 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePinpoint, Not Criticize: Refining Large Language Models via Fine-Grained Actionable Feedback
Nov 15, 2023



Recent improvements in text generation have leveraged human feedback to improve the quality of the generated output. However, human feedback is not always available, especially during inference. In this work, we propose an inference time optimization method FITO to use fine-grained actionable feedback in the form of error type, error location and severity level that are predicted by a learned error pinpoint model for iterative refinement. FITO starts with an initial output, then iteratively incorporates the feedback via a refinement model that generates an improved output conditioned on the feedback. Given the uncertainty of consistent refined samples at iterative steps, we formulate iterative refinement into a local search problem and develop a simulated annealing based algorithm that balances exploration of the search space and optimization for output quality. We conduct experiments on three text generation tasks, including machine translation, long-form question answering (QA) and topical summarization. We observe 0.8 and 0.7 MetricX gain on Chinese-English and English-German translation, 4.5 and 1.8 ROUGE-L gain at long form QA and topic summarization respectively, with a single iteration of refinement. With our simulated annealing algorithm, we see further quality improvements, including up to 1.7 MetricX improvements over the baseline approach.
There's no Data Like Better Data: Using QE Metrics for MT Data Filtering
Nov 09, 2023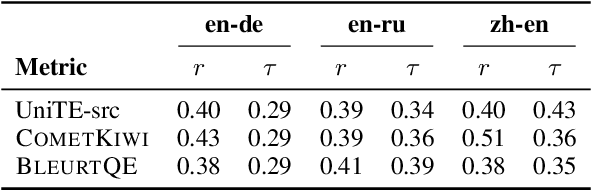
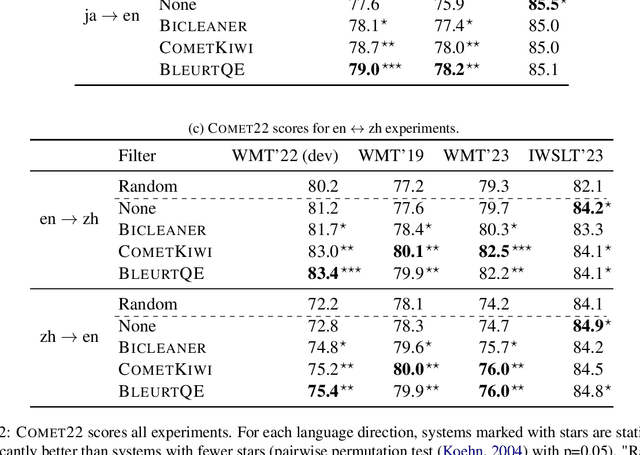
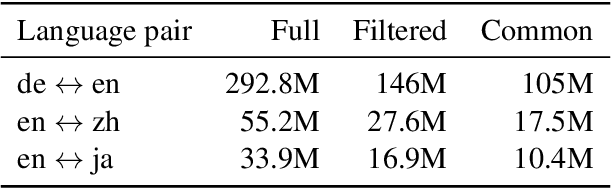

Quality Estimation (QE), the evaluation of machine translation output without the need of explicit references, has seen big improvements in the last years with the use of neural metrics. In this paper we analyze the viability of using QE metrics for filtering out bad quality sentence pairs in the training data of neural machine translation systems~(NMT). While most corpus filtering methods are focused on detecting noisy examples in collections of texts, usually huge amounts of web crawled data, QE models are trained to discriminate more fine-grained quality differences. We show that by selecting the highest quality sentence pairs in the training data, we can improve translation quality while reducing the training size by half. We also provide a detailed analysis of the filtering results, which highlights the differences between both approaches.
Quality Control at Your Fingertips: Quality-Aware Translation Models
Oct 10, 2023Maximum-a-posteriori (MAP) decoding is the most widely used decoding strategy for neural machine translation (NMT) models. The underlying assumption is that model probability correlates well with human judgment, with better translations being more likely. However, research has shown that this assumption does not always hold, and decoding strategies which directly optimize a utility function, like Minimum Bayes Risk (MBR) or Quality-Aware decoding can significantly improve translation quality over standard MAP decoding. The main disadvantage of these methods is that they require an additional model to predict the utility, and additional steps during decoding, which makes the entire process computationally demanding. In this paper, we propose to make the NMT models themselves quality-aware by training them to estimate the quality of their own output. During decoding, we can use the model's own quality estimates to guide the generation process and produce the highest-quality translations possible. We demonstrate that the model can self-evaluate its own output during translation, eliminating the need for a separate quality estimation model. Moreover, we show that using this quality signal as a prompt during MAP decoding can significantly improve translation quality. When using the internal quality estimate to prune the hypothesis space during MBR decoding, we can not only further improve translation quality, but also reduce inference speed by two orders of magnitude.
MBR and QE Finetuning: Training-time Distillation of the Best and Most Expensive Decoding Methods
Sep 28, 2023Recent research in decoding methods for Natural Language Generation (NLG) tasks has shown that MAP decoding is not optimal, because model probabilities do not always align with human preferences. Stronger decoding methods, including Quality Estimation (QE) reranking and Minimum Bayes' Risk (MBR) decoding, have since been proposed to mitigate the model-perplexity-vs-quality mismatch. While these decoding methods achieve state-of-the-art performance, they are prohibitively expensive to compute. In this work, we propose MBR finetuning and QE finetuning which distill the quality gains from these decoding methods at training time, while using an efficient decoding algorithm at inference time. Using the canonical NLG task of Neural Machine Translation (NMT), we show that even with self-training, these finetuning methods significantly outperform the base model. Moreover, when using an external LLM as a teacher model, these finetuning methods outperform finetuning on human-generated references. These findings suggest new ways to leverage monolingual data to achieve improvements in model quality that are on par with, or even exceed, improvements from human-curated data, while maintaining maximum efficiency during decoding.
Training and Meta-Evaluating Machine Translation Evaluation Metrics at the Paragraph Level
Aug 28, 2023



As research on machine translation moves to translating text beyond the sentence level, it remains unclear how effective automatic evaluation metrics are at scoring longer translations. In this work, we first propose a method for creating paragraph-level data for training and meta-evaluating metrics from existing sentence-level data. Then, we use these new datasets to benchmark existing sentence-level metrics as well as train learned metrics at the paragraph level. Interestingly, our experimental results demonstrate that using sentence-level metrics to score entire paragraphs is equally as effective as using a metric designed to work at the paragraph level. We speculate this result can be attributed to properties of the task of reference-based evaluation as well as limitations of our datasets with respect to capturing all types of phenomena that occur in paragraph-level translations.
The Devil is in the Errors: Leveraging Large Language Models for Fine-grained Machine Translation Evaluation
Aug 14, 2023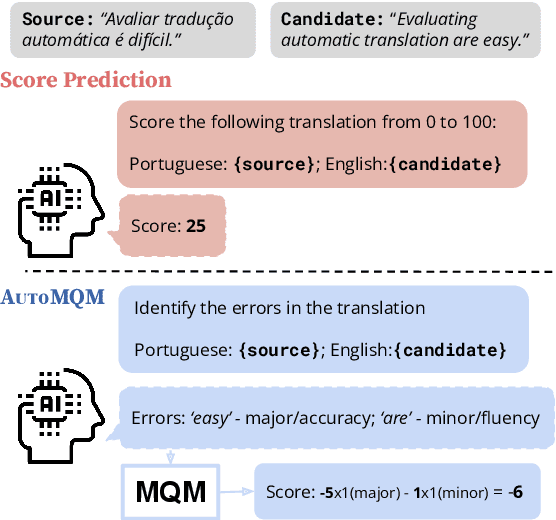

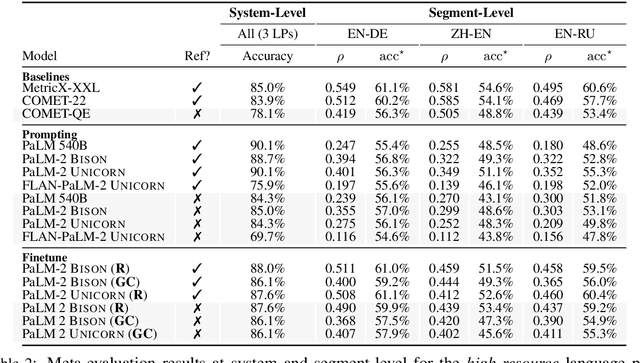
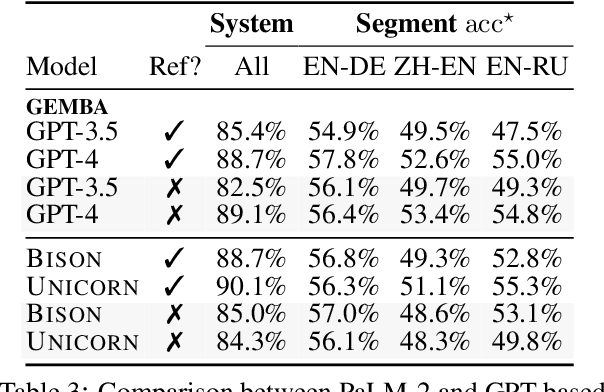
Automatic evaluation of machine translation (MT) is a critical tool driving the rapid iterative development of MT systems. While considerable progress has been made on estimating a single scalar quality score, current metrics lack the informativeness of more detailed schemes that annotate individual errors, such as Multidimensional Quality Metrics (MQM). In this paper, we help fill this gap by proposing AutoMQM, a prompting technique which leverages the reasoning and in-context learning capabilities of large language models (LLMs) and asks them to identify and categorize errors in translations. We start by evaluating recent LLMs, such as PaLM and PaLM-2, through simple score prediction prompting, and we study the impact of labeled data through in-context learning and finetuning. We then evaluate AutoMQM with PaLM-2 models, and we find that it improves performance compared to just prompting for scores (with particularly large gains for larger models) while providing interpretability through error spans that align with human annotations.
Ties Matter: Modifying Kendall's Tau for Modern Metric Meta-Evaluation
May 23, 2023



Kendall's tau is frequently used to meta-evaluate how well machine translation (MT) evaluation metrics score individual translations. Its focus on pairwise score comparisons is intuitive but raises the question of how ties should be handled, a gray area that has motivated different variants in the literature. We demonstrate that, in settings like modern MT meta-evaluation, existing variants have weaknesses arising from their handling of ties, and in some situations can even be gamed. We propose a novel variant that gives metrics credit for correctly predicting ties, as well as an optimization procedure that automatically introduces ties into metric scores, enabling fair comparison between metrics that do and do not predict ties. We argue and provide experimental evidence that these modifications lead to fairer Kendall-based assessments of metric performance.
INSTRUCTSCORE: Towards Explainable Text Generation Evaluation with Automatic Feedback
May 23, 2023



The field of automatic evaluation of text generation made tremendous progress in the last few years. In particular, since the advent of neural metrics, like COMET, BLEURT, and SEScore2, the newest generation of metrics show a high correlation with human judgment. Unfortunately, quality scores generated with neural metrics are not interpretable, and it is unclear which part of the generation output is criticized by the metrics. To address this limitation, we present INSTRUCTSCORE, an open-source, explainable evaluation metric for text generation. By harnessing both explicit human instruction and the implicit knowledge of GPT4, we fine-tune a LLAMA model to create an evaluative metric that can produce a diagnostic report aligned with human judgment. We evaluate INSTRUCTSCORE on the WMT22 Zh-En translation task, where our 7B model surpasses other LLM-based baselines, including those based on 175B GPT3. Impressively, our INSTRUCTSCORE, even without direct supervision from human-rated data, achieves performance levels on par with state-of-the-art metrics like COMET22, which was fine-tuned on human ratings.
Epsilon Sampling Rocks: Investigating Sampling Strategies for Minimum Bayes Risk Decoding for Machine Translation
May 18, 2023



Recent advances in machine translation (MT) have shown that Minimum Bayes Risk (MBR) decoding can be a powerful alternative to beam search decoding, especially when combined with neural-based utility functions. However, the performance of MBR decoding depends heavily on how and how many candidates are sampled from the model. In this paper, we explore how different sampling approaches for generating candidate lists for MBR decoding affect performance. We evaluate popular sampling approaches, such as ancestral, nucleus, and top-k sampling. Based on our insights into their limitations, we experiment with the recently proposed epsilon-sampling approach, which prunes away all tokens with a probability smaller than epsilon, ensuring that each token in a sample receives a fair probability mass. Through extensive human evaluations, we demonstrate that MBR decoding based on epsilon-sampling significantly outperforms not only beam search decoding, but also MBR decoding with all other tested sampling methods across four language pairs.
PaLM 2 Technical Report
May 17, 2023



We introduce PaLM 2, a new state-of-the-art language model that has better multilingual and reasoning capabilities and is more compute-efficient than its predecessor PaLM. PaLM 2 is a Transformer-based model trained using a mixture of objectives. Through extensive evaluations on English and multilingual language, and reasoning tasks, we demonstrate that PaLM 2 has significantly improved quality on downstream tasks across different model sizes, while simultaneously exhibiting faster and more efficient inference compared to PaLM. This improved efficiency enables broader deployment while also allowing the model to respond faster, for a more natural pace of interaction. PaLM 2 demonstrates robust reasoning capabilities exemplified by large improvements over PaLM on BIG-Bench and other reasoning tasks. PaLM 2 exhibits stable performance on a suite of responsible AI evaluations, and enables inference-time control over toxicity without additional overhead or impact on other capabilities. Overall, PaLM 2 achieves state-of-the-art performance across a diverse set of tasks and capabilities. When discussing the PaLM 2 family, it is important to distinguish between pre-trained models (of various sizes), fine-tuned variants of these models, and the user-facing products that use these models. In particular, user-facing products typically include additional pre- and post-processing steps. Additionally, the underlying models may evolve over time. Therefore, one should not expect the performance of user-facing products to exactly match the results reported in this report.