 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFully Authentic Visual Question Answering Dataset from Online Communities
Nov 27, 2023



Visual Question Answering (VQA) entails answering questions about images. We introduce the first VQA dataset in which all contents originate from an authentic use case. Sourced from online question answering community forums, we call it VQAonline. We then characterize our dataset and how it relates to eight other VQA datasets. Observing that answers in our dataset tend to be much longer (e.g., with a mean of 173 words) and thus incompatible with standard VQA evaluation metrics, we next analyze which of the six popular metrics for longer text evaluation align best with human judgments. We then use the best-suited metrics to evaluate six state-of-the-art vision and language foundation models on VQAonline and reveal where they struggle most. We will release the dataset soon to facilitate future extensions.
On the Hidden Waves of Image
Oct 19, 2023



In this paper, we introduce an intriguing phenomenon-the successful reconstruction of images using a set of one-way wave equations with hidden and learnable speeds. Each individual image corresponds to a solution with a unique initial condition, which can be computed from the original image using a visual encoder (e.g., a convolutional neural network). Furthermore, the solution for each image exhibits two noteworthy mathematical properties: (a) it can be decomposed into a collection of special solutions of the same one-way wave equations that are first-order autoregressive, with shared coefficient matrices for autoregression, and (b) the product of these coefficient matrices forms a diagonal matrix with the speeds of the wave equations as its diagonal elements. We term this phenomenon hidden waves, as it reveals that, although the speeds of the set of wave equations and autoregressive coefficient matrices are latent, they are both learnable and shared across images. This represents a mathematical invariance across images, providing a new mathematical perspective to understand images.
Learning from Rich Semantics and Coarse Locations for Long-tailed Object Detection
Oct 18, 2023



Long-tailed object detection (LTOD) aims to handle the extreme data imbalance in real-world datasets, where many tail classes have scarce instances. One popular strategy is to explore extra data with image-level labels, yet it produces limited results due to (1) semantic ambiguity -- an image-level label only captures a salient part of the image, ignoring the remaining rich semantics within the image; and (2) location sensitivity -- the label highly depends on the locations and crops of the original image, which may change after data transformations like random cropping. To remedy this, we propose RichSem, a simple but effective method, which is robust to learn rich semantics from coarse locations without the need of accurate bounding boxes. RichSem leverages rich semantics from images, which are then served as additional soft supervision for training detectors. Specifically, we add a semantic branch to our detector to learn these soft semantics and enhance feature representations for long-tailed object detection. The semantic branch is only used for training and is removed during inference. RichSem achieves consistent improvements on both overall and rare-category of LVIS under different backbones and detectors. Our method achieves state-of-the-art performance without requiring complex training and testing procedures. Moreover, we show the effectiveness of our method on other long-tailed datasets with additional experiments. Code is available at \url{https://github.com/MengLcool/RichSem}.
Foundation Models Meet Visualizations: Challenges and Opportunities
Oct 09, 2023


Recent studies have indicated that foundation models, such as BERT and GPT, excel in adapting to a variety of downstream tasks. This adaptability has established them as the dominant force in building artificial intelligence (AI) systems. As visualization techniques intersect with these models, a new research paradigm emerges. This paper divides these intersections into two main areas: visualizations for foundation models (VIS4FM) and foundation models for visualizations (FM4VIS). In VIS4FM, we explore the primary role of visualizations in understanding, refining, and evaluating these intricate models. This addresses the pressing need for transparency, explainability, fairness, and robustness. Conversely, within FM4VIS, we highlight how foundation models can be utilized to advance the visualization field itself. The confluence of foundation models and visualizations holds great promise, but it also comes with its own set of challenges. By highlighting these challenges and the growing opportunities, this paper seeks to provide a starting point for continued exploration in this promising avenue.
TinyCLIP: CLIP Distillation via Affinity Mimicking and Weight Inheritance
Sep 21, 2023In this paper, we propose a novel cross-modal distillation method, called TinyCLIP, for large-scale language-image pre-trained models. The method introduces two core techniques: affinity mimicking and weight inheritance. Affinity mimicking explores the interaction between modalities during distillation, enabling student models to mimic teachers' behavior of learning cross-modal feature alignment in a visual-linguistic affinity space. Weight inheritance transmits the pre-trained weights from the teacher models to their student counterparts to improve distillation efficiency. Moreover, we extend the method into a multi-stage progressive distillation to mitigate the loss of informative weights during extreme compression. Comprehensive experiments demonstrate the efficacy of TinyCLIP, showing that it can reduce the size of the pre-trained CLIP ViT-B/32 by 50%, while maintaining comparable zero-shot performance. While aiming for comparable performance, distillation with weight inheritance can speed up the training by 1.4 - 7.8 $\times$ compared to training from scratch. Moreover, our TinyCLIP ViT-8M/16, trained on YFCC-15M, achieves an impressive zero-shot top-1 accuracy of 41.1% on ImageNet, surpassing the original CLIP ViT-B/16 by 3.5% while utilizing only 8.9% parameters. Finally, we demonstrate the good transferability of TinyCLIP in various downstream tasks. Code and models will be open-sourced at https://aka.ms/tinyclip.
Image is First-order Norm+Linear Autoregressive
May 25, 2023This paper reveals that every image can be understood as a first-order norm+linear autoregressive process, referred to as FINOLA, where norm+linear denotes the use of normalization before the linear model. We demonstrate that images of size 256$\times$256 can be reconstructed from a compressed vector using autoregression up to a 16$\times$16 feature map, followed by upsampling and convolution. This discovery sheds light on the underlying partial differential equations (PDEs) governing the latent feature space. Additionally, we investigate the application of FINOLA for self-supervised learning through a simple masked prediction technique. By encoding a single unmasked quadrant block, we can autoregressively predict the surrounding masked region. Remarkably, this pre-trained representation proves effective for image classification and object detection tasks, even in lightweight networks, without requiring fine-tuning. The code will be made publicly available.
Layer Grafted Pre-training: Bridging Contrastive Learning And Masked Image Modeling For Label-Efficient Representations
Feb 27, 2023Recently, both Contrastive Learning (CL) and Mask Image Modeling (MIM) demonstrate that self-supervision is powerful to learn good representations. However, naively combining them is far from success. In this paper, we start by making the empirical observation that a naive joint optimization of CL and MIM losses leads to conflicting gradient directions - more severe as the layers go deeper. This motivates us to shift the paradigm from combining loss at the end, to choosing the proper learning method per network layer. Inspired by experimental observations, we find that MIM and CL are suitable to lower and higher layers, respectively. We hence propose to combine them in a surprisingly simple, "sequential cascade" fashion: early layers are first trained under one MIM loss, on top of which latter layers continue to be trained under another CL loss. The proposed Layer Grafted Pre-training learns good visual representations that demonstrate superior label efficiency in downstream applications, in particular yielding strong few-shot performance besides linear evaluation. For instance, on ImageNet-1k, Layer Grafted Pre-training yields 65.5% Top-1 accuracy in terms of 1% few-shot learning with ViT-B/16, which improves MIM and CL baselines by 14.4% and 2.1% with no bells and whistles. The code is available at https://github.com/VITA-Group/layerGraftedPretraining_ICLR23.git.
Masked Video Distillation: Rethinking Masked Feature Modeling for Self-supervised Video Representation Learning
Dec 08, 2022Benefiting from masked visual modeling, self-supervised video representation learning has achieved remarkable progress. However, existing methods focus on learning representations from scratch through reconstructing low-level features like raw pixel RGB values. In this paper, we propose masked video distillation (MVD), a simple yet effective two-stage masked feature modeling framework for video representation learning: firstly we pretrain an image (or video) model by recovering low-level features of masked patches, then we use the resulting features as targets for masked feature modeling. For the choice of teacher models, we observe that students taught by video teachers perform better on temporally-heavy video tasks, while image teachers transfer stronger spatial representations for spatially-heavy video tasks. Visualization analysis also indicates different teachers produce different learned patterns for students. Motivated by this observation, to leverage the advantage of different teachers, we design a spatial-temporal co-teaching method for MVD. Specifically, we distill student models from both video teachers and image teachers by masked feature modeling. Extensive experimental results demonstrate that video transformers pretrained with spatial-temporal co-teaching outperform models distilled with a single teacher on a multitude of video datasets. Our MVD with vanilla ViT achieves state-of-the-art performance compared with previous supervised or self-supervised methods on several challenging video downstream tasks. For example, with the ViT-Large model, our MVD achieves 86.4% and 75.9% Top-1 accuracy on Kinetics-400 and Something-Something-v2, outperforming VideoMAE by 1.2% and 1.6% respectively. Code will be available at \url{https://github.com/ruiwang2021/mvd}.
Self-Supervised Learning based on Heat Equation
Nov 23, 2022This paper presents a new perspective of self-supervised learning based on extending heat equation into high dimensional feature space. In particular, we remove time dependence by steady-state condition, and extend the remaining 2D Laplacian from x--y isotropic to linear correlated. Furthermore, we simplify it by splitting x and y axes as two first-order linear differential equations. Such simplification explicitly models the spatial invariance along horizontal and vertical directions separately, supporting prediction across image blocks. This introduces a very simple masked image modeling (MIM) method, named QB-Heat. QB-Heat leaves a single block with size of quarter image unmasked and extrapolates other three masked quarters linearly. It brings MIM to CNNs without bells and whistles, and even works well for pre-training light-weight networks that are suitable for both image classification and object detection without fine-tuning. Compared with MoCo-v2 on pre-training a Mobile-Former with 5.8M parameters and 285M FLOPs, QB-Heat is on par in linear probing on ImageNet, but clearly outperforms in non-linear probing that adds a transformer block before linear classifier (65.6% vs. 52.9%). When transferring to object detection with frozen backbone, QB-Heat outperforms MoCo-v2 and supervised pre-training on ImageNet by 7.9 and 4.5 AP respectively. This work provides an insightful hypothesis on the invariance within visual representation over different shapes and textures: the linear relationship between horizontal and vertical derivatives. The code will be publicly released.
Video Mobile-Former: Video Recognition with Efficient Global Spatial-temporal Modeling
Aug 25, 2022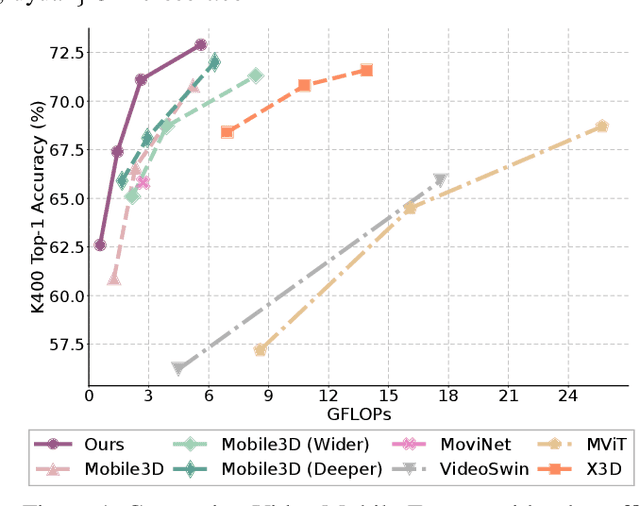
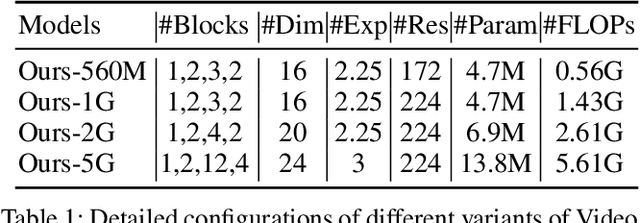
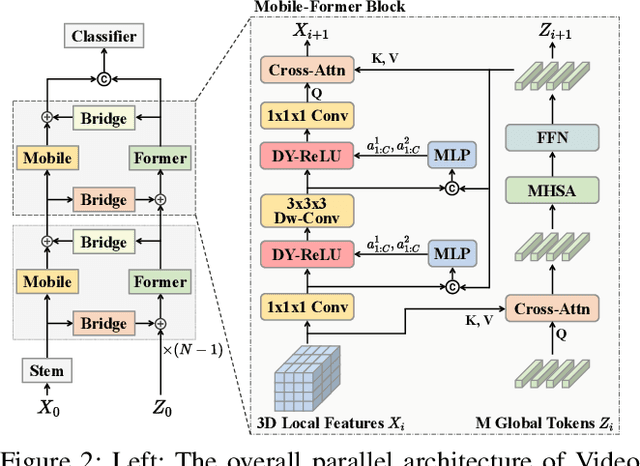
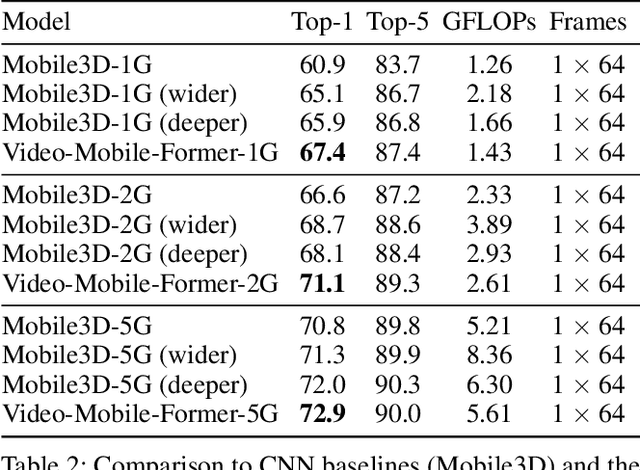
Transformer-based models have achieved top performance on major video recognition benchmarks. Benefiting from the self-attention mechanism, these models show stronger ability of modeling long-range dependencies compared to CNN-based models. However, significant computation overheads, resulted from the quadratic complexity of self-attention on top of a tremendous number of tokens, limit the use of existing video transformers in applications with limited resources like mobile devices. In this paper, we extend Mobile-Former to Video Mobile-Former, which decouples the video architecture into a lightweight 3D-CNNs for local context modeling and a Transformer modules for global interaction modeling in a parallel fashion. To avoid significant computational cost incurred by computing self-attention between the large number of local patches in videos, we propose to use very few global tokens (e.g., 6) for a whole video in Transformers to exchange information with 3D-CNNs with a cross-attention mechanism. Through efficient global spatial-temporal modeling, Video Mobile-Former significantly improves the video recognition performance of alternative lightweight baselines, and outperforms other efficient CNN-based models at the low FLOP regime from 500M to 6G total FLOPs on various video recognition tasks. It is worth noting that Video Mobile-Former is the first Transformer-based video model which constrains the computational budget within 1G FLOPs.