 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmerging Convolutions for Generative Normalizing Flows
Feb 20, 2019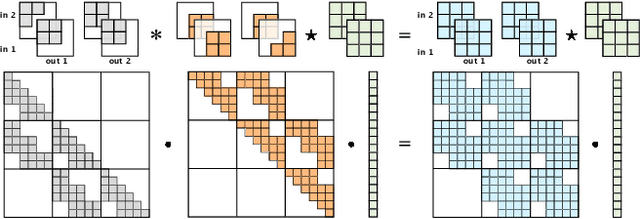

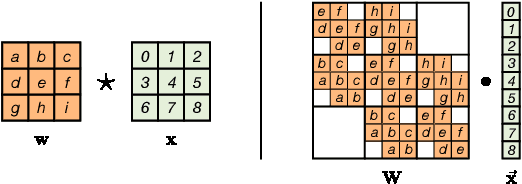
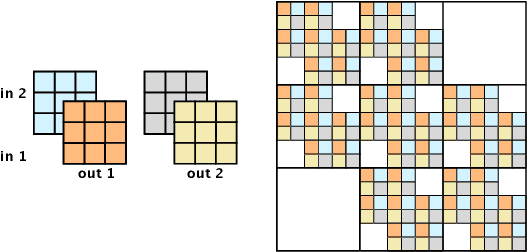
Generative flows are attractive because they admit exact likelihood optimization and efficient image synthesis. Recently, Kingma & Dhariwal (2018) demonstrated with Glow that generative flows are capable of generating high quality images. We generalize the 1 x 1 convolutions proposed in Glow to invertible d x d convolutions, which are more flexible since they operate on both channel and spatial axes. We propose two methods to produce invertible convolutions that have receptive fields identical to standard convolutions: Emerging convolutions are obtained by chaining specific autoregressive convolutions, and periodic convolutions are decoupled in the frequency domain. Our experiments show that the flexibility of d x d convolutions significantly improves the performance of generative flow models on galaxy images, CIFAR10 and ImageNet.
Gauge Equivariant Convolutional Networks and the Icosahedral CNN
Feb 11, 2019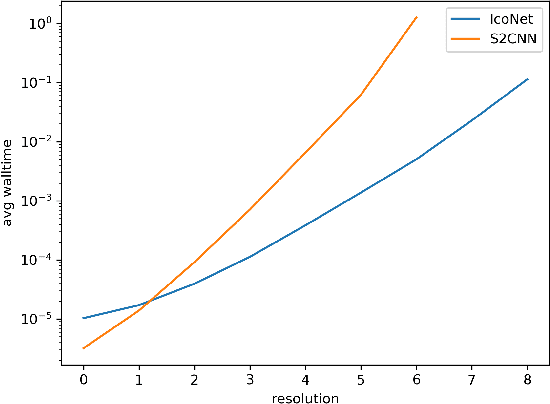
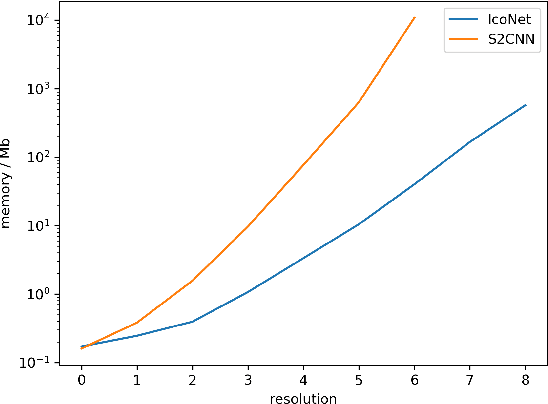
The idea of equivariance to symmetry transformations provides one of the first theoretically grounded principles for neural network architecture design. Equivariant networks have shown excellent performance and data efficiency on vision and medical imaging problems that exhibit symmetries. Here we show how this principle can be extended beyond global symmetries to local gauge transformations, thereby enabling the development of equivariant convolutional networks on general manifolds. We implement gauge equivariant CNNs for signals defined on the icosahedron, which provides a reasonable approximation of spherical signals. By choosing to work with this very regular manifold, we are able to implement the gauge equivariant convolution using a single conv2d call, making it a highly scalable and practical alternative to Spherical CNNs. We evaluate the Icosahedral CNN on omnidirectional image segmentation and climate pattern segmentation, and find that it outperforms previous methods.
Combinatorial Bayesian Optimization using Graph Representations
Feb 01, 2019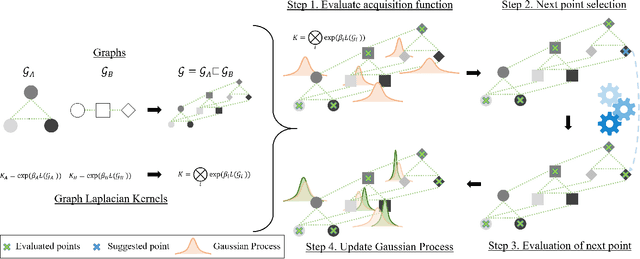
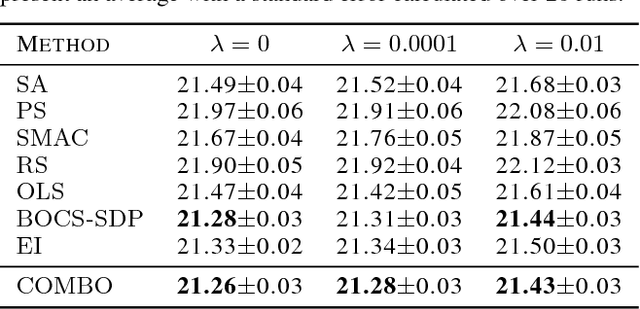
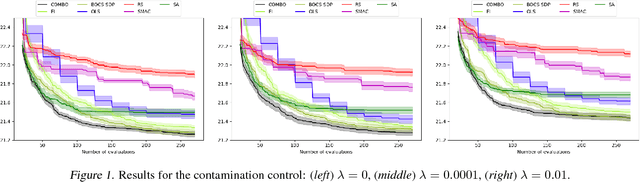
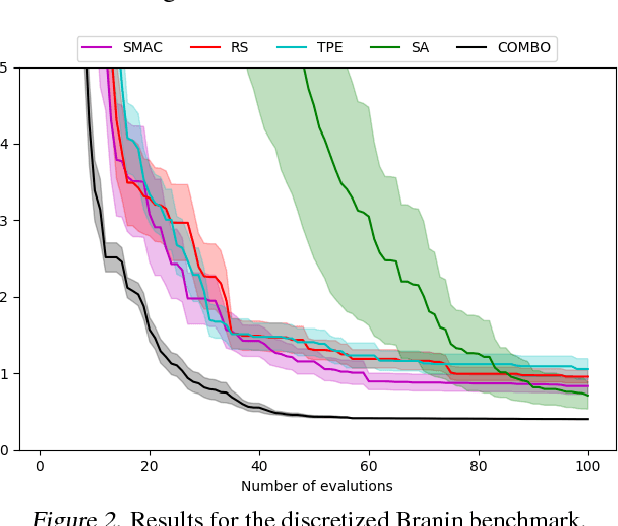
This paper focuses on Bayesian Optimization - typically considered with continuous inputs - for discrete search input spaces, including integer, categorical or graph structured input variables. In Gaussian process-based Bayesian Optimization a problem arises, as it is not straightforward to define a proper kernel on discrete input structures, where no natural notion of smoothness or similarity could be provided. We propose COMBO, a method that represents values of discrete variables as vertices of a graph and then use the diffusion kernel on that graph. As the graph size explodes with the number of categorical variables and categories, we propose the graph Cartesian product to decompose the graph into smaller sub-graphs, enabling kernel computation in linear time with respect to the number of input variables. Moreover, in our formulation we learn a scale parameter per subgraph. In empirical studies on four discrete optimization problems we demonstrate that our method is on par or outperforms the state-of-the-art in discrete Bayesian optimization.
Adversarial Variational Inference and Learning in Markov Random Fields
Jan 24, 2019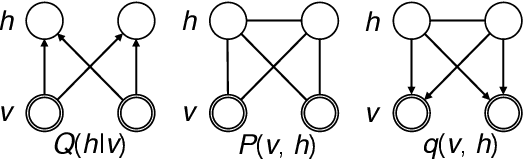
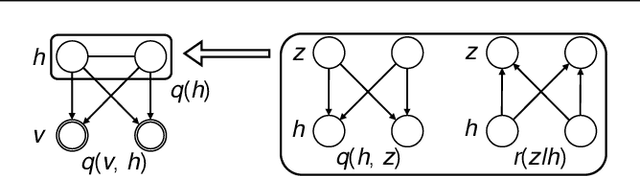

Markov random fields (MRFs) find applications in a variety of machine learning areas, while the inference and learning of such models are challenging in general. In this paper, we propose the Adversarial Variational Inference and Learning (AVIL) algorithm to solve the problems with a minimal assumption about the model structure of an MRF. AVIL employs two variational distributions to approximately infer the latent variables and estimate the partition function, respectively. The variational distributions, which are parameterized as neural networks, provide an estimate of the negative log likelihood of the MRF. On one hand, the estimate is in an intuitive form of approximate contrastive free energy. On the other hand, the estimate is a minimax optimization problem, which is solved by stochastic gradient descent in an alternating manner. We apply AVIL to various undirected generative models in a fully black-box manner and obtain better results than existing competitors on several real datasets.
Graph Refinement based Tree Extraction using Mean-Field Networks and Graph Neural Networks
Nov 21, 2018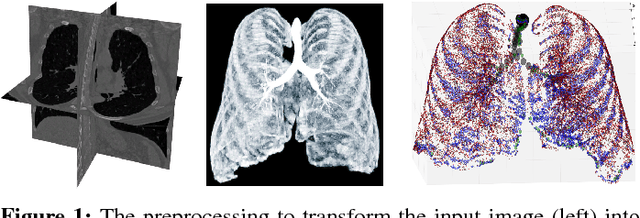
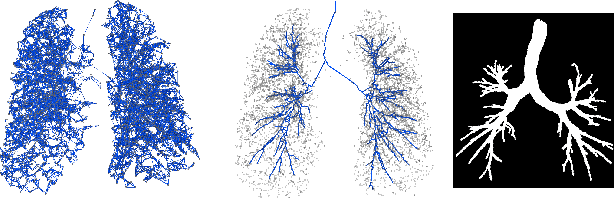
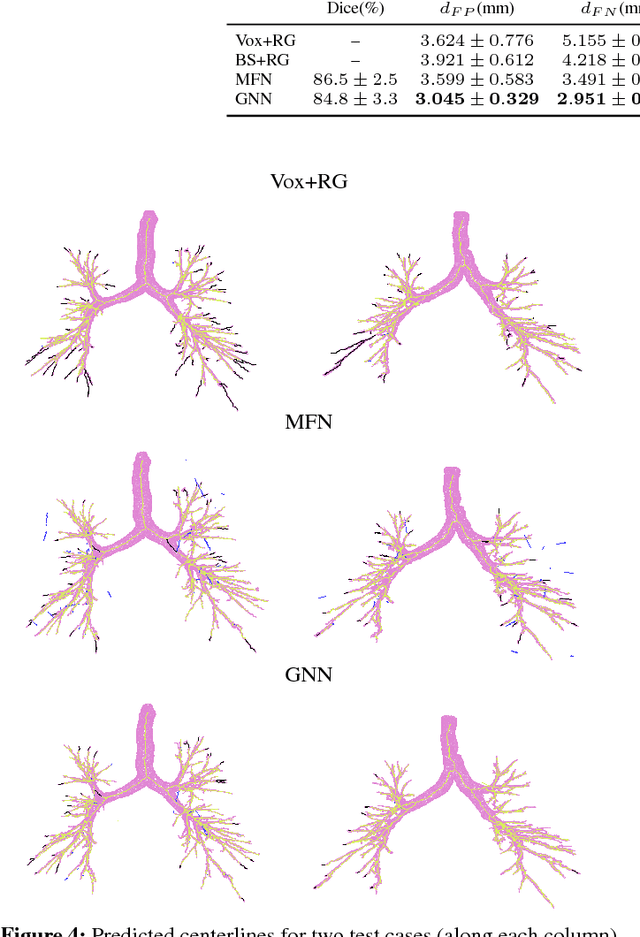
Graph refinement, or the task of obtaining subgraphs of interest from over-complete graphs, can have many varied applications. In this work, we extract tree structures from image data by, first deriving a graph-based representation of the volumetric data and then, posing tree extraction as a graph refinement task. We present two methods to perform graph refinement. First, we use mean-field approximation (MFA) to approximate the posterior density over the subgraphs from which the optimal subgraph of interest can be estimated. Mean field networks (MFNs) are used for inference based on the interpretation that iterations of MFA can be seen as feed-forward operations in a neural network. This allows us to learn the model parameters using gradient descent. Second, we present a supervised learning approach using graph neural networks (GNNs) which can be seen as generalisations of MFNs. Subgraphs are obtained by jointly training a GNN based encoder-decoder pair, wherein the encoder learns useful edge embeddings from which the edge probabilities are predicted using a simple decoder. We discuss connections between the two classes of methods and compare them for the task of extracting airways from 3D, low-dose, chest CT data. We show that both the MFN and GNN models show significant improvement when compared to a baseline method, that is similar to a top performing method in the EXACT'09 Challenge, in detecting more branches.
3D Steerable CNNs: Learning Rotationally Equivariant Features in Volumetric Data
Oct 27, 2018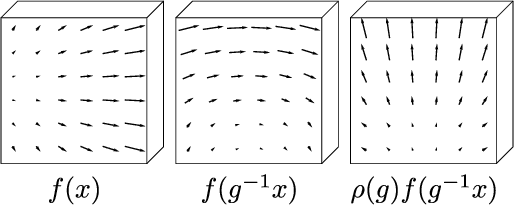

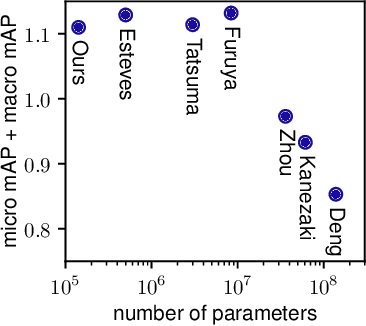
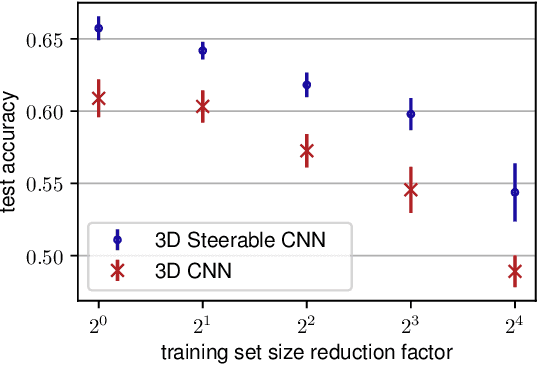
We present a convolutional network that is equivariant to rigid body motions. The model uses scalar-, vector-, and tensor fields over 3D Euclidean space to represent data, and equivariant convolutions to map between such representations. These SE(3)-equivariant convolutions utilize kernels which are parameterized as a linear combination of a complete steerable kernel basis, which is derived analytically in this paper. We prove that equivariant convolutions are the most general equivariant linear maps between fields over R^3. Our experimental results confirm the effectiveness of 3D Steerable CNNs for the problem of amino acid propensity prediction and protein structure classification, both of which have inherent SE(3) symmetry.
The Deep Weight Prior. Modeling a prior distribution for CNNs using generative models
Oct 16, 2018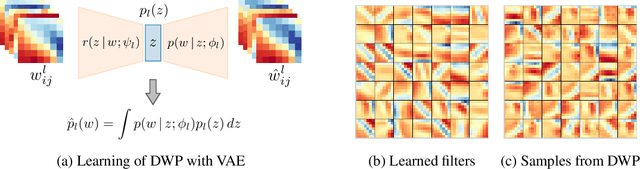
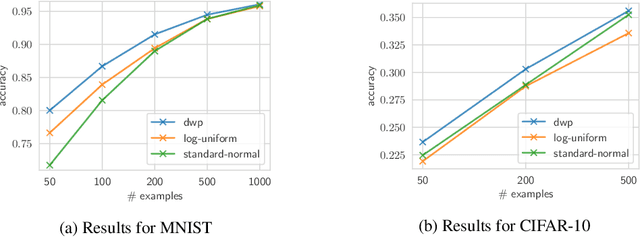

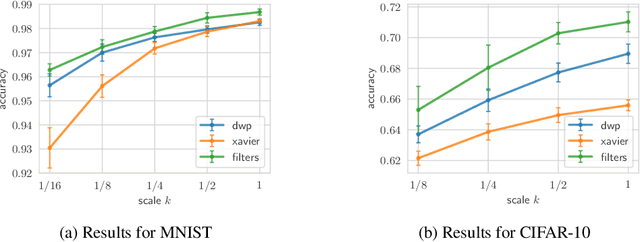
Bayesian inference is known to provide a general framework for incorporating prior knowledge or specific properties into machine learning models via carefully choosing a prior distribution. In this work, we propose a new type of prior distributions for convolutional neural networks, deep weight prior, that in contrast to previously published techniques, favors empirically estimated structure of convolutional filters e.g., spatial correlations of weights. We define deep weight prior as an implicit distribution and propose a method for variational inference with such type of implicit priors. In experiments, we show that deep weight priors can improve the performance of Bayesian neural networks on several problems when training data is limited. Also, we found that initialization of weights of conventional networks with samples from deep weight prior leads to faster training.
Predictive Uncertainty through Quantization
Oct 12, 2018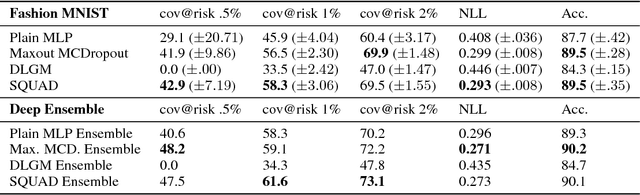
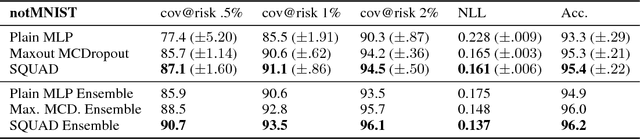
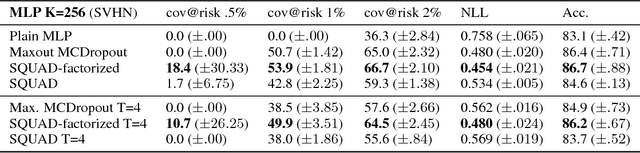
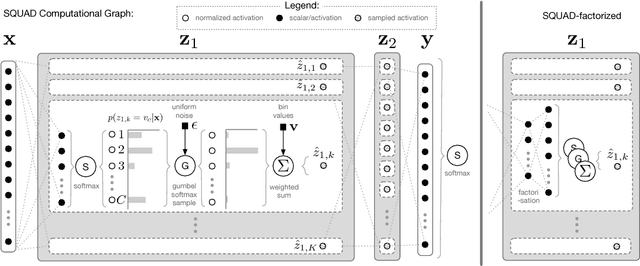
High-risk domains require reliable confidence estimates from predictive models. Deep latent variable models provide these, but suffer from the rigid variational distributions used for tractable inference, which err on the side of overconfidence. We propose Stochastic Quantized Activation Distributions (SQUAD), which imposes a flexible yet tractable distribution over discretized latent variables. The proposed method is scalable, self-normalizing and sample efficient. We demonstrate that the model fully utilizes the flexible distribution, learns interesting non-linearities, and provides predictive uncertainty of competitive quality.
Relaxed Quantization for Discretized Neural Networks
Oct 03, 2018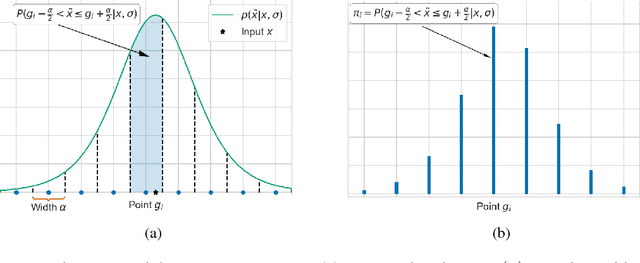
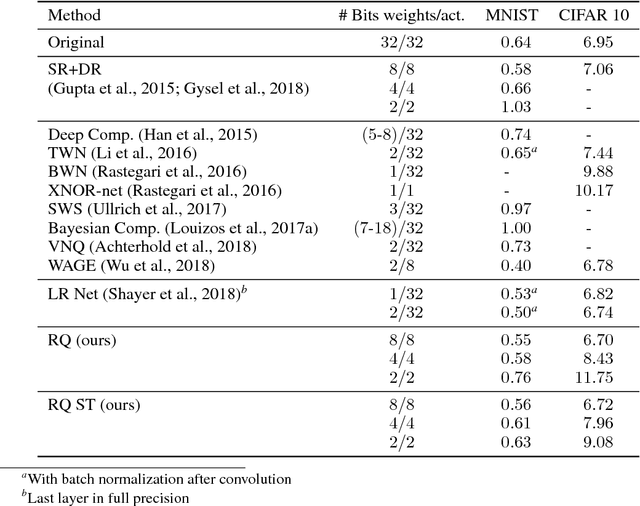
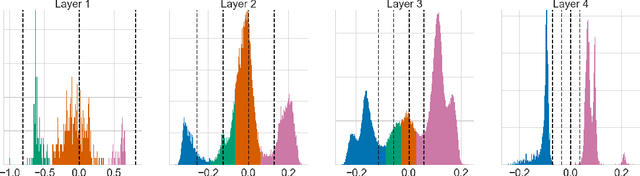
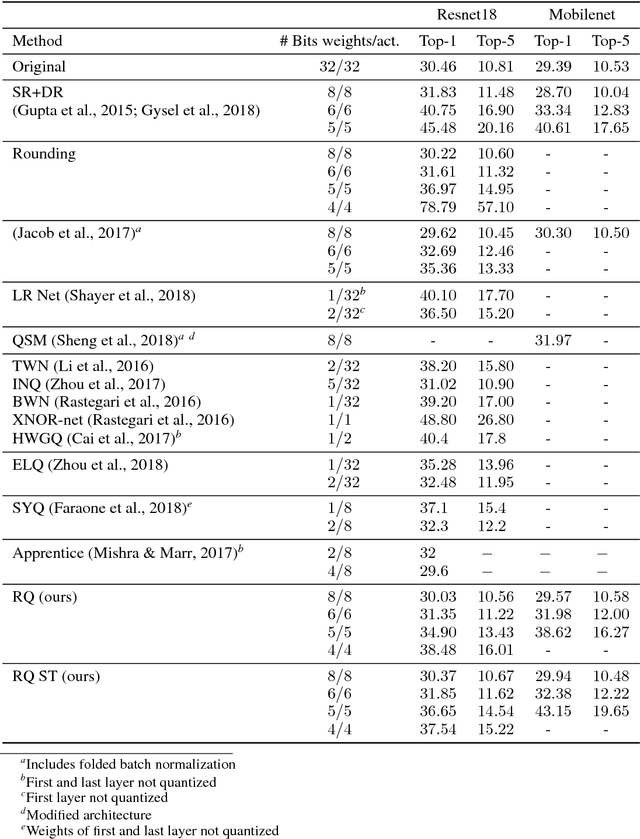
Neural network quantization has become an important research area due to its great impact on deployment of large models on resource constrained devices. In order to train networks that can be effectively discretized without loss of performance, we introduce a differentiable quantization procedure. Differentiability can be achieved by transforming continuous distributions over the weights and activations of the network to categorical distributions over the quantization grid. These are subsequently relaxed to continuous surrogates that can allow for efficient gradient-based optimization. We further show that stochastic rounding can be seen as a special case of the proposed approach and that under this formulation the quantization grid itself can also be optimized with gradient descent. We experimentally validate the performance of our method on MNIST, CIFAR 10 and Imagenet classification.
Sinkhorn AutoEncoders
Oct 03, 2018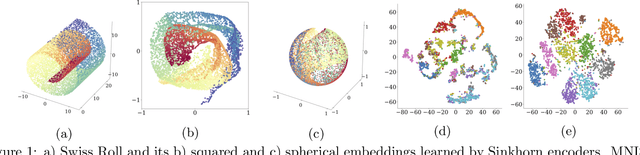
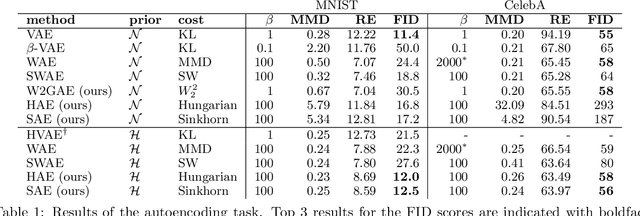

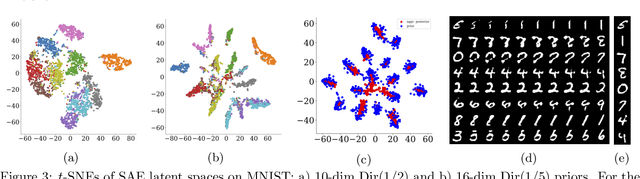
Optimal Transport offers an alternative to maximum likelihood for learning generative autoencoding models. We show how this principle dictates the minimization of the Wasserstein distance between the encoder aggregated posterior and the prior, plus a reconstruction error. We prove that in the non-parametric limit the autoencoder generates the data distribution if and only if the two distributions match exactly, and that the optimum can be obtained by deterministic autoencoders. We then introduce the Sinkhorn AutoEncoder (SAE), which casts the problem into Optimal Transport on the latent space. The resulting Wasserstein distance is minimized by backpropagating through the Sinkhorn algorithm. SAE models the aggregated posterior as an implicit distribution and therefore does not need a reparameterization trick for gradients estimation. Moreover, it requires virtually no adaptation to different prior distributions. We demonstrate its flexibility by considering models with hyperspherical and Dirichlet priors, as well as a simple case of probabilistic programming. SAE matches or outperforms other autoencoding models in visual quality and FID scores.