 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProbabilistic Warp Consistency for Weakly-Supervised Semantic Correspondences
Mar 08, 2022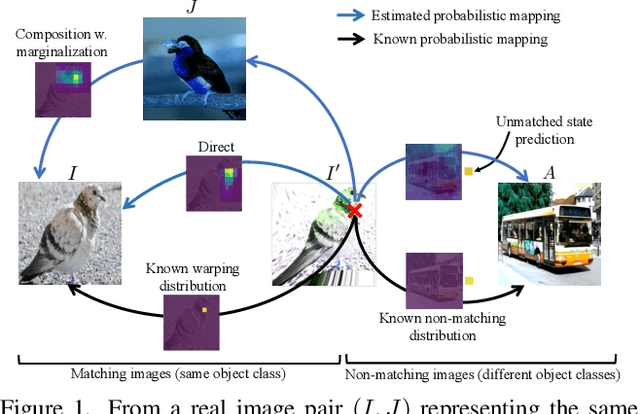
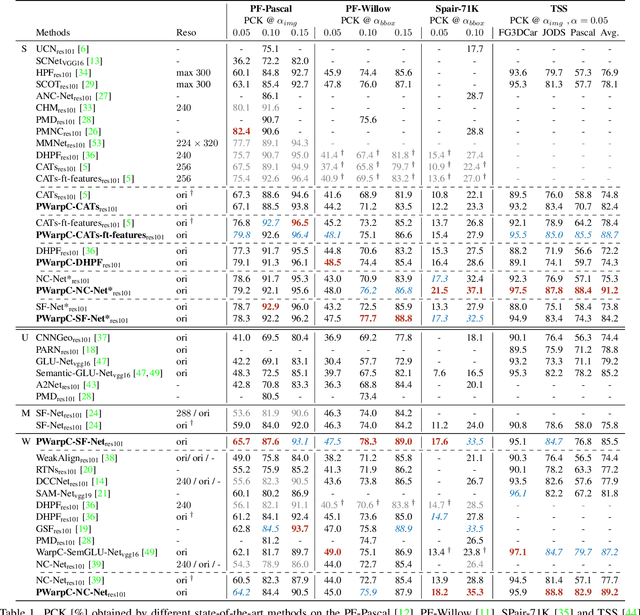
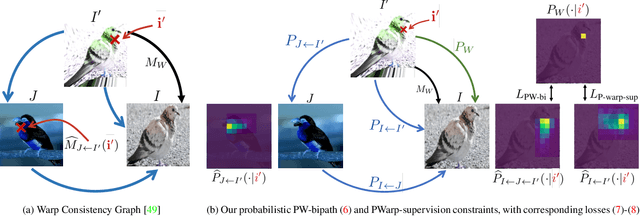
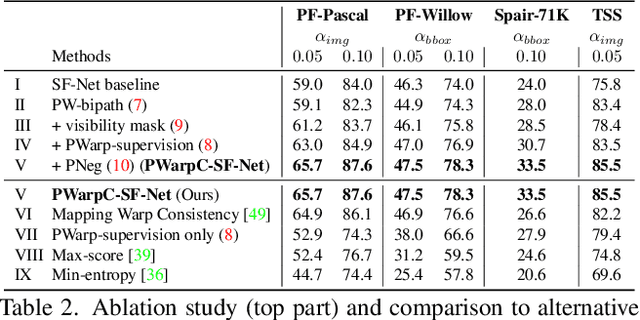
We propose Probabilistic Warp Consistency, a weakly-supervised learning objective for semantic matching. Our approach directly supervises the dense matching scores predicted by the network, encoded as a conditional probability distribution. We first construct an image triplet by applying a known warp to one of the images in a pair depicting different instances of the same object class. Our probabilistic learning objectives are then derived using the constraints arising from the resulting image triplet. We further account for occlusion and background clutter present in real image pairs by extending our probabilistic output space with a learnable unmatched state. To supervise it, we design an objective between image pairs depicting different object classes. We validate our method by applying it to four recent semantic matching architectures. Our weakly-supervised approach sets a new state-of-the-art on four challenging semantic matching benchmarks. Lastly, we demonstrate that our objective also brings substantial improvements in the strongly-supervised regime, when combined with keypoint annotations.
* Accepted at CVPR 2022 code: https://github.com/PruneTruong/DenseMatching
Adiabatic Quantum Computing for Multi Object Tracking
Feb 17, 2022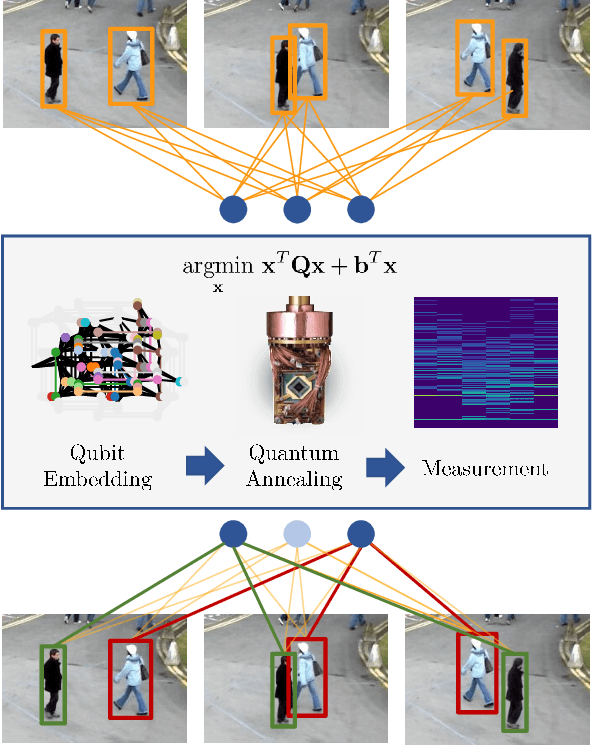
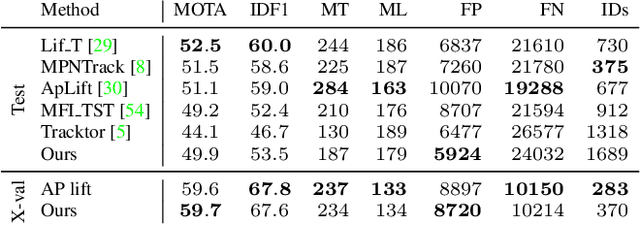
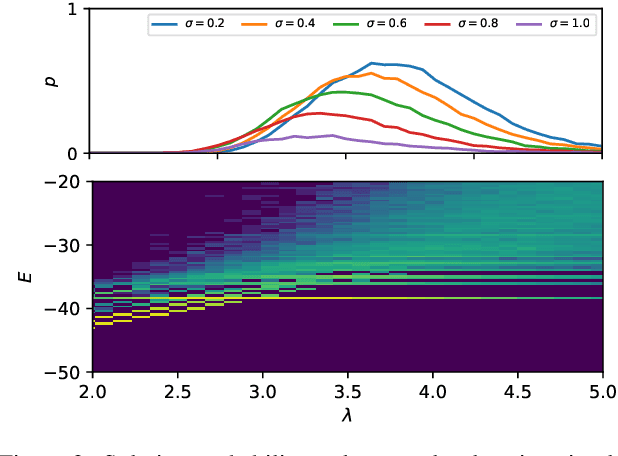
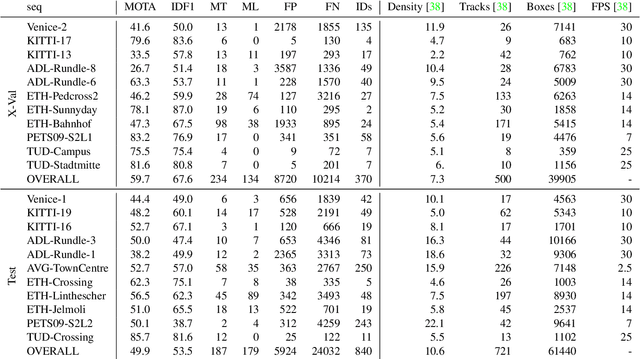
Multi-Object Tracking (MOT) is most often approached in the tracking-by-detection paradigm, where object detections are associated through time. The association step naturally leads to discrete optimization problems. As these optimization problems are often NP-hard, they can only be solved exactly for small instances on current hardware. Adiabatic quantum computing (AQC) offers a solution for this, as it has the potential to provide a considerable speedup on a range of NP-hard optimization problems in the near future. However, current MOT formulations are unsuitable for quantum computing due to their scaling properties. In this work, we therefore propose the first MOT formulation designed to be solved with AQC. We employ an Ising model that represents the quantum mechanical system implemented on the AQC. We show that our approach is competitive compared with state-of-the-art optimization-based approaches, even when using of-the-shelf integer programming solvers. Finally, we demonstrate that our MOT problem is already solvable on the current generation of real quantum computers for small examples, and analyze the properties of the measured solutions.
RePaint: Inpainting using Denoising Diffusion Probabilistic Models
Feb 07, 2022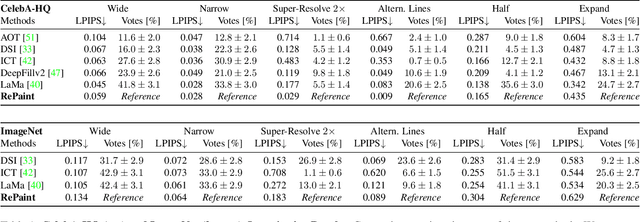
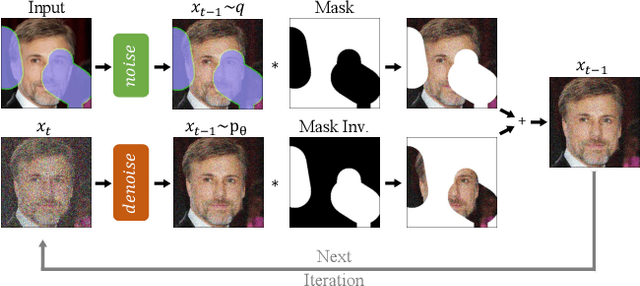


Free-form inpainting is the task of adding new content to an image in the regions specified by an arbitrary binary mask. Most existing approaches train for a certain distribution of masks, which limits their generalization capabilities to unseen mask types. Furthermore, training with pixel-wise and perceptual losses often leads to simple textural extensions towards the missing areas instead of semantically meaningful generation. In this work, we propose RePaint: A Denoising Diffusion Probabilistic Model (DDPM) based inpainting approach that is applicable to even extreme masks. We employ a pretrained unconditional DDPM as the generative prior. To condition the generation process, we only alter the reverse diffusion iterations by sampling the unmasked regions using the given image information. Since this technique does not modify or condition the original DDPM network itself, the model produces high-quality and diverse output images for any inpainting form. We validate our method for both faces and general-purpose image inpainting using standard and extreme masks. RePaint outperforms state-of-the-art Autoregressive, and GAN approaches for at least five out of six mask distributions. Github Repository: git.io/RePaint
Fast Online Video Super-Resolution with Deformable Attention Pyramid
Feb 03, 2022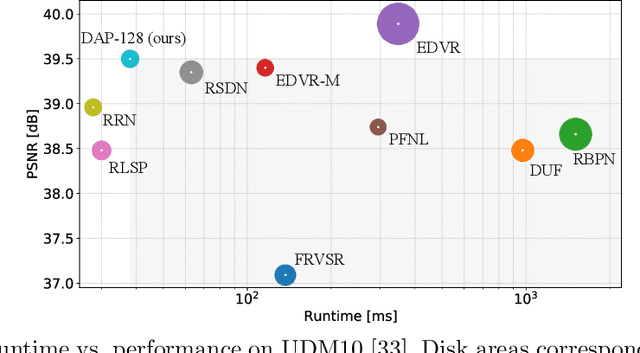

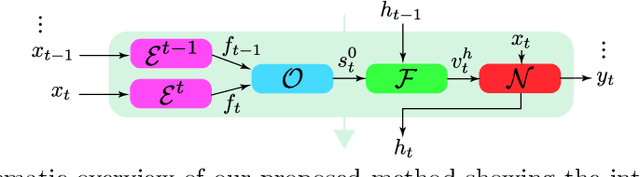

Video super-resolution (VSR) has many applications that pose strict causal, real-time, and latency constraints, including video streaming and TV. We address the VSR problem under these settings, which poses additional important challenges since information from future frames are unavailable. Importantly, designing efficient, yet effective frame alignment and fusion modules remain central problems. In this work, we propose a recurrent VSR architecture based on a deformable attention pyramid (DAP). Our DAP aligns and integrates information from the recurrent state into the current frame prediction. To circumvent the computational cost of traditional attention-based methods, we only attend to a limited number of spatial locations, which are dynamically predicted by the DAP. Comprehensive experiments and analysis of the proposed key innovations show the effectiveness of our approach. We significantly reduce processing time in comparison to state-of-the-art methods, while maintaining a high performance. We surpass state-of-the-art method EDVR-M on two standard benchmarks with a speed-up of over 3x.
Collapse by Conditioning: Training Class-conditional GANs with Limited Data
Jan 17, 2022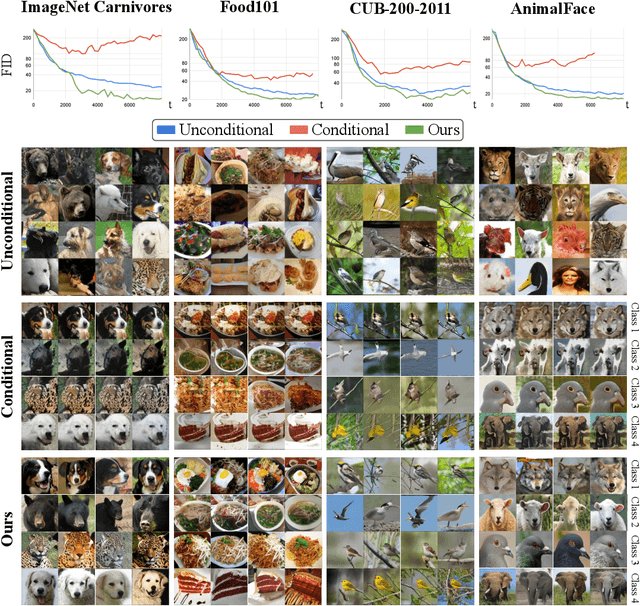
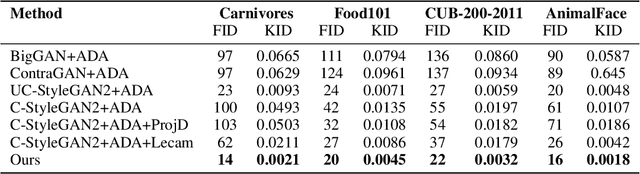

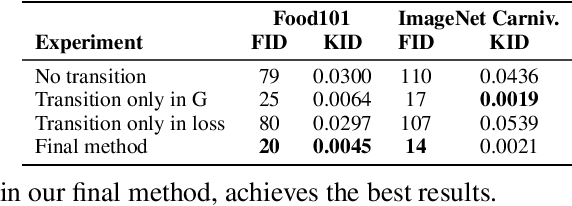
Class-conditioning offers a direct means of controlling a Generative Adversarial Network (GAN) based on a discrete input variable. While necessary in many applications, the additional information provided by the class labels could even be expected to benefit the training of the GAN itself. Contrary to this belief, we observe that class-conditioning causes mode collapse in limited data settings, where unconditional learning leads to satisfactory generative ability. Motivated by this observation, we propose a training strategy for conditional GANs (cGANs) that effectively prevents the observed mode-collapse by leveraging unconditional learning. Our training strategy starts with an unconditional GAN and gradually injects conditional information into the generator and the objective function. The proposed method for training cGANs with limited data results not only in stable training but also in generating high-quality images, thanks to the early-stage exploitation of the shared information across classes. We analyze the aforementioned mode collapse problem in comprehensive experiments on four datasets. Our approach demonstrates outstanding results compared with state-of-the-art methods and established baselines. The code is available at: https://github.com/mshahbazi72/transitional-cGAN
Efficient Visual Tracking with Exemplar Transformers
Dec 17, 2021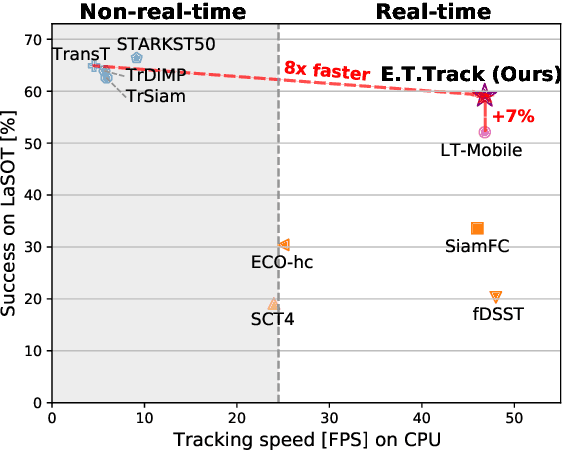
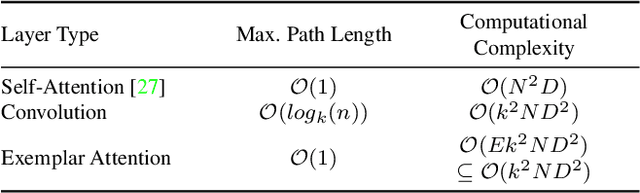
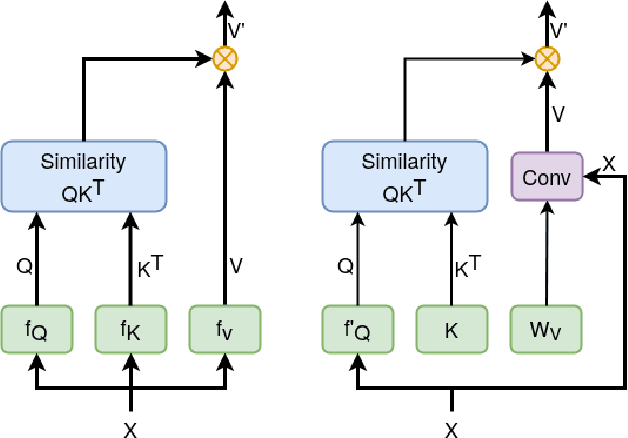

The design of more complex and powerful neural network models has significantly advanced the state-of-the-art in visual object tracking. These advances can be attributed to deeper networks, or to the introduction of new building blocks, such as transformers. However, in the pursuit of increased tracking performance, efficient tracking architectures have received surprisingly little attention. In this paper, we introduce the Exemplar Transformer, an efficient transformer for real-time visual object tracking. E.T.Track, our visual tracker that incorporates Exemplar Transformer layers, runs at 47 fps on a CPU. This is up to 8 times faster than other transformer-based models, making it the only real-time transformer-based tracker. When compared to lightweight trackers that can operate in real-time on standard CPUs, E.T.Track consistently outperforms all other methods on the LaSOT, OTB-100, NFS, TrackingNet and VOT-ST2020 datasets. The code will soon be released on https://github.com/visionml/pytracking.
Visual Object Tracking with Discriminative Filters and Siamese Networks: A Survey and Outlook
Dec 06, 2021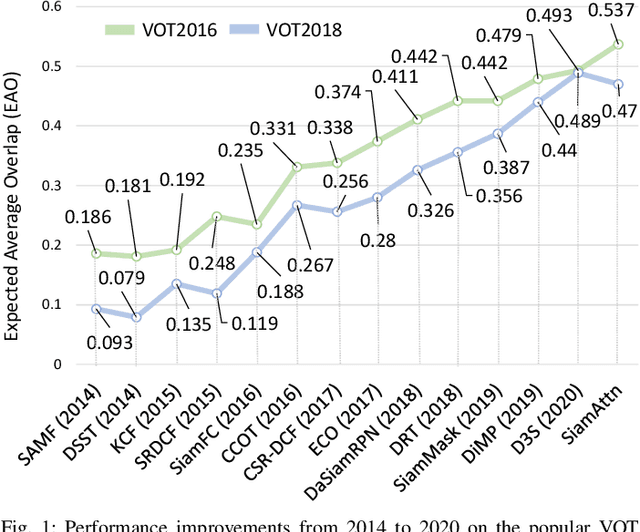
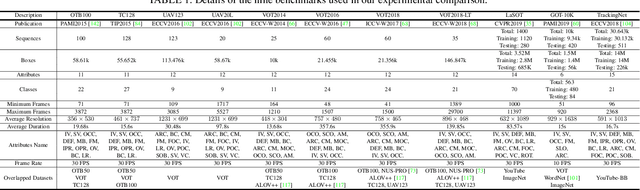
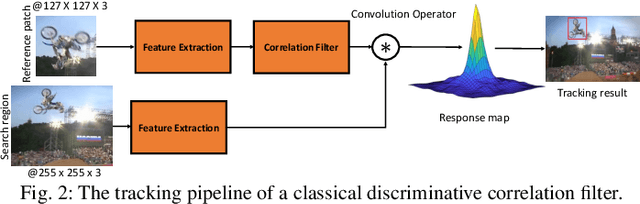
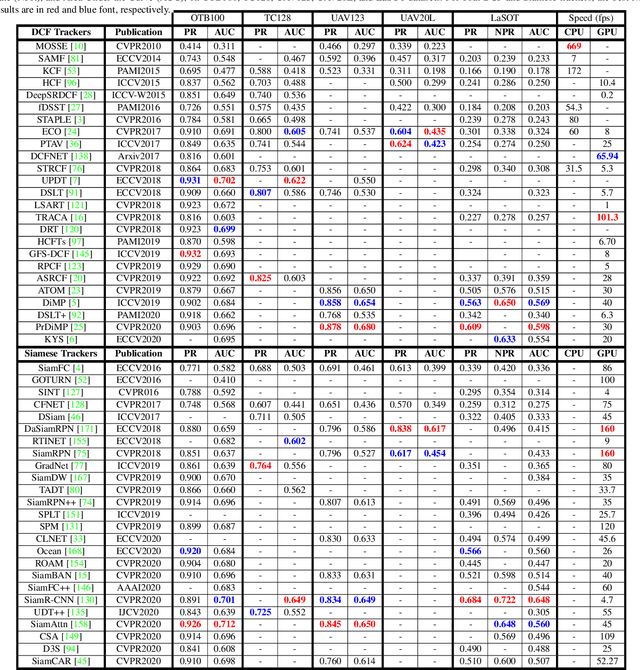
Accurate and robust visual object tracking is one of the most challenging and fundamental computer vision problems. It entails estimating the trajectory of the target in an image sequence, given only its initial location, and segmentation, or its rough approximation in the form of a bounding box. Discriminative Correlation Filters (DCFs) and deep Siamese Networks (SNs) have emerged as dominating tracking paradigms, which have led to significant progress. Following the rapid evolution of visual object tracking in the last decade, this survey presents a systematic and thorough review of more than 90 DCFs and Siamese trackers, based on results in nine tracking benchmarks. First, we present the background theory of both the DCF and Siamese tracking core formulations. Then, we distinguish and comprehensively review the shared as well as specific open research challenges in both these tracking paradigms. Furthermore, we thoroughly analyze the performance of DCF and Siamese trackers on nine benchmarks, covering different experimental aspects of visual tracking: datasets, evaluation metrics, performance, and speed comparisons. We finish the survey by presenting recommendations and suggestions for distinguished open challenges based on our analysis.
Mask Transfiner for High-Quality Instance Segmentation
Nov 26, 2021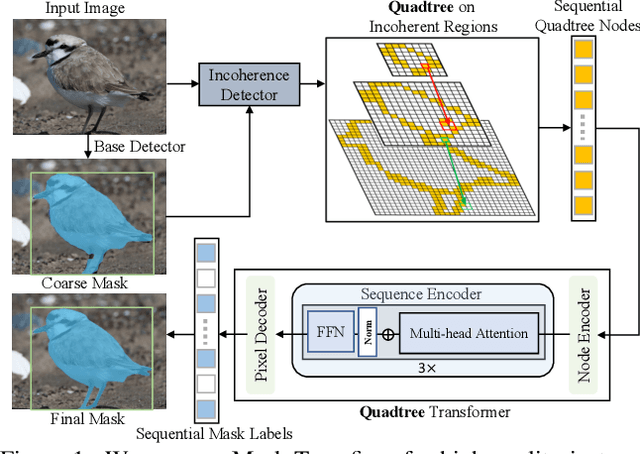


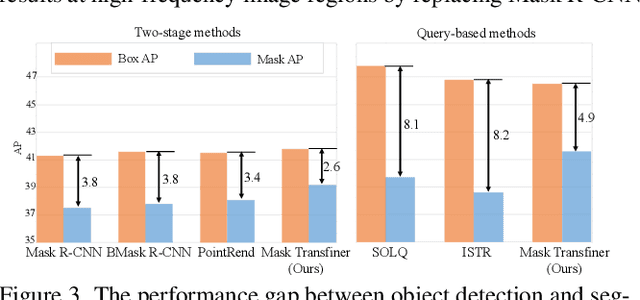
Two-stage and query-based instance segmentation methods have achieved remarkable results. However, their segmented masks are still very coarse. In this paper, we present Mask Transfiner for high-quality and efficient instance segmentation. Instead of operating on regular dense tensors, our Mask Transfiner decomposes and represents the image regions as a quadtree. Our transformer-based approach only processes detected error-prone tree nodes and self-corrects their errors in parallel. While these sparse pixels only constitute a small proportion of the total number, they are critical to the final mask quality. This allows Mask Transfiner to predict highly accurate instance masks, at a low computational cost. Extensive experiments demonstrate that Mask Transfiner outperforms current instance segmentation methods on three popular benchmarks, significantly improving both two-stage and query-based frameworks by a large margin of +3.0 mask AP on COCO and BDD100K, and +6.6 boundary AP on Cityscapes. Our code and trained models will be available at http://vis.xyz/pub/transfiner.
Normalizing Flow as a Flexible Fidelity Objective for Photo-Realistic Super-resolution
Nov 05, 2021
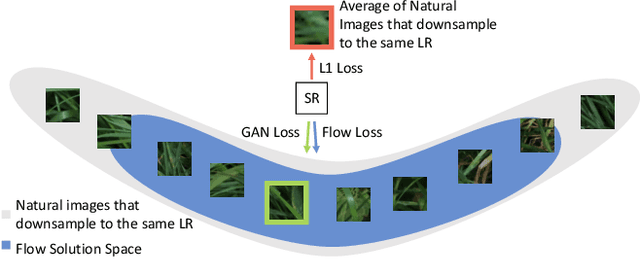
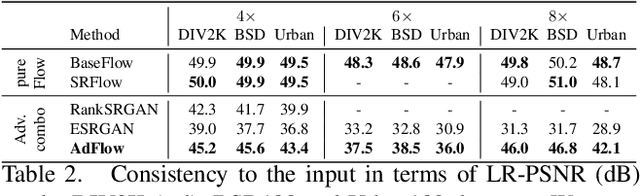
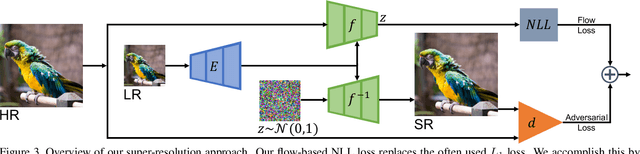
Super-resolution is an ill-posed problem, where a ground-truth high-resolution image represents only one possibility in the space of plausible solutions. Yet, the dominant paradigm is to employ pixel-wise losses, such as L_1, which drive the prediction towards a blurry average. This leads to fundamentally conflicting objectives when combined with adversarial losses, which degrades the final quality. We address this issue by revisiting the L_1 loss and show that it corresponds to a one-layer conditional flow. Inspired by this relation, we explore general flows as a fidelity-based alternative to the L_1 objective. We demonstrate that the flexibility of deeper flows leads to better visual quality and consistency when combined with adversarial losses. We conduct extensive user studies for three datasets and scale factors, where our approach is shown to outperform state-of-the-art methods for photo-realistic super-resolution. Code and trained models will be available at: git.io/AdFlow
Learning Proposals for Practical Energy-Based Regression
Oct 22, 2021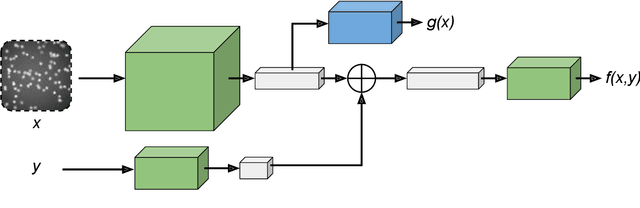
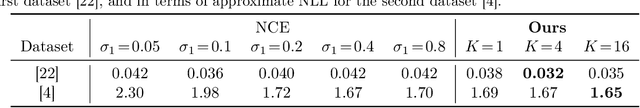
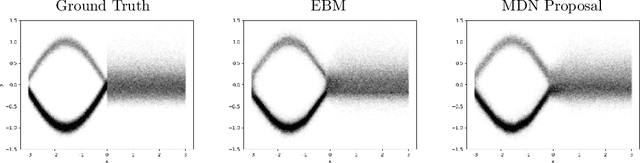

Energy-based models (EBMs) have experienced a resurgence within machine learning in recent years, including as a promising alternative for probabilistic regression. However, energy-based regression requires a proposal distribution to be manually designed for training, and an initial estimate has to be provided at test-time. We address both of these issues by introducing a conceptually simple method to automatically learn an effective proposal distribution, which is parameterized by a separate network head. To this end, we derive a surprising result, leading to a unified training objective that jointly minimizes the KL divergence from the proposal to the EBM, and the negative log-likelihood of the EBM. At test-time, we can then employ importance sampling with the trained proposal to efficiently evaluate the learned EBM and produce stand-alone predictions. Furthermore, we utilize our derived training objective to learn mixture density networks (MDNs) with a jointly trained energy-based teacher, consistently outperforming conventional MDN training on four real-world regression tasks within computer vision. Code is available at https://github.com/fregu856/ebms_proposals.