 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTechniques for Peak Memory Reduction for LoRA Fine-tuning of LLMs on Edge Devices
Jun 17, 2026Fine-tuning of Large Language Models (LLMs) using Low-Rank Adaptation (LoRA) on an end-user's data offers personalized experiences while keeping data private, but faces severe memory constraints on consumer hardware. Peak memory during fine-tuning often exceeds device limits, especially for models with billions of parameters and long-context training data. This paper introduces a suite of complementary techniques to reduce memory footprint without sacrificing model quality: (1) base model quantization with on-the-fly dequantization, (2) memory-efficient checkpointing combining selective activation caching and disk offloading, (3) softmax approximation using semantically relevant token subsets, and (4) logits masking. Experiments on Llama-3.2 3B and Qwen-2.5 3B demonstrate up to $26\times$ and $28\times$ reduction in peak memory, enabling fine-tuning on resource-constrained devices.
On Adaptivity in Zeroth-Order Optimization
May 05, 2026We investigate the effectiveness of adaptive zeroth-order (ZO) optimization for memory-constrained fine-tuning of large language models (LLMs). Contrary to prior claims, we show that adaptive ZO methods such as ZO-Adam offer no convergence advantage over well-tuned ZO-SGD, while incurring significant memory overhead. Our analysis reveals that in high dimensions, ZO gradients lack coordinate-wise heterogeneity, rendering adaptive mechanisms memory inefficient. Leveraging this insight, we propose MEAZO, a memory-efficient adaptive ZO optimizer that tracks only a single scalar for global step size adaptation. We support our method with theoretical convergence guarantees under standard assumptions. Experiments across multiple LLM families and tasks demonstrate that MEAZO matches ZO-Adam's performance with the memory footprint of ZO-SGD. Additional experiments on synthetic quadratic problems and LLM fine-tuning further demonstrate MEAZO's enhanced robustness to step size choices, particularly in grouped or block-structured optimization settings.
Hollowed Net for On-Device Personalization of Text-to-Image Diffusion Models
Nov 02, 2024Recent advancements in text-to-image diffusion models have enabled the personalization of these models to generate custom images from textual prompts. This paper presents an efficient LoRA-based personalization approach for on-device subject-driven generation, where pre-trained diffusion models are fine-tuned with user-specific data on resource-constrained devices. Our method, termed Hollowed Net, enhances memory efficiency during fine-tuning by modifying the architecture of a diffusion U-Net to temporarily remove a fraction of its deep layers, creating a hollowed structure. This approach directly addresses on-device memory constraints and substantially reduces GPU memory requirements for training, in contrast to previous methods that primarily focus on minimizing training steps and reducing the number of parameters to update. Additionally, the personalized Hollowed Net can be transferred back into the original U-Net, enabling inference without additional memory overhead. Quantitative and qualitative analyses demonstrate that our approach not only reduces training memory to levels as low as those required for inference but also maintains or improves personalization performance compared to existing methods.
Stable Diffusion-based Data Augmentation for Federated Learning with Non-IID Data
May 13, 2024



The proliferation of edge devices has brought Federated Learning (FL) to the forefront as a promising paradigm for decentralized and collaborative model training while preserving the privacy of clients' data. However, FL struggles with a significant performance reduction and poor convergence when confronted with Non-Independent and Identically Distributed (Non-IID) data distributions among participating clients. While previous efforts, such as client drift mitigation and advanced server-side model fusion techniques, have shown some success in addressing this challenge, they often overlook the root cause of the performance reduction - the absence of identical data accurately mirroring the global data distribution among clients. In this paper, we introduce Gen-FedSD, a novel approach that harnesses the powerful capability of state-of-the-art text-to-image foundation models to bridge the significant Non-IID performance gaps in FL. In Gen-FedSD, each client constructs textual prompts for each class label and leverages an off-the-shelf state-of-the-art pre-trained Stable Diffusion model to synthesize high-quality data samples. The generated synthetic data is tailored to each client's unique local data gaps and distribution disparities, effectively making the final augmented local data IID. Through extensive experimentation, we demonstrate that Gen-FedSD achieves state-of-the-art performance and significant communication cost savings across various datasets and Non-IID settings.
A Mutual Information Perspective on Federated Contrastive Learning
May 03, 2024



We investigate contrastive learning in the federated setting through the lens of SimCLR and multi-view mutual information maximization. In doing so, we uncover a connection between contrastive representation learning and user verification; by adding a user verification loss to each client's local SimCLR loss we recover a lower bound to the global multi-view mutual information. To accommodate for the case of when some labelled data are available at the clients, we extend our SimCLR variant to the federated semi-supervised setting. We see that a supervised SimCLR objective can be obtained with two changes: a) the contrastive loss is computed between datapoints that share the same label and b) we require an additional auxiliary head that predicts the correct labels from either of the two views. Along with the proposed SimCLR extensions, we also study how different sources of non-i.i.d.-ness can impact the performance of federated unsupervised learning through global mutual information maximization; we find that a global objective is beneficial for some sources of non-i.i.d.-ness but can be detrimental for others. We empirically evaluate our proposed extensions in various tasks to validate our claims and furthermore demonstrate that our proposed modifications generalize to other pretraining methods.
Hyperparameter Optimization through Neural Network Partitioning
Apr 28, 2023



Well-tuned hyperparameters are crucial for obtaining good generalization behavior in neural networks. They can enforce appropriate inductive biases, regularize the model and improve performance -- especially in the presence of limited data. In this work, we propose a simple and efficient way for optimizing hyperparameters inspired by the marginal likelihood, an optimization objective that requires no validation data. Our method partitions the training data and a neural network model into $K$ data shards and parameter partitions, respectively. Each partition is associated with and optimized only on specific data shards. Combining these partitions into subnetworks allows us to define the ``out-of-training-sample" loss of a subnetwork, i.e., the loss on data shards unseen by the subnetwork, as the objective for hyperparameter optimization. We demonstrate that we can apply this objective to optimize a variety of different hyperparameters in a single training run while being significantly computationally cheaper than alternative methods aiming to optimize the marginal likelihood for neural networks. Lastly, we also focus on optimizing hyperparameters in federated learning, where retraining and cross-validation are particularly challenging.
Quantization Robust Federated Learning for Efficient Inference on Heterogeneous Devices
Jun 22, 2022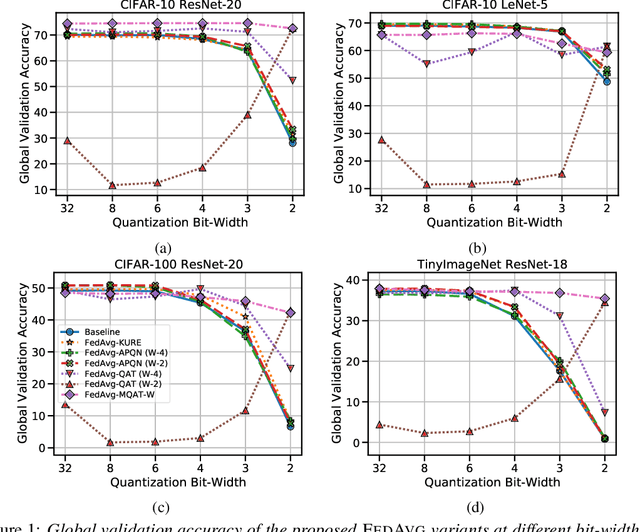
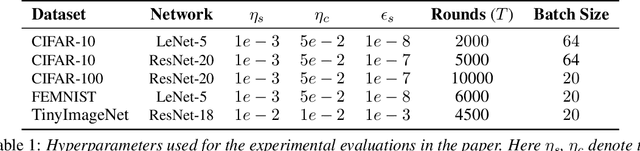
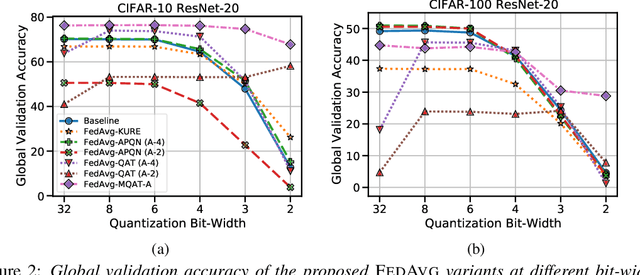
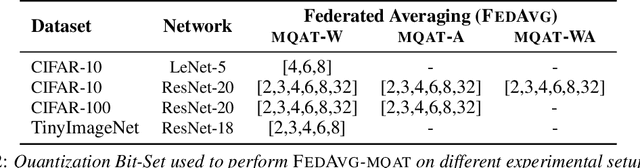
Federated Learning (FL) is a machine learning paradigm to distributively learn machine learning models from decentralized data that remains on-device. Despite the success of standard Federated optimization methods, such as Federated Averaging (FedAvg) in FL, the energy demands and hardware induced constraints for on-device learning have not been considered sufficiently in the literature. Specifically, an essential demand for on-device learning is to enable trained models to be quantized to various bit-widths based on the energy needs and heterogeneous hardware designs across the federation. In this work, we introduce multiple variants of federated averaging algorithm that train neural networks robust to quantization. Such networks can be quantized to various bit-widths with only limited reduction in full precision model accuracy. We perform extensive experiments on standard FL benchmarks to evaluate our proposed FedAvg variants for quantization robustness and provide a convergence analysis for our Quantization-Aware variants in FL. Our results demonstrate that integrating quantization robustness results in FL models that are significantly more robust to different bit-widths during quantized on-device inference.
An Expectation-Maximization Perspective on Federated Learning
Nov 19, 2021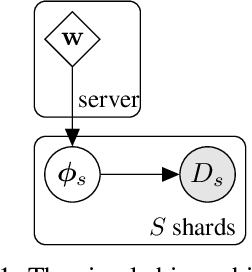
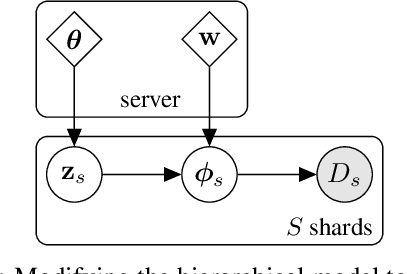

Federated learning describes the distributed training of models across multiple clients while keeping the data private on-device. In this work, we view the server-orchestrated federated learning process as a hierarchical latent variable model where the server provides the parameters of a prior distribution over the client-specific model parameters. We show that with simple Gaussian priors and a hard version of the well known Expectation-Maximization (EM) algorithm, learning in such a model corresponds to FedAvg, the most popular algorithm for the federated learning setting. This perspective on FedAvg unifies several recent works in the field and opens up the possibility for extensions through different choices for the hierarchical model. Based on this view, we further propose a variant of the hierarchical model that employs prior distributions to promote sparsity. By similarly using the hard-EM algorithm for learning, we obtain FedSparse, a procedure that can learn sparse neural networks in the federated learning setting. FedSparse reduces communication costs from client to server and vice-versa, as well as the computational costs for inference with the sparsified network - both of which are of great practical importance in federated learning.
DP-REC: Private & Communication-Efficient Federated Learning
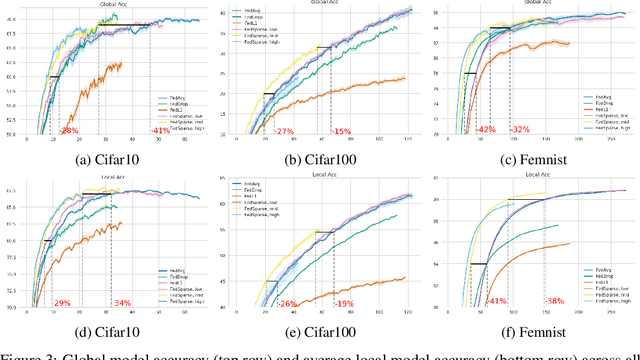
Nov 09, 2021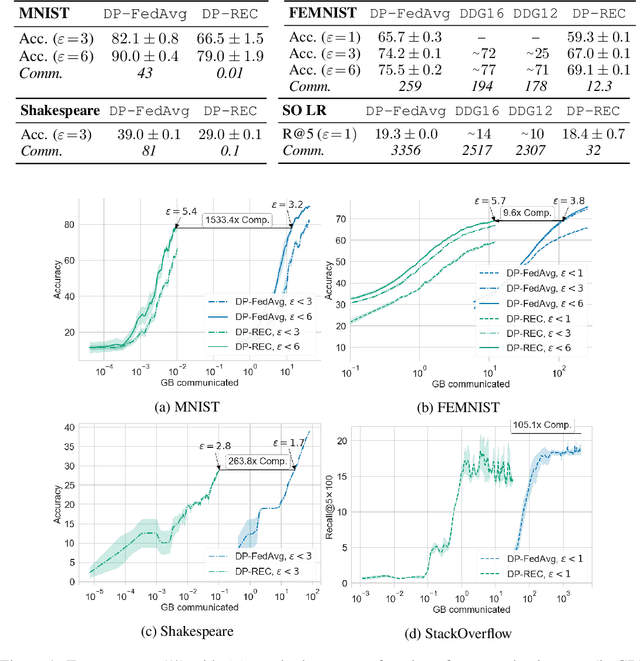
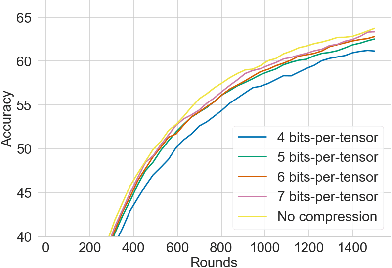
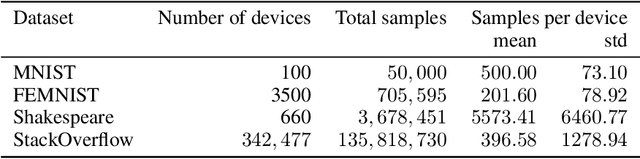
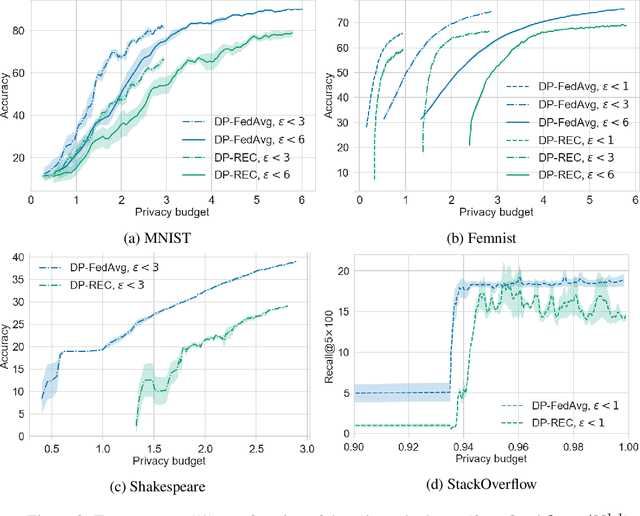
Privacy and communication efficiency are important challenges in federated training of neural networks, and combining them is still an open problem. In this work, we develop a method that unifies highly compressed communication and differential privacy (DP). We introduce a compression technique based on Relative Entropy Coding (REC) to the federated setting. With a minor modification to REC, we obtain a provably differentially private learning algorithm, DP-REC, and show how to compute its privacy guarantees. Our experiments demonstrate that DP-REC drastically reduces communication costs while providing privacy guarantees comparable to the state-of-the-art.
Federated Mixture of Experts
Jul 14, 2021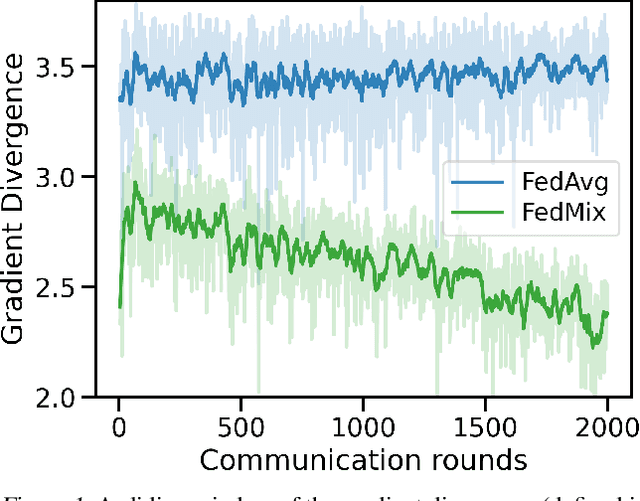

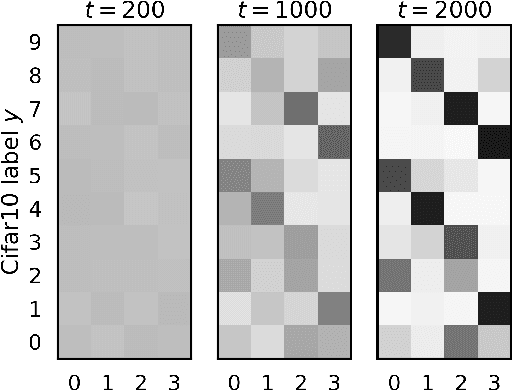
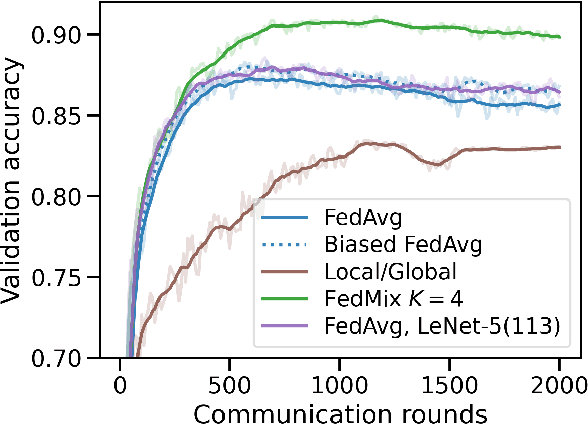
Federated learning (FL) has emerged as the predominant approach for collaborative training of neural network models across multiple users, without the need to gather the data at a central location. One of the important challenges in this setting is data heterogeneity, i.e. different users have different data characteristics. For this reason, training and using a single global model might be suboptimal when considering the performance of each of the individual user's data. In this work, we tackle this problem via Federated Mixture of Experts, FedMix, a framework that allows us to train an ensemble of specialized models. FedMix adaptively selects and trains a user-specific selection of the ensemble members. We show that users with similar data characteristics select the same members and therefore share statistical strength while mitigating the effect of non-i.i.d data. Empirically, we show through an extensive experimental evaluation that FedMix improves performance compared to using a single global model across a variety of different sources of non-i.i.d.-ness.