 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFederated Learning Enables Big Data for Rare Cancer Boundary Detection
Apr 25, 2022Although machine learning (ML) has shown promise in numerous domains, there are concerns about generalizability to out-of-sample data. This is currently addressed by centrally sharing ample, and importantly diverse, data from multiple sites. However, such centralization is challenging to scale (or even not feasible) due to various limitations. Federated ML (FL) provides an alternative to train accurate and generalizable ML models, by only sharing numerical model updates. Here we present findings from the largest FL study to-date, involving data from 71 healthcare institutions across 6 continents, to generate an automatic tumor boundary detector for the rare disease of glioblastoma, utilizing the largest dataset of such patients ever used in the literature (25,256 MRI scans from 6,314 patients). We demonstrate a 33% improvement over a publicly trained model to delineate the surgically targetable tumor, and 23% improvement over the tumor's entire extent. We anticipate our study to: 1) enable more studies in healthcare informed by large and diverse data, ensuring meaningful results for rare diseases and underrepresented populations, 2) facilitate further quantitative analyses for glioblastoma via performance optimization of our consensus model for eventual public release, and 3) demonstrate the effectiveness of FL at such scale and task complexity as a paradigm shift for multi-site collaborations, alleviating the need for data sharing.
Efficient 8-Bit Quantization of Transformer Neural Machine Language Translation Model
Jun 07, 2019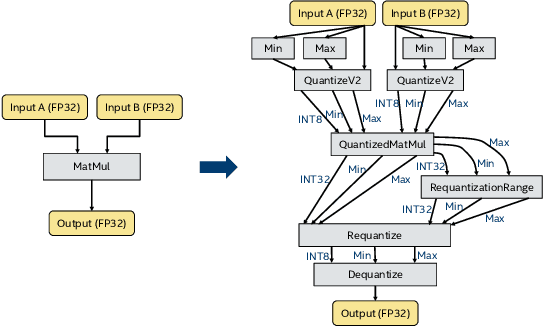
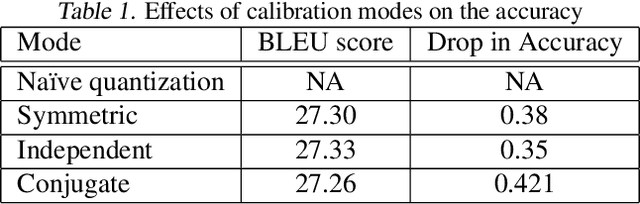
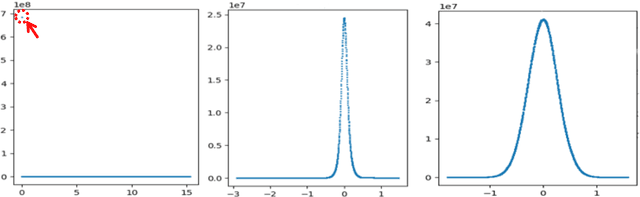
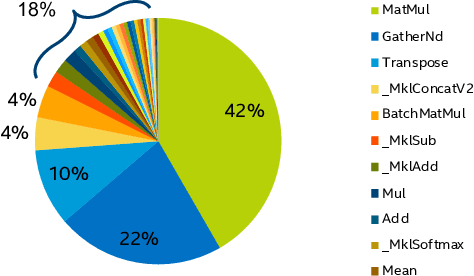
In this work, we quantize a trained Transformer machine language translation model leveraging INT8/VNNI instructions in the latest Intel$^\circledR$ Xeon$^\circledR$ Cascade Lake processors to improve inference performance while maintaining less than 0.5$\%$ drop in accuracy. To the best of our knowledge, this is the first attempt in the industry to quantize the Transformer model. This has high impact as it clearly demonstrates the various complexities of quantizing the language translation model. We present novel quantization techniques directly in TensorFlow to opportunistically replace 32-bit floating point (FP32) computations with 8-bit integers (INT8) and transform the FP32 computational graph. We also present a bin-packing parallel batching technique to maximize CPU utilization. Overall, our optimizations with INT8/VNNI deliver 1.5X improvement over the best FP32 performance. Furthermore, it reveals the opportunities and challenges to boost performance of quantized deep learning inference and establishes best practices to run inference with high efficiency on Intel CPUs.
Towards Understanding End-of-trip Instructions in a Taxi Ride Scenario
Jul 11, 2018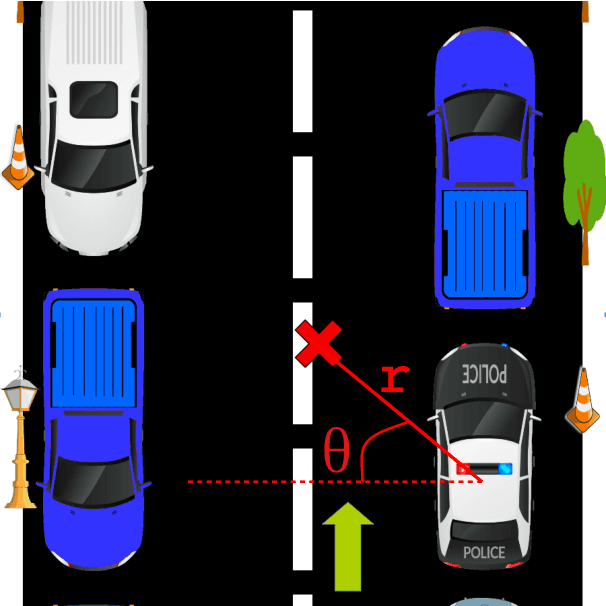

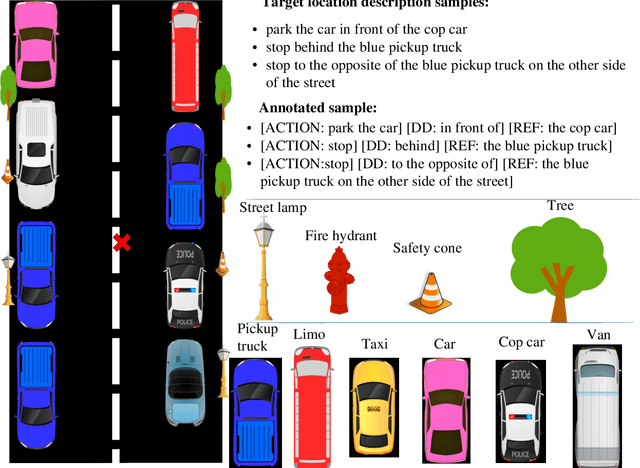
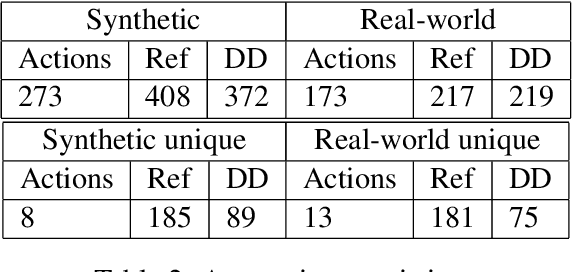
We introduce a dataset containing human-authored descriptions of target locations in an "end-of-trip in a taxi ride" scenario. We describe our data collection method and a novel annotation scheme that supports understanding of such descriptions of target locations. Our dataset contains target location descriptions for both synthetic and real-world images as well as visual annotations (ground truth labels, dimensions of vehicles and objects, coordinates of the target location,distance and direction of the target location from vehicles and objects) that can be used in various visual and language tasks. We also perform a pilot experiment on how the corpus could be applied to visual reference resolution in this domain.