 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge$\text{VG}^2$GT: Voxel-Gaussian Splatting Visual Geometry Grounded Transformer
Jun 01, 2026Gaussian splatting has shown strong potential for 3D reconstruction and novel view synthesis. However, most existing methods require accurate camera parameters and per-scene optimization, while feed-forward methods with pixel-aligned Gaussian primitives often suffer from artifacts and non-uniform primitives. In this paper, we propose $\text{VG}^2$GT, a Voxel-Gaussian Splatting Visual Geometry-Grounded Transformer. $\text{VG}^2$GT leverages a frozen pretrained visual foundation model (VFM), incorporates a multi-scale differentiable voxel module to enhance geometric understanding, and directly splits and regresses Gaussian primitive parameters from voxel features. During training, depth maps are supervised through stochastic solid volume rendering, enabling geometrically accurate Gaussian scene reconstruction while keeping the visual foundation model fully frozen. This design enables $\text{VG}^2$GT to be seamlessly plugged into any patch-feature-based VFM, while substantially reducing the required training cost. $\text{VG}^2$GT outperforms current state-of-the-art methods on widely used DTU, Replica, TAT, and ScanNet datasets.
ECHO: Towards Emotionally Appropriate and Contextually Aware Interactive Head Generation
Mar 18, 2026In natural face-to-face interaction, participants seamlessly alternate between speaking and listening, producing facial behaviors (FBs) that are finely informed by long-range context and naturally exhibit contextual appropriateness and emotional rationality. Interactive Head Generation (IHG) aims to synthesize lifelike avatar head video emulating such capabilities. Existing IHG methods typically condition on dual-track signals (i.e., human user's behaviors and pre-defined audio for avatar) within a short temporal window, jointly driving generation of avatar's audio-aligned lip articulation and non-verbal FBs. However, two main challenges persist in these methods: (i) the reliance on short-clip behavioral cues without long-range contextual modeling leads them to produce facial behaviors lacking contextual appropriateness; and (ii) the entangled, role-agnostic fusion of dual-track signals empirically introduces cross-signal interference, potentially compromising lip-region synchronization during speaking. To this end, we propose ECHO, a novel IHG framework comprising two key components: a Long-range Contextual Understanding (LCU) component that facilitates contextual understanding of both behavior-grounded dynamics and linguistic-driven affective semantics to promote contextual appropriateness and emotional rationality of synthesized avatar FBs; and a block-wise Spatial-aware Decoupled Cross-attention Modulation (SDCM) module, that preserves self-audio-driven lip articulation while adaptively integrating user contextual behavioral cues for non-lip facial regions, complemented by our designed two-stage training paradigm, to jointly enhance lip synchronization and visual fidelity. Extensive experiments demonstrate the effectiveness of proposed components and ECHO's superior IHG performance.
OISMA: On-the-fly In-memory Stochastic Multiplication Architecture for Matrix-Multiplication Workloads
Aug 12, 2025Artificial Intelligence models are currently driven by a significant up-scaling of their complexity, with massive matrix multiplication workloads representing the major computational bottleneck. In-memory computing architectures are proposed to avoid the Von Neumann bottleneck. However, both digital/binary-based and analogue in-memory computing architectures suffer from various limitations, which significantly degrade the performance and energy efficiency gains. This work proposes OISMA, a novel in-memory computing architecture that utilizes the computational simplicity of a quasi-stochastic computing domain (Bent-Pyramid system), while keeping the same efficiency, scalability, and productivity of digital memories. OISMA converts normal memory read operations into in-situ stochastic multiplication operations with a negligible cost. An accumulation periphery then accumulates the output multiplication bitstreams, achieving the matrix multiplication functionality. Extensive matrix multiplication benchmarking was conducted to analyze the accuracy of the Bent-Pyramid system, using matrix dimensions ranging from 4x4 to 512x512. The accuracy results show a significant decrease in the average relative Frobenius error, from 9.42% (for 4x4) to 1.81% (for 512x512), compared to 64-bit double precision floating-point format. A 1T1R OISMA array of 4 KB capacity was implemented using a commercial 180nm technology node and in-house RRAM technology. At 50 MHz, OISMA achieves 0.891 TOPS/W and 3.98 GOPS/mm2 for energy and area efficiency, respectively, occupying an effective computing area of 0.804241 mm2. Scaling OISMA from 180nm to 22nm technology shows a significant improvement of two orders of magnitude in energy efficiency and one order of magnitude in area efficiency, compared to dense matrix multiplication in-memory computing architectures.
LLIA -- Enabling Low-Latency Interactive Avatars: Real-Time Audio-Driven Portrait Video Generation with Diffusion Models
Jun 06, 2025Diffusion-based models have gained wide adoption in the virtual human generation due to their outstanding expressiveness. However, their substantial computational requirements have constrained their deployment in real-time interactive avatar applications, where stringent speed, latency, and duration requirements are paramount. We present a novel audio-driven portrait video generation framework based on the diffusion model to address these challenges. Firstly, we propose robust variable-length video generation to reduce the minimum time required to generate the initial video clip or state transitions, which significantly enhances the user experience. Secondly, we propose a consistency model training strategy for Audio-Image-to-Video to ensure real-time performance, enabling a fast few-step generation. Model quantization and pipeline parallelism are further employed to accelerate the inference speed. To mitigate the stability loss incurred by the diffusion process and model quantization, we introduce a new inference strategy tailored for long-duration video generation. These methods ensure real-time performance and low latency while maintaining high-fidelity output. Thirdly, we incorporate class labels as a conditional input to seamlessly switch between speaking, listening, and idle states. Lastly, we design a novel mechanism for fine-grained facial expression control to exploit our model's inherent capacity. Extensive experiments demonstrate that our approach achieves low-latency, fluid, and authentic two-way communication. On an NVIDIA RTX 4090D, our model achieves a maximum of 78 FPS at a resolution of 384x384 and 45 FPS at a resolution of 512x512, with an initial video generation latency of 140 ms and 215 ms, respectively.
An Energy-efficient Capacitive-Memristive Content Addressable Memory
Jan 17, 2024



Content addressable memory is popular in the field of intelligent computing systems with its searching nature. Emerging CAMs show a promising increase in pixel density and a decrease in power consumption than pure CMOS solutions. This article introduced an energy-efficient 3T1R1C TCAM cooperating with capacitor dividers and RRAM devices. The RRAM as a storage element also acts as a switch to the capacitor divider while searching for content. CAM cells benefit from working parallel in an array structure. We implemented a 64 x 64 array and digital controllers to perform with an internal built-in clock frequency of 875MHz. Both data searches and reads take 3x clock cycles. Its worst average energy for data match is reported to be 1.71 fJ/bit-search and the worst average energy for data miss is found with 4.69 fJ/bit-search. The prototype is simulated and fabricated in 0.18 um technology with in-lab RRAM post-processing. Such memory explores the charge domain searching mechanism and can be applied to data centers that are power-hungry.
A High-fidelity, Machine-learning Enhanced Queueing Network Simulation Model for Hospital Ultrasound Operations
Apr 12, 2021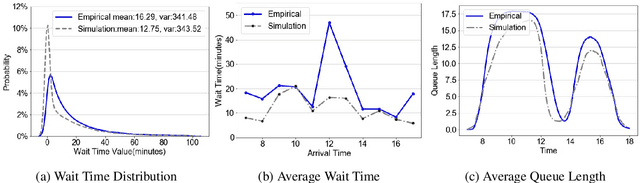

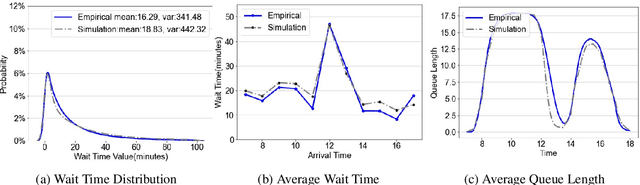

We collaborate with a large teaching hospital in Shenzhen, China and build a high-fidelity simulation model for its ultrasound center to predict key performance metrics, including the distributions of queue length, waiting time and sojourn time, with high accuracy. The key challenge to build an accurate simulation model is to understanding the complicated patient routing at the ultrasound center. To address the issue, we propose a novel two-level routing component to the queueing network model. We apply machine learning tools to calibrate the key components of the queueing model from data with enhanced accuracy.
2nd Place Solution to ECCV 2020 VIPriors Object Detection Challenge
Jul 17, 2020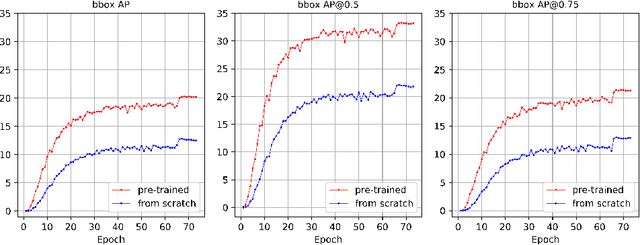
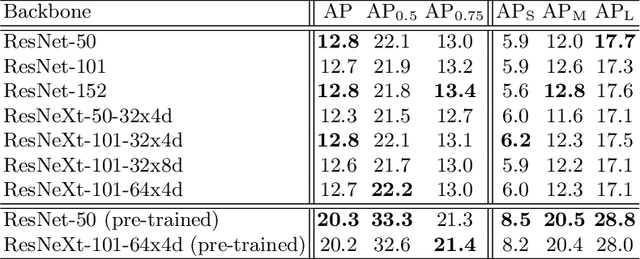


In this report, we descibe our approach to the ECCV 2020 VIPriors Object Detection Challenge which took place from March to July in 2020. We show that by using state-of-the-art data augmentation strategies, model designs, and post-processing ensemble methods, it is possible to overcome the difficulty of data shortage and obtain competitive results. Notably, our overall detection system achieves 36.6$\%$ AP on the COCO 2017 validation set using only 10K training images without any pre-training or transfer learning weights ranking us 2nd place in the challenge.