critical training target is to achieve a first-order approximate ODE path, which is inherently curved for models like DDPM and Sub-VP. Building on this insight, we propose Rectified Diffusion, which generalizes the design space and application scope of rectification to encompass the broader category of diffusion models, rather than being restricted to flow-matching models. We validate our method on Stable Diffusion v1-5 and Stable Diffusion XL. Our method not only greatly simplifies the training procedure of rectified flow-based previous works (e.g., InstaFlow) but also achieves superior performance with even lower training cost. Our code is available at https://github.com/G-U-N/Rectified-Diffusion.
IterComp: Iterative Composition-Aware Feedback Learning from Model Gallery for Text-to-Image Generation
Oct 09, 2024



Advanced diffusion models like RPG, Stable Diffusion 3 and FLUX have made notable strides in compositional text-to-image generation. However, these methods typically exhibit distinct strengths for compositional generation, with some excelling in handling attribute binding and others in spatial relationships. This disparity highlights the need for an approach that can leverage the complementary strengths of various models to comprehensively improve the composition capability. To this end, we introduce IterComp, a novel framework that aggregates composition-aware model preferences from multiple models and employs an iterative feedback learning approach to enhance compositional generation. Specifically, we curate a gallery of six powerful open-source diffusion models and evaluate their three key compositional metrics: attribute binding, spatial relationships, and non-spatial relationships. Based on these metrics, we develop a composition-aware model preference dataset comprising numerous image-rank pairs to train composition-aware reward models. Then, we propose an iterative feedback learning method to enhance compositionality in a closed-loop manner, enabling the progressive self-refinement of both the base diffusion model and reward models over multiple iterations. Theoretical proof demonstrates the effectiveness and extensive experiments show our significant superiority over previous SOTA methods (e.g., Omost and FLUX), particularly in multi-category object composition and complex semantic alignment. IterComp opens new research avenues in reward feedback learning for diffusion models and compositional generation. Code: https://github.com/YangLing0818/IterComp
AIME: AI System Optimization via Multiple LLM Evaluators
Oct 04, 2024Text-based AI system optimization typically involves a feedback loop scheme where a single LLM generates an evaluation in natural language of the current output to improve the next iteration's output. However, in this work, we empirically demonstrate that for a practical and complex task (code generation) with multiple criteria to evaluate, utilizing only one LLM evaluator tends to let errors in generated code go undetected, thus leading to incorrect evaluations and ultimately suboptimal test case performance. Motivated by this failure case, we assume there exists an optimal evaluation policy that samples an evaluation between response and ground truth. We then theoretically prove that a linear combination of multiple evaluators can approximate this optimal policy. From this insight, we propose AI system optimization via Multiple LLM Evaluators (AIME). AIME is an evaluation protocol that utilizes multiple LLMs that each independently generate an evaluation on separate criteria and then combine them via concatenation. We provide an extensive empirical study showing AIME outperforming baseline methods in code generation tasks, with up to $62\%$ higher error detection rate and up to $16\%$ higher success rate than a single LLM evaluation protocol on LeetCodeHard and HumanEval datasets. We also show that the selection of the number of evaluators and which criteria to utilize is non-trivial as it can impact pact success rate by up to $12\%$.
Latent Diffusion Models for Controllable RNA Sequence Generation
Sep 15, 2024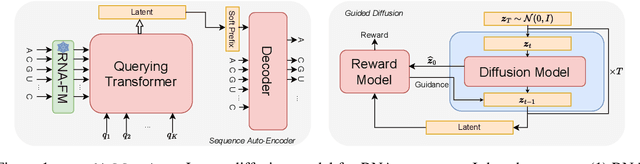
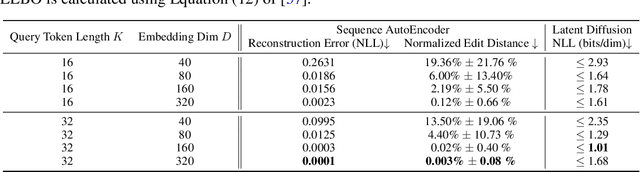

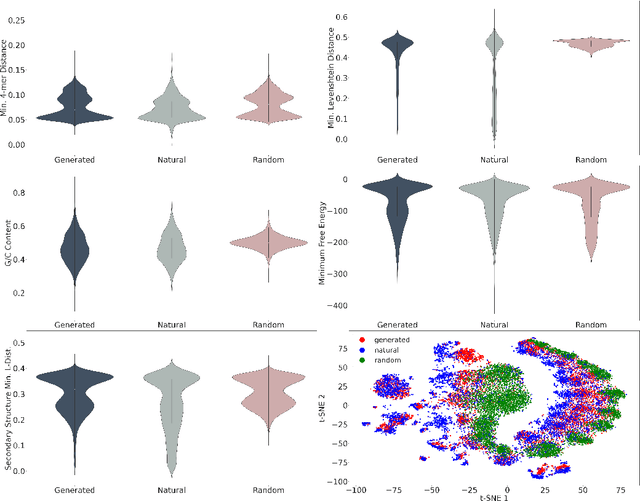
This paper presents RNAdiffusion, a latent diffusion model for generating and optimizing discrete RNA sequences. RNA is a particularly dynamic and versatile molecule in biological processes. RNA sequences exhibit high variability and diversity, characterized by their variable lengths, flexible three-dimensional structures, and diverse functions. We utilize pretrained BERT-type models to encode raw RNAs into token-level biologically meaningful representations. A Q-Former is employed to compress these representations into a fixed-length set of latent vectors, with an autoregressive decoder trained to reconstruct RNA sequences from these latent variables. We then develop a continuous diffusion model within this latent space. To enable optimization, we train reward networks to estimate functional properties of RNA from the latent variables. We employ gradient-based guidance during the backward diffusion process, aiming to generate RNA sequences that are optimized for higher rewards. Empirical experiments confirm that RNAdiffusion generates non-coding RNAs that align with natural distributions across various biological indicators. We fine-tuned the diffusion model on untranslated regions (UTRs) of mRNA and optimize sample sequences for protein translation efficiencies. Our guided diffusion model effectively generates diverse UTR sequences with high Mean Ribosome Loading (MRL) and Translation Efficiency (TE), surpassing baselines. These results hold promise for studies on RNA sequence-function relationships, protein synthesis, and enhancing therapeutic RNA design.
Relative-Translation Invariant Wasserstein Distance
Sep 04, 2024



We introduce a new family of distances, relative-translation invariant Wasserstein distances ($RW_p$), for measuring the similarity of two probability distributions under distribution shift. Generalizing it from the classical optimal transport model, we show that $RW_p$ distances are also real distance metrics defined on the quotient set $\mathcal{P}_p(\mathbb{R}^n)/\sim$ and invariant to distribution translations. When $p=2$, the $RW_2$ distance enjoys more exciting properties, including decomposability of the optimal transport model, translation-invariance of the $RW_2$ distance, and a Pythagorean relationship between $RW_2$ and the classical quadratic Wasserstein distance ($W_2$). Based on these properties, we show that a distribution shift, measured by $W_2$ distance, can be explained in the bias-variance perspective. In addition, we propose a variant of the Sinkhorn algorithm, named $RW_2$ Sinkhorn algorithm, for efficiently calculating $RW_2$ distance, coupling solutions, as well as $W_2$ distance. We also provide the analysis of numerical stability and time complexity for the proposed algorithm. Finally, we validate the $RW_2$ distance metric and the algorithm performance with three experiments. We conduct one numerical validation for the $RW_2$ Sinkhorn algorithm and show two real-world applications demonstrating the effectiveness of using $RW_2$ under distribution shift: digits recognition and similar thunderstorm detection. The experimental results report that our proposed algorithm significantly improves the computational efficiency of Sinkhorn in certain practical applications, and the $RW_2$ distance is robust to distribution translations compared with baselines.
Conversational Dueling Bandits in Generalized Linear Models
Jul 26, 2024



Conversational recommendation systems elicit user preferences by interacting with users to obtain their feedback on recommended commodities. Such systems utilize a multi-armed bandit framework to learn user preferences in an online manner and have received great success in recent years. However, existing conversational bandit methods have several limitations. First, they only enable users to provide explicit binary feedback on the recommended items or categories, leading to ambiguity in interpretation. In practice, users are usually faced with more than one choice. Relative feedback, known for its informativeness, has gained increasing popularity in recommendation system design. Moreover, current contextual bandit methods mainly work under linear reward assumptions, ignoring practical non-linear reward structures in generalized linear models. Therefore, in this paper, we introduce relative feedback-based conversations into conversational recommendation systems through the integration of dueling bandits in generalized linear models (GLM) and propose a novel conversational dueling bandit algorithm called ConDuel. Theoretical analyses of regret upper bounds and empirical validations on synthetic and real-world data underscore ConDuel's efficacy. We also demonstrate the potential to extend our algorithm to multinomial logit bandits with theoretical and experimental guarantees, which further proves the applicability of the proposed framework.
Diffusion Transformer Captures Spatial-Temporal Dependencies: A Theory for Gaussian Process Data
Jul 23, 2024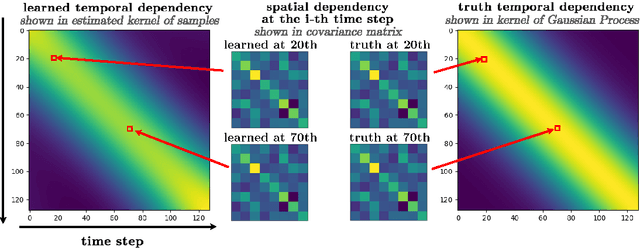
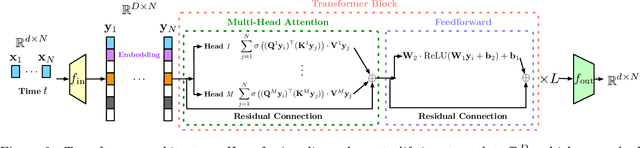

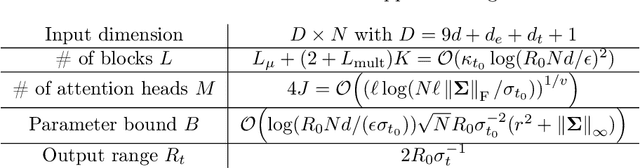
Diffusion Transformer, the backbone of Sora for video generation, successfully scales the capacity of diffusion models, pioneering new avenues for high-fidelity sequential data generation. Unlike static data such as images, sequential data consists of consecutive data frames indexed by time, exhibiting rich spatial and temporal dependencies. These dependencies represent the underlying dynamic model and are critical to validate the generated data. In this paper, we make the first theoretical step towards bridging diffusion transformers for capturing spatial-temporal dependencies. Specifically, we establish score approximation and distribution estimation guarantees of diffusion transformers for learning Gaussian process data with covariance functions of various decay patterns. We highlight how the spatial-temporal dependencies are captured and affect learning efficiency. Our study proposes a novel transformer approximation theory, where the transformer acts to unroll an algorithm. We support our theoretical results by numerical experiments, providing strong evidence that spatial-temporal dependencies are captured within attention layers, aligning with our approximation theory.