 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA trained humanoid robot can perform human-like crossmodal social attention conflict resolution
Nov 02, 2021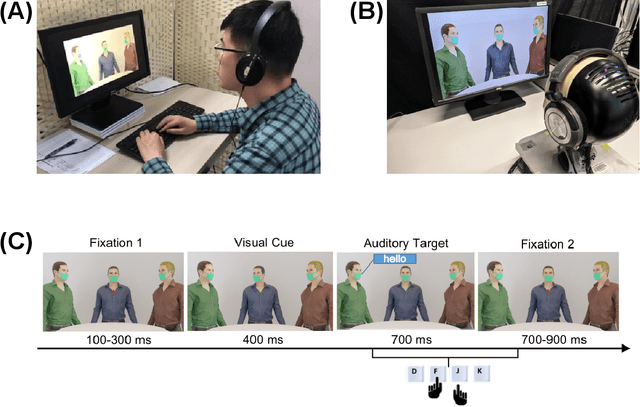
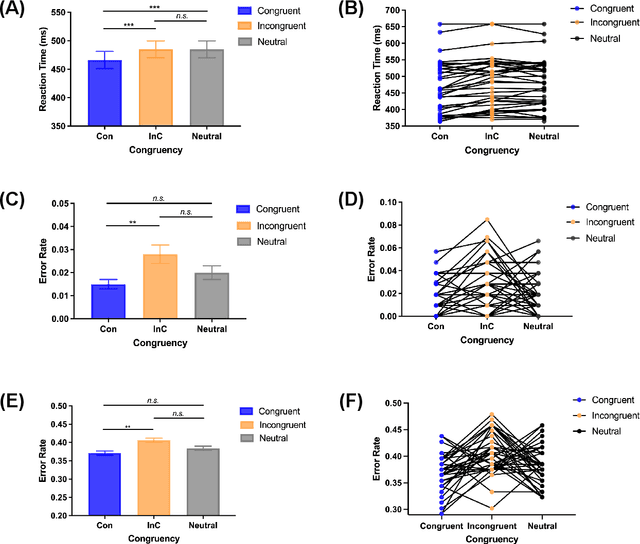
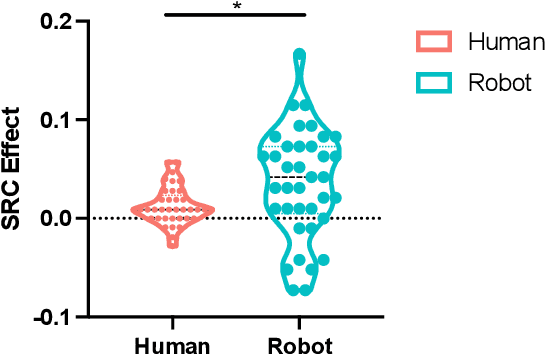

Due to the COVID-19 pandemic, robots could be seen as potential resources in tasks like helping people work remotely, sustaining social distancing, and improving mental or physical health. To enhance human-robot interaction, it is essential for robots to become more socialised, via processing multiple social cues in a complex real-world environment. Our study adopted a neurorobotic paradigm of gaze-triggered audio-visual crossmodal integration to make an iCub robot express human-like social attention responses. At first, a behavioural experiment was conducted on 37 human participants. To improve ecological validity, a round-table meeting scenario with three masked animated avatars was designed with the middle one capable of performing gaze shift, and the other two capable of generating sound. The gaze direction and the sound location are either congruent or incongruent. Masks were used to cover all facial visual cues other than the avatars' eyes. We observed that the avatar's gaze could trigger crossmodal social attention with better human performance in the audio-visual congruent condition than in the incongruent condition. Then, our computational model, GASP, was trained to implement social cue detection, audio-visual saliency prediction, and selective attention. After finishing the model training, the iCub robot was exposed to similar laboratory conditions as human participants, demonstrating that it can replicate similar attention responses as humans regarding the congruency and incongruency performance, while overall the human performance was still superior. Therefore, this interdisciplinary work provides new insights on mechanisms of crossmodal social attention and how it can be modelled in robots in a complex environment.
Robotic Occlusion Reasoning for Efficient Object Existence Prediction
Jul 28, 2021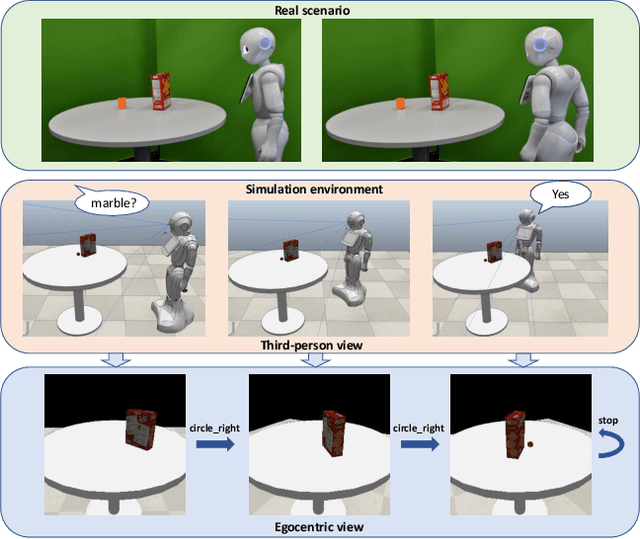
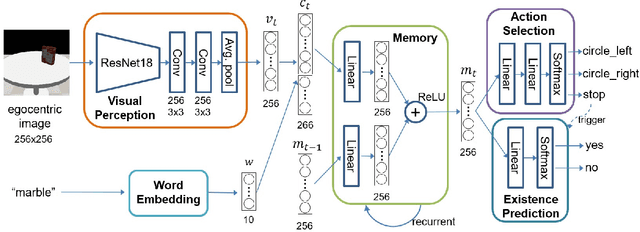
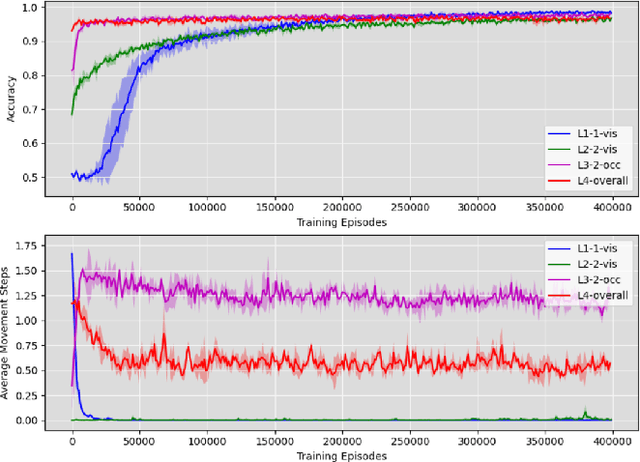
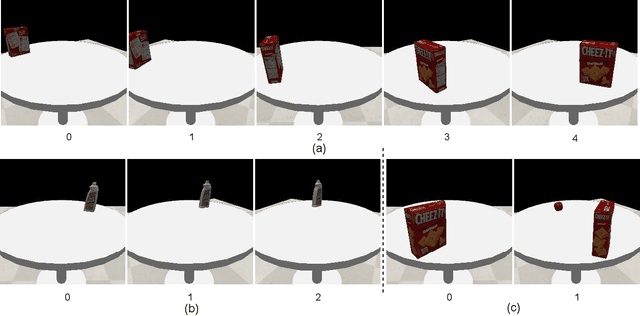
Reasoning about potential occlusions is essential for robots to efficiently predict whether an object exists in an environment. Though existing work shows that a robot with active perception can achieve various tasks, it is still unclear if occlusion reasoning can be achieved. To answer this question, we introduce the task of robotic object existence prediction: when being asked about an object, a robot needs to move as few steps as possible around a table with randomly placed objects to predict whether the queried object exists. To address this problem, we propose a novel recurrent neural network model that can be jointly trained with supervised and reinforcement learning methods using a curriculum training strategy. Experimental results show that 1) both active perception and occlusion reasoning are necessary to successfully achieve the task; 2) the proposed model demonstrates a good occlusion reasoning ability by achieving a similar prediction accuracy to an exhaustive exploration baseline while requiring only about $10\%$ of the baseline's number of movement steps on average; and 3) the model generalizes to novel object combinations with a moderate loss of accuracy.
Model Mediated Teleoperation with a Hand-Arm Exoskeleton in Long Time Delays Using Reinforcement Learning
Jul 01, 2021
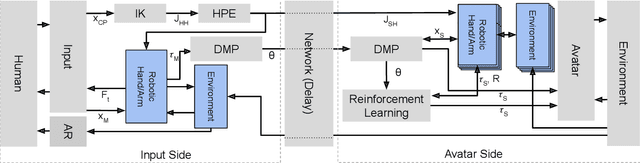
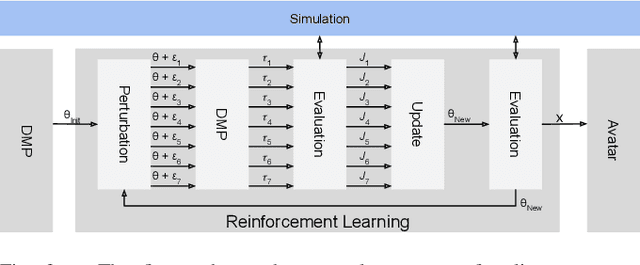
Telerobotic systems must adapt to new environmental conditions and deal with high uncertainty caused by long-time delays. As one of the best alternatives to human-level intelligence, Reinforcement Learning (RL) may offer a solution to cope with these issues. This paper proposes to integrate RL with the Model Mediated Teleoperation (MMT) concept. The teleoperator interacts with a simulated virtual environment, which provides instant feedback. Whereas feedback from the real environment is delayed, feedback from the model is instantaneous, leading to high transparency. The MMT is realized in combination with an intelligent system with two layers. The first layer utilizes Dynamic Movement Primitives (DMP) which accounts for certain changes in the avatar environment. And, the second layer addresses the problems caused by uncertainty in the model using RL methods. Augmented reality was also provided to fuse the avatar device and virtual environment models for the teleoperator. Implemented on DLR's Exodex Adam hand-arm haptic exoskeleton, the results show RL methods are able to find different solutions when changes are applied to the object position after the demonstration. The results also show DMPs to be effective at adapting to new conditions where there is no uncertainty involved.
Exercise with Social Robots: Companion or Coach?
Mar 24, 2021

In this paper, we investigate the roles that social robots can take in physical exercise with human partners. In related work, robots or virtual intelligent agents take the role of a coach or instructor whereas in other approaches they are used as motivational aids. These are two "paradigms", so to speak, within the small but growing area of robots for social exercise. We designed an online questionnaire to test whether the preferred role in which people want to see robots would be the companion or the coach. The questionnaire asks people to imagine working out with a robot with the help of three utilized questionnaires: (1) CART-Q which is used for judging coach-athlete relationships, (2) the mind perception questionnaire and (3) the System Usability Scale (SUS). We present the methodology, some preliminary results as well as our intended future work on personal robots for coaching.
Continual Learning from Synthetic Data for a Humanoid Exercise Robot
Feb 19, 2021

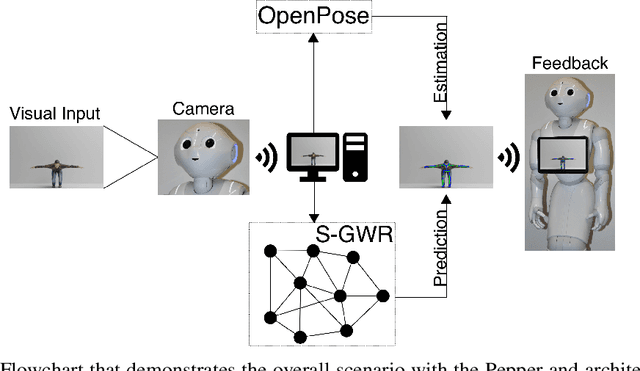
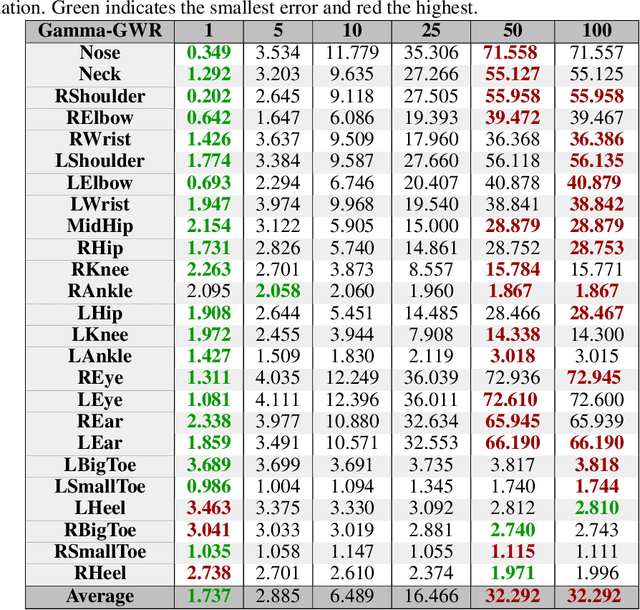
In order to detect and correct physical exercises, a Grow-When-Required Network (GWR) with recurrent connections, episodic memory and a novel subnode mechanism is developed in order to learn spatiotemporal relationships of body movements and poses. Once an exercise is performed, the information of pose and movement per frame is stored in the GWR. For every frame, the current pose and motion pair is compared against a predicted output of the GWR, allowing for feedback not only on the pose but also on the velocity of the motion. In a practical scenario, a physical exercise is performed by an expert like a physiotherapist and then used as a reference for a humanoid robot like Pepper to give feedback on a patient's execution of the same exercise. This approach, however, comes with two challenges. First, the distance from the humanoid robot and the position of the user in the camera's view of the humanoid robot have to be considered by the GWR as well, requiring a robustness against the user's positioning in the field of view of the humanoid robot. Second, since both the pose and motion are dependent on the body measurements of the original performer, the expert's exercise cannot be easily used as a reference. This paper tackles the first challenge by designing an architecture that allows for tolerances in translation and rotations regarding the center of the field of view. For the second challenge, we allow the GWR to grow online on incremental data. For evaluation, we created a novel exercise dataset with virtual avatars called the Virtual-Squat dataset. Overall, we claim that our novel architecture based on the GWR can use a learned exercise reference for different body variations through continual online learning, while preventing catastrophic forgetting, enabling for an engaging long-term human-robot interaction with a humanoid robot.
Hierarchical principles of embodied reinforcement learning: A review
Dec 18, 2020
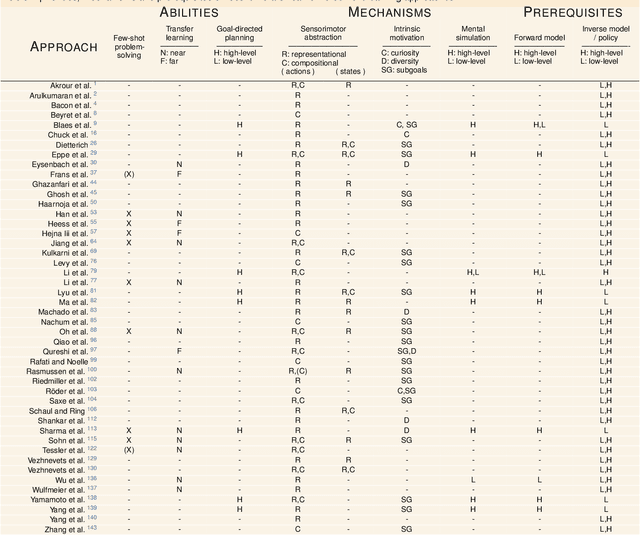
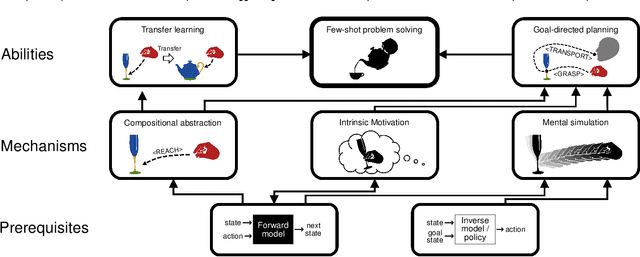
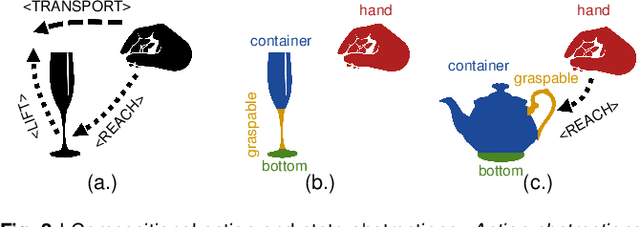
Cognitive Psychology and related disciplines have identified several critical mechanisms that enable intelligent biological agents to learn to solve complex problems. There exists pressing evidence that the cognitive mechanisms that enable problem-solving skills in these species build on hierarchical mental representations. Among the most promising computational approaches to provide comparable learning-based problem-solving abilities for artificial agents and robots is hierarchical reinforcement learning. However, so far the existing computational approaches have not been able to equip artificial agents with problem-solving abilities that are comparable to intelligent animals, including human and non-human primates, crows, or octopuses. Here, we first survey the literature in Cognitive Psychology, and related disciplines, and find that many important mental mechanisms involve compositional abstraction, curiosity, and forward models. We then relate these insights with contemporary hierarchical reinforcement learning methods, and identify the key machine intelligence approaches that realise these mechanisms. As our main result, we show that all important cognitive mechanisms have been implemented independently in isolated computational architectures, and there is simply a lack of approaches that integrate them appropriately. We expect our results to guide the development of more sophisticated cognitively inspired hierarchical methods, so that future artificial agents achieve a problem-solving performance on the level of intelligent animals.
Enhancing a Neurocognitive Shared Visuomotor Model for Object Identification, Localization, and Grasping With Learning From Auxiliary Tasks
Sep 26, 2020
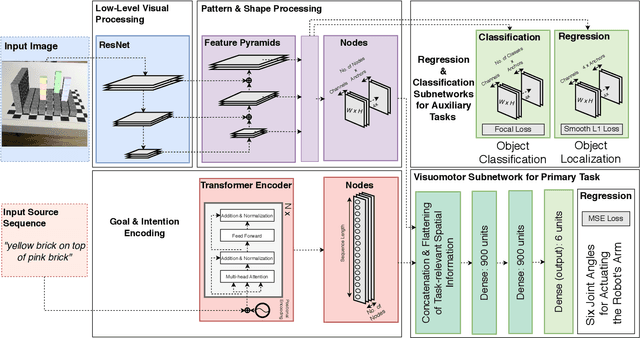


We present a follow-up study on our unified visuomotor neural model for the robotic tasks of identifying, localizing, and grasping a target object in a scene with multiple objects. Our Retinanet-based model enables end-to-end training of visuomotor abilities in a biologically inspired developmental approach. In our initial implementation, a neural model was able to grasp selected objects from a planar surface. We embodied the model on the NICO humanoid robot. In this follow-up study, we expand the task and the model to reaching for objects in a three-dimensional space with a novel dataset based on augmented reality and a simulation environment. We evaluate the influence of training with auxiliary tasks, i.e., if learning of the primary visuomotor task is supported by learning to classify and locate different objects. We show that the proposed visuomotor model can learn to reach for objects in a three-dimensional space. We analyze the results for biologically-plausible biases based on object locations or properties. We show that the primary visuomotor task can be successfully trained simultaneously with one of the two auxiliary tasks. This is enabled by a complex neurocognitive model with shared and task-specific components, similar to models found in biological systems.
Crossmodal Language Grounding in an Embodied Neurocognitive Model
Jun 24, 2020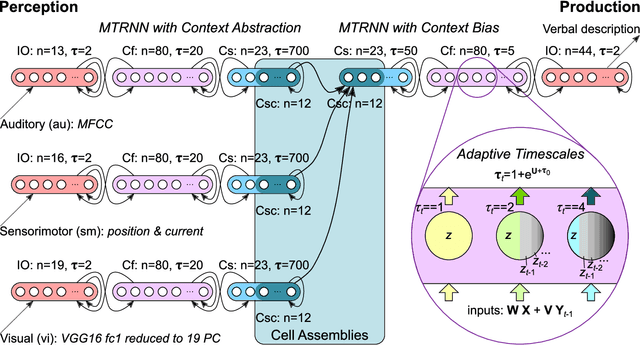

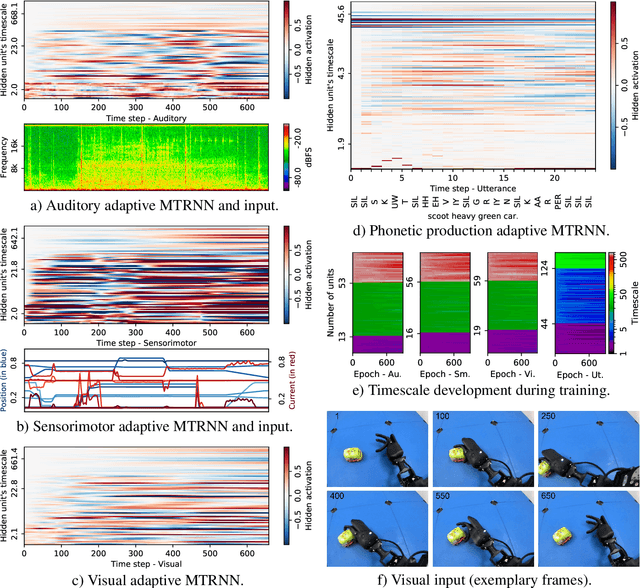
Human infants are able to acquire natural language seemingly easily at an early age. Their language learning seems to occur simultaneously with learning other cognitive functions as well as with playful interactions with the environment and caregivers. From a neuroscientific perspective, natural language is embodied, grounded in most, if not all, sensory and sensorimotor modalities, and acquired by means of crossmodal integration. However, characterising the underlying mechanisms in the brain is difficult and explaining the grounding of language in crossmodal perception and action remains challenging. In this paper, we present a neurocognitive model for language grounding which reflects bio-inspired mechanisms such as an implicit adaptation of timescales as well as end-to-end multimodal abstraction. It addresses developmental robotic interaction and extends its learning capabilities using larger-scale knowledge-based data. In our scenario, we utilise the humanoid robot NICO in obtaining the EMIL data collection, in which the cognitive robot interacts with objects in a children's playground environment while receiving linguistic labels from a caregiver. The model analysis shows that crossmodally integrated representations are sufficient for acquiring language merely from sensory input through interaction with objects in an environment. The representations self-organise hierarchically and embed temporal and spatial information through composition and decomposition. This model can also provide the basis for further crossmodal integration of perceptually grounded cognitive representations.
Explainable Goal-Driven Agents and Robots- A Comprehensive Review and New Framework
Apr 21, 2020
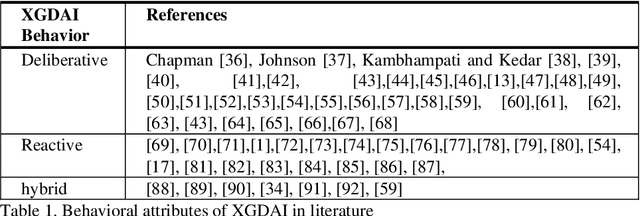
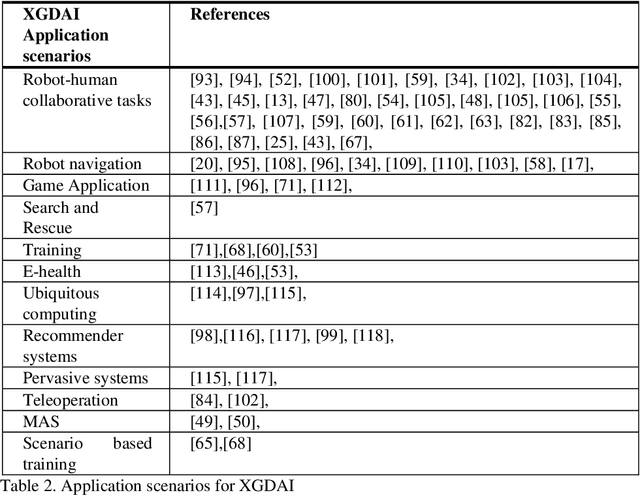
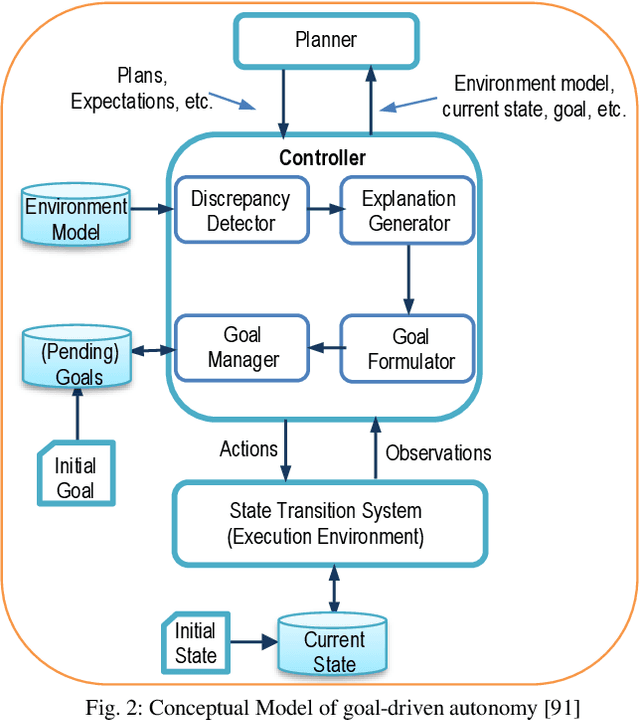
Recent applications of autonomous agents and robots, for example, self-driving cars, scenario-based trainers, exploration robots, service robots, have brought attention to crucial trust-related problems associated with the current generation of artificial intelligence (AI) systems. AI systems particularly dominated by the connectionist deep learning neural network approach lack capabilities of explaining their decisions and actions to others, despite their great successes. They are fundamentally non-intuitive black boxes, which renders their decision or actions opaque, making it difficult to trust them in safety-critical applications. The recent stance on the explainability of AI systems has witnessed several works on eXplainable Artificial Intelligence; however, most of the studies have focused on data-driven XAI systems applied in computational sciences. Studies addressing the increasingly pervasive goal-driven agents and robots are still missing. This paper reviews works on explainable goal-driven intelligent agents and robots, focusing on techniques for explaining and communicating agents perceptual functions (for example, senses, vision, etc.) and cognitive reasoning (for example, beliefs, desires, intention, plans, and goals) with humans in the loop. The review highlights key strategies that emphasize transparency and understandability, and continual learning for explainability. Finally, the paper presents requirements for explainability and suggests a roadmap for the possible realization of effective goal-driven explainable agents and robots
Improving Robot Dual-System Motor Learning with Intrinsically Motivated Meta-Control and Latent-Space Experience Imagination
Apr 19, 2020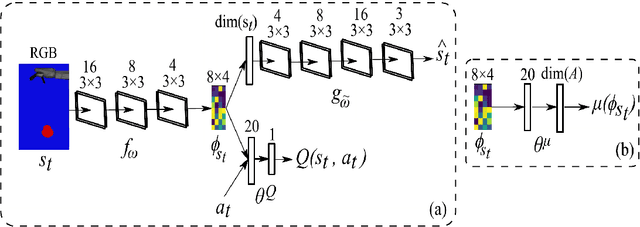
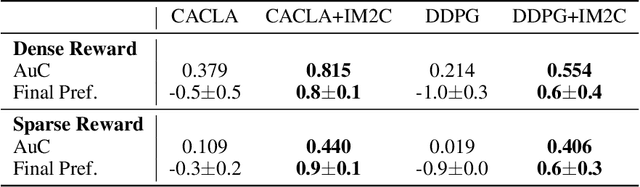
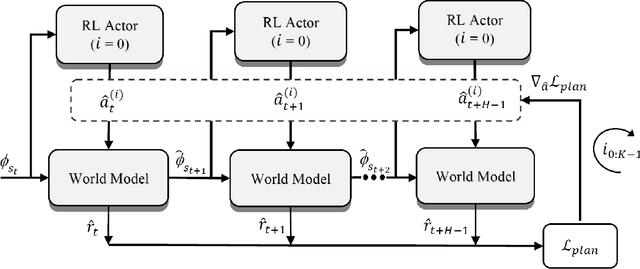

Combining model-based and model-free learning systems has been shown to improve the sample efficiency of learning to perform complex robotic tasks. However, dual-system approaches fail to consider the reliability of the learned model when it is applied to make multiple-step predictions, resulting in a compounding of prediction errors and performance degradation. In this paper, we present a novel dual-system motor learning approach where a meta-controller arbitrates online between model-based and model-free decisions based on an estimate of the local reliability of the learned model. The reliability estimate is used in computing an intrinsic feedback signal, encouraging actions that lead to data that improves the model. Our approach also integrates arbitration with imagination where a learned latent-space model generates imagined experiences, based on its local reliability, to be used as additional training data. We evaluate our approach against baseline and state-of-the-art methods on learning vision-based robotic grasping in simulation and real world. The results show that our approach outperforms the compared methods and learns near-optimal grasping policies in dense- and sparse-reward environments.