 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpatiotemporal Convolutions on EEG signal -- A Representation Learning Perspective on Efficient and Explainable EEG Classification with Convolutional Neural Nets
May 05, 2026Classification of EEG signals using shallow Convolutional Neural Networks (CNNs) is a prevalent and successful approach across a variety of fields. Most of these models use independent one-dimensional (1D) convolutional layers along the spatial and temporal dimensions, which are concatenated without a non-linear activation layer between. In this paper, we investigate an alternative encoding that operates a bi-dimensional (2D) spatiotemporal convolution. While 2D convolutions are numerically identical to two concatenated 1D convolutions along the two dimensions, the impact on learning is still uncertain. We test 1D and 2D CNNs and a CNN+transformer hybrid model in a low-dimensional (3-channel) and a high-dimensional (22-channel) BCI motor imagery classification task. We observe that 2D convolutions significantly reduce training time in high-dimensional tasks while maintaining performance. We investigate the root of this improvement and find no difference in spectral feature importance. However, a clear pattern emerges in representational similarity across models: 1D and 2D models yield vastly different representational geometries. Overall, we suggest an improved model with a 2D convolutional layer for faster training and inference. We also highlight the importance of architecturally-driven encoding when processing complex multivariate signals, as reflected in internal representations rather than purely in performance metrics.
Research Community Perspectives on "Intelligence" and Large Language Models
May 27, 2025Despite the widespread use of ''artificial intelligence'' (AI) framing in Natural Language Processing (NLP) research, it is not clear what researchers mean by ''intelligence''. To that end, we present the results of a survey on the notion of ''intelligence'' among researchers and its role in the research agenda. The survey elicited complete responses from 303 researchers from a variety of fields including NLP, Machine Learning (ML), Cognitive Science, Linguistics, and Neuroscience. We identify 3 criteria of intelligence that the community agrees on the most: generalization, adaptability, & reasoning. Our results suggests that the perception of the current NLP systems as ''intelligent'' is a minority position (29%). Furthermore, only 16.2% of the respondents see developing intelligent systems as a research goal, and these respondents are more likely to consider the current systems intelligent.
Improving Reasoning Performance in Large Language Models via Representation Engineering
Apr 28, 2025



Recent advancements in large language models (LLMs) have resulted in increasingly anthropomorphic language concerning the ability of LLMs to reason. Whether reasoning in LLMs should be understood to be inherently different is, however, widely debated. We propose utilizing a representation engineering approach wherein model activations are read from the residual stream of an LLM when processing a reasoning task. The activations are used to derive a control vector that is applied to the model as an inference-time intervention, modulating the representational space of the model, to improve performance on the specified task. We publish the code for deriving control vectors and analyzing model representations. The method allows us to improve performance on reasoning benchmarks and assess how control vectors influence the final logit distribution of a model via metrics such as KL divergence and entropy. We apply control vectors to Mistral-7B-Instruct and a range of Pythia models on an inductive, a deductive and mathematical reasoning task. We show that an LLM can, to a certain degree, be controlled to improve its perceived reasoning ability by modulating activations. The intervention is dependent upon the ability to reliably extract the model's typical state when correctly solving a task. Our results suggest that reasoning performance can be modulated in the same manner as other information-processing tasks performed by LLMs and demonstrate that we are capable of improving performance on specific tasks via a simple intervention on the residual stream with no additional training.
Exploring Deep Learning Models for EEG Neural Decoding
Mar 20, 2025Neural decoding is an important method in cognitive neuroscience that aims to decode brain representations from recorded neural activity using a multivariate machine learning model. The THINGS initiative provides a large EEG dataset of 46 subjects watching rapidly shown images. Here, we test the feasibility of using this method for decoding high-level object features using recent deep learning models. We create a derivative dataset from this of living vs non-living entities test 15 different deep learning models with 5 different architectures and compare to a SOTA linear model. We show that the linear model is not able to solve the decoding task, while almost all the deep learning models are successful, suggesting that in some cases non-linear models are needed to decode neural representations. We also run a comparative study of the models' performance on individual object categories, and suggest how artificial neural networks can be used to study brain activity.
Don't Get Too Excited -- Eliciting Emotions in LLMs
Mar 04, 2025This paper investigates the challenges of affect control in large language models (LLMs), focusing on their ability to express appropriate emotional states during extended dialogues. We evaluated state-of-the-art open-weight LLMs to assess their affective expressive range in terms of arousal and valence. Our study employs a novel methodology combining LLM-based sentiment analysis with multiturn dialogue simulations between LLMs. We quantify the models' capacity to express a wide spectrum of emotions and how they fluctuate during interactions. Our findings reveal significant variations among LLMs in their ability to maintain consistent affect, with some models demonstrating more stable emotional trajectories than others. Furthermore, we identify key challenges in affect control, including difficulties in producing and maintaining extreme emotional states and limitations in adapting affect to changing conversational contexts. These findings have important implications for the development of more emotionally intelligent AI systems and highlight the need for improved affect modelling in LLMs.
Prioritized Soft Q-Decomposition for Lexicographic Reinforcement Learning
Oct 03, 2023Reinforcement learning (RL) for complex tasks remains a challenge, primarily due to the difficulties of engineering scalar reward functions and the inherent inefficiency of training models from scratch. Instead, it would be better to specify complex tasks in terms of elementary subtasks and to reuse subtask solutions whenever possible. In this work, we address continuous space lexicographic multi-objective RL problems, consisting of prioritized subtasks, which are notoriously difficult to solve. We show that these can be scalarized with a subtask transformation and then solved incrementally using value decomposition. Exploiting this insight, we propose prioritized soft Q-decomposition (PSQD), a novel algorithm for learning and adapting subtask solutions under lexicographic priorities in continuous state-action spaces. PSQD offers the ability to reuse previously learned subtask solutions in a zero-shot composition, followed by an adaptation step. Its ability to use retained subtask training data for offline learning eliminates the need for new environment interaction during adaptation. We demonstrate the efficacy of our approach by presenting successful learning, reuse, and adaptation results for both low- and high-dimensional simulated robot control tasks, as well as offline learning results. In contrast to baseline approaches, PSQD does not trade off between conflicting subtasks or priority constraints and satisfies subtask priorities during learning. PSQD provides an intuitive framework for tackling complex RL problems, offering insights into the inner workings of the subtask composition.
Detection of Furigana Text in Images
Jul 08, 2022
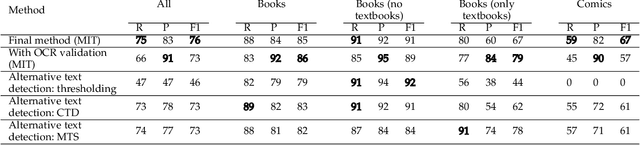
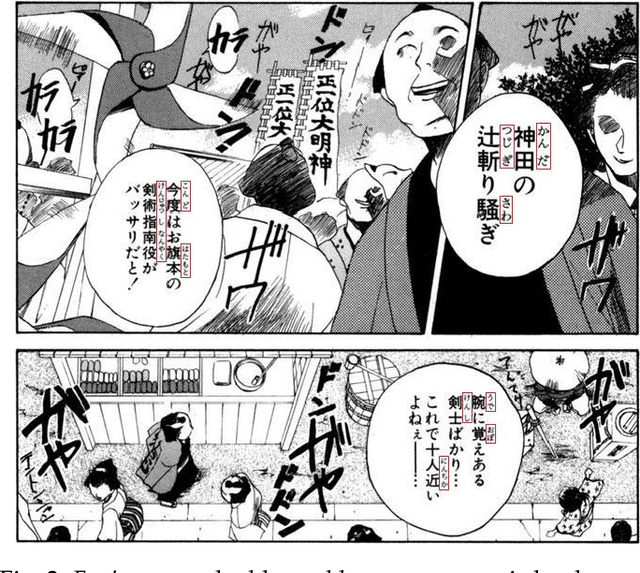
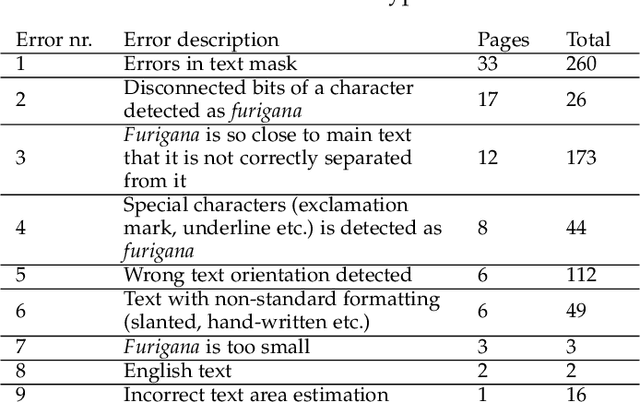
Furigana are pronunciation notes used in Japanese writing. Being able to detect these can help improve optical character recognition (OCR) performance or make more accurate digital copies of Japanese written media by correctly displaying furigana. This project focuses on detecting furigana in Japanese books and comics. While there has been research into the detection of Japanese text in general, there are currently no proposed methods for detecting furigana. We construct a new dataset containing Japanese written media and annotations of furigana. We propose an evaluation metric for such data which is similar to the evaluation protocols used in object detection except that it allows groups of objects to be labeled by one annotation. We propose a method for detection of furigana that is based on mathematical morphology and connected component analysis. We evaluate the detections of the dataset and compare different methods for text extraction. We also evaluate different types of images such as books and comics individually and discuss the challenges of each type of image. The proposed method reaches an F1-score of 76\% on the dataset. The method performs well on regular books, but less so on comics, and books of irregular format. Finally, we show that the proposed method can improve the performance of OCR by 5\% on the manga109 dataset. Source code is available via \texttt{\url{https://github.com/nikolajkb/FuriganaDetection}}
Crossmodal Language Grounding in an Embodied Neurocognitive Model
Jun 24, 2020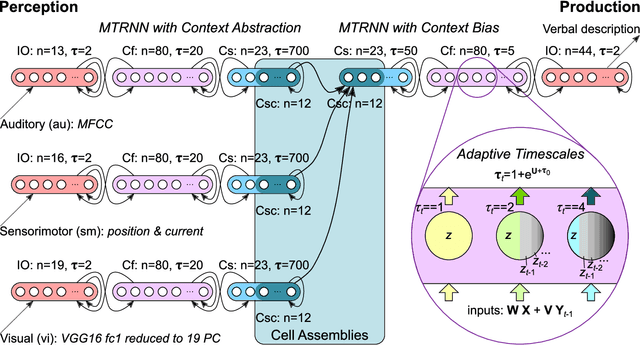

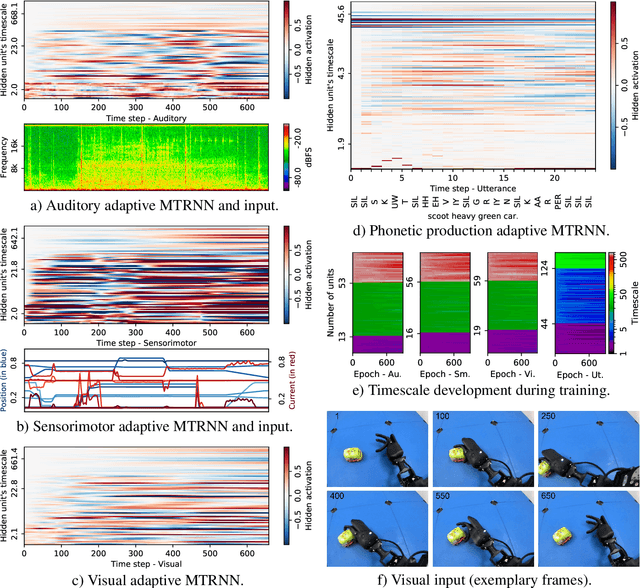
Human infants are able to acquire natural language seemingly easily at an early age. Their language learning seems to occur simultaneously with learning other cognitive functions as well as with playful interactions with the environment and caregivers. From a neuroscientific perspective, natural language is embodied, grounded in most, if not all, sensory and sensorimotor modalities, and acquired by means of crossmodal integration. However, characterising the underlying mechanisms in the brain is difficult and explaining the grounding of language in crossmodal perception and action remains challenging. In this paper, we present a neurocognitive model for language grounding which reflects bio-inspired mechanisms such as an implicit adaptation of timescales as well as end-to-end multimodal abstraction. It addresses developmental robotic interaction and extends its learning capabilities using larger-scale knowledge-based data. In our scenario, we utilise the humanoid robot NICO in obtaining the EMIL data collection, in which the cognitive robot interacts with objects in a children's playground environment while receiving linguistic labels from a caregiver. The model analysis shows that crossmodally integrated representations are sufficient for acquiring language merely from sensory input through interaction with objects in an environment. The representations self-organise hierarchically and embed temporal and spatial information through composition and decomposition. This model can also provide the basis for further crossmodal integration of perceptually grounded cognitive representations.
Semantic Object Accuracy for Generative Text-to-Image Synthesis
Oct 29, 2019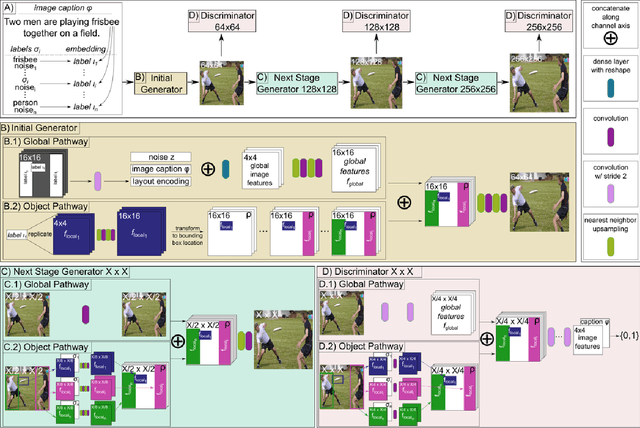
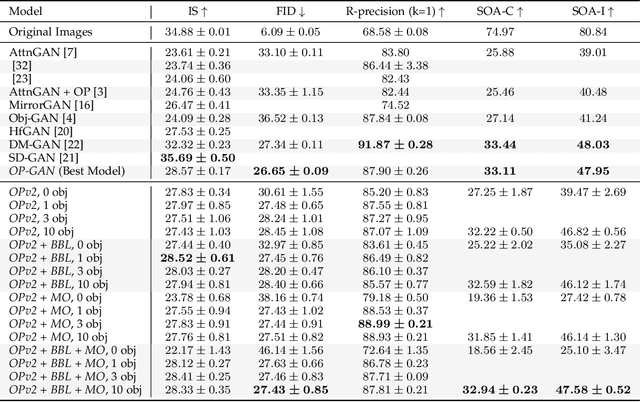

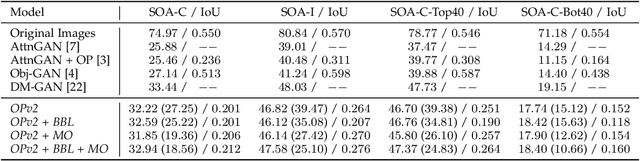
Generative adversarial networks conditioned on simple textual image descriptions are capable of generating realistic-looking images. However, current methods still struggle to generate images based on complex image captions from a heterogeneous domain. Furthermore, quantitatively evaluating these text-to-image synthesis models is still challenging, as most evaluation metrics only judge image quality but not the conformity between the image and its caption. To address the aforementioned challenges we introduce both a new model that explicitly models individual objects within an image and a new evaluation metric called Semantic Object Accuracy (SOA) that specifically evaluates images given an image caption. Our model adds an object pathway to both the generator and the discriminator to explicitly learn features of individual objects. The SOA uses a pre-trained object detector to evaluate if a generated image contains objects that are specifically mentioned in the image caption, e.g. whether an image generated from "a car driving down the street" contains a car. Our evaluation shows that models which explicitly model individual objects outperform models which only model global image characteristics. However, the SOA also shows that despite this increased performance current models still struggle to generate images that contain realistic objects of multiple different domains.
Generating Multiple Objects at Spatially Distinct Locations
Jan 03, 2019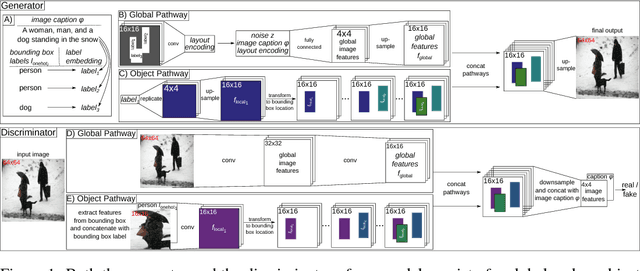
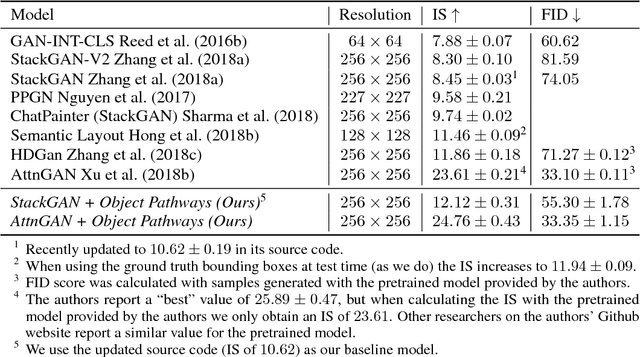
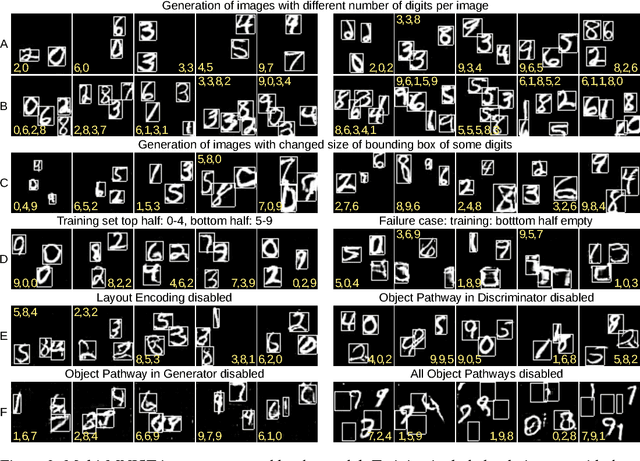
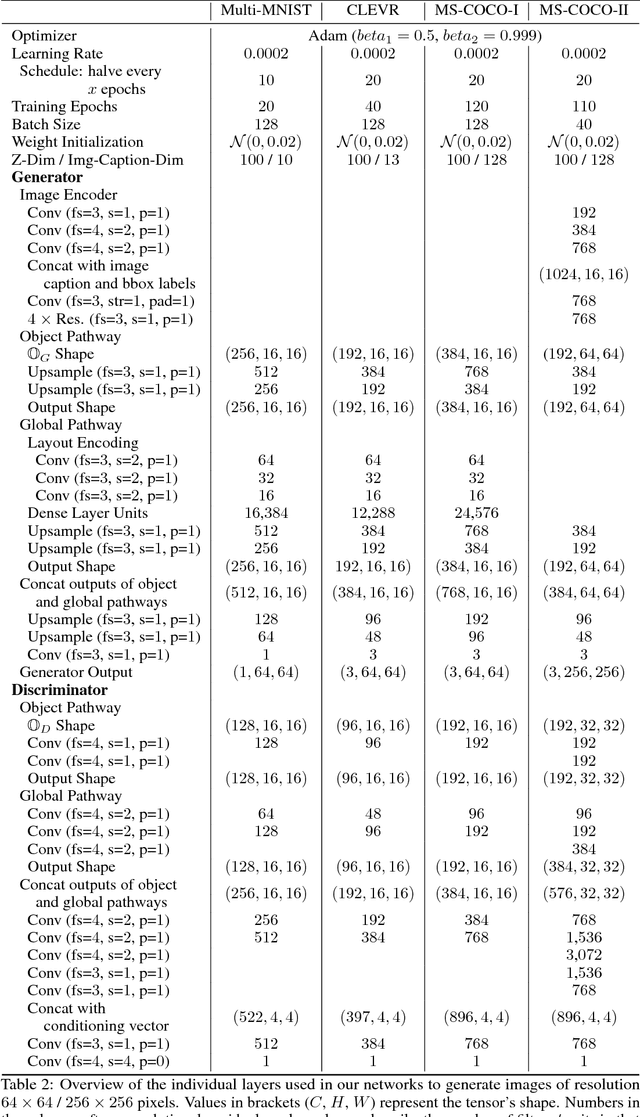
Recent improvements to Generative Adversarial Networks (GANs) have made it possible to generate realistic images in high resolution based on natural language descriptions such as image captions. Furthermore, conditional GANs allow us to control the image generation process through labels or even natural language descriptions. However, fine-grained control of the image layout, i.e. where in the image specific objects should be located, is still difficult to achieve. This is especially true for images that should contain multiple distinct objects at different spatial locations. We introduce a new approach which allows us to control the location of arbitrarily many objects within an image by adding an object pathway to both the generator and the discriminator. Our approach does not need a detailed semantic layout but only bounding boxes and the respective labels of the desired objects are needed. The object pathway focuses solely on the individual objects and is iteratively applied at the locations specified by the bounding boxes. The global pathway focuses on the image background and the general image layout. We perform experiments on the Multi-MNIST, CLEVR, and the more complex MS-COCO data set. Our experiments show that through the use of the object pathway we can control object locations within images and can model complex scenes with multiple objects at various locations. We further show that the object pathway focuses on the individual objects and learns features relevant for these, while the global pathway focuses on global image characteristics and the image background.