 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTranslateGemma Technical Report
Jan 15, 2026We present TranslateGemma, a suite of open machine translation models based on the Gemma 3 foundation models. To enhance the inherent multilingual capabilities of Gemma 3 for the translation task, we employ a two-stage fine-tuning process. First, supervised fine-tuning is performed using a rich mixture of high-quality large-scale synthetic parallel data generated via state-of-the-art models and human-translated parallel data. This is followed by a reinforcement learning phase, where we optimize translation quality using an ensemble of reward models, including MetricX-QE and AutoMQM, targeting translation quality. We demonstrate the effectiveness of TranslateGemma with human evaluation on the WMT25 test set across 10 language pairs and with automatic evaluation on the WMT24++ benchmark across 55 language pairs. Automatic metrics show consistent and substantial gains over the baseline Gemma 3 models across all sizes. Notably, smaller TranslateGemma models often achieve performance comparable to larger baseline models, offering improved efficiency. We also show that TranslateGemma models retain strong multimodal capabilities, with enhanced performance on the Vistra image translation benchmark. The release of the open TranslateGemma models aims to provide the research community with powerful and adaptable tools for machine translation.
Mind the Gap... or Not? How Translation Errors and Evaluation Details Skew Multilingual Results
Nov 07, 2025



Most current large language models (LLMs) support a wide variety of languages in addition to English, including high-resource languages (e.g. German, Chinese, French), as well as low-resource ones (e.g. Swahili, Telugu). In addition they have also shown impressive capabilities in different domains, like coding, science and math. In this short paper, taking math as an example domain, we study the performance of different LLMs across languages. Experimental results show that there exists a non-negligible and consistent gap in the performance of the models across languages. Interestingly, and somewhat against expectations, the gap exists for both high- and low-resource languages. We hope that these results influence further research into cross-lingual capability generalization for next generation LLMs. If it weren't for the fact that they are false! By analyzing one of the standard multilingual math benchmarks (MGSM), we determine that several translation errors are present in the data. Furthermore, the lack of standardized answer extraction from LLM outputs further influences the final results. We propose a method for automatic quality assurance to address the first issue at scale, and give recommendations to address the second one. Combining these two approaches we show that the aforementioned language gap mostly disappears, leading to completely different conclusions from our research. We additionally release the corrected dataset to the community.
You Cannot Feed Two Birds with One Score: the Accuracy-Naturalness Tradeoff in Translation
Apr 01, 2025The goal of translation, be it by human or by machine, is, given some text in a source language, to produce text in a target language that simultaneously 1) preserves the meaning of the source text and 2) achieves natural expression in the target language. However, researchers in the machine translation community usually assess translations using a single score intended to capture semantic accuracy and the naturalness of the output simultaneously. In this paper, we build on recent advances in information theory to mathematically prove and empirically demonstrate that such single-score summaries do not and cannot give the complete picture of a system's true performance. Concretely, we prove that a tradeoff exists between accuracy and naturalness and demonstrate it by evaluating the submissions to the WMT24 shared task. Our findings help explain well-known empirical phenomena, such as the observation that optimizing translation systems for a specific accuracy metric (like BLEU) initially improves the system's naturalness, while ``overfitting'' the system to the metric can significantly degrade its naturalness. Thus, we advocate for a change in how translations are evaluated: rather than comparing systems using a single number, they should be compared on an accuracy-naturalness plane.
Gemma 3 Technical Report
Mar 25, 2025We introduce Gemma 3, a multimodal addition to the Gemma family of lightweight open models, ranging in scale from 1 to 27 billion parameters. This version introduces vision understanding abilities, a wider coverage of languages and longer context - at least 128K tokens. We also change the architecture of the model to reduce the KV-cache memory that tends to explode with long context. This is achieved by increasing the ratio of local to global attention layers, and keeping the span on local attention short. The Gemma 3 models are trained with distillation and achieve superior performance to Gemma 2 for both pre-trained and instruction finetuned versions. In particular, our novel post-training recipe significantly improves the math, chat, instruction-following and multilingual abilities, making Gemma3-4B-IT competitive with Gemma2-27B-IT and Gemma3-27B-IT comparable to Gemini-1.5-Pro across benchmarks. We release all our models to the community.
There's no Data Like Better Data: Using QE Metrics for MT Data Filtering
Nov 09, 2023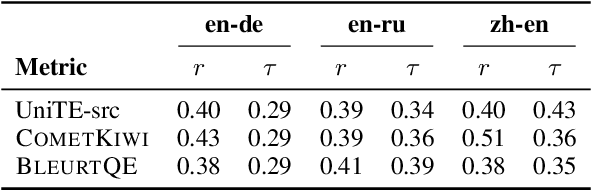
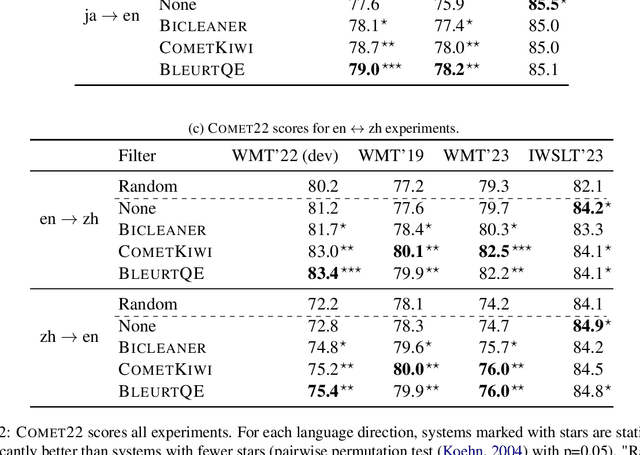
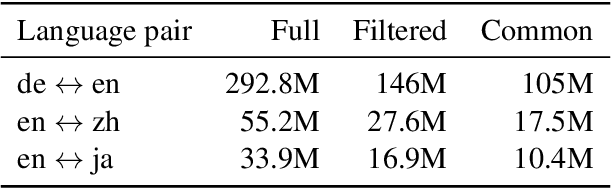

Quality Estimation (QE), the evaluation of machine translation output without the need of explicit references, has seen big improvements in the last years with the use of neural metrics. In this paper we analyze the viability of using QE metrics for filtering out bad quality sentence pairs in the training data of neural machine translation systems~(NMT). While most corpus filtering methods are focused on detecting noisy examples in collections of texts, usually huge amounts of web crawled data, QE models are trained to discriminate more fine-grained quality differences. We show that by selecting the highest quality sentence pairs in the training data, we can improve translation quality while reducing the training size by half. We also provide a detailed analysis of the filtering results, which highlights the differences between both approaches.
Guided Alignment Training for Topic-Aware Neural Machine Translation
Jul 06, 2016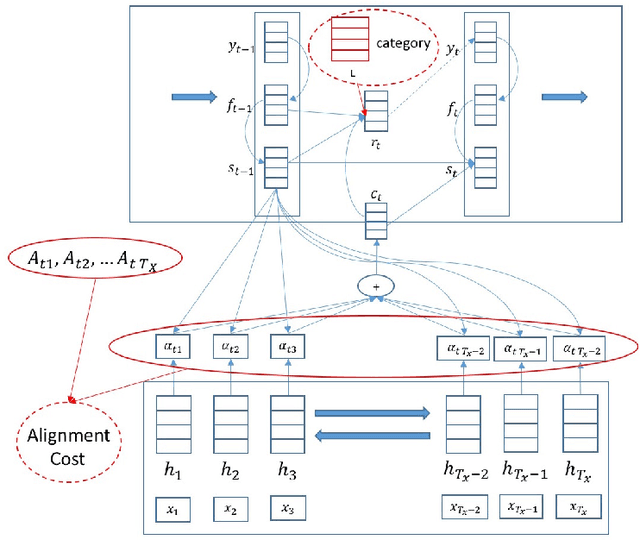
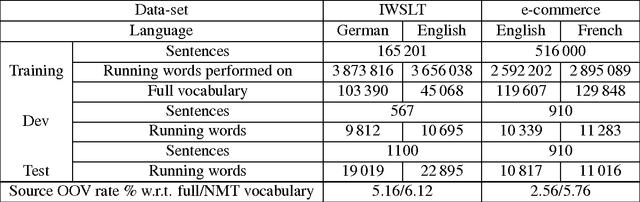
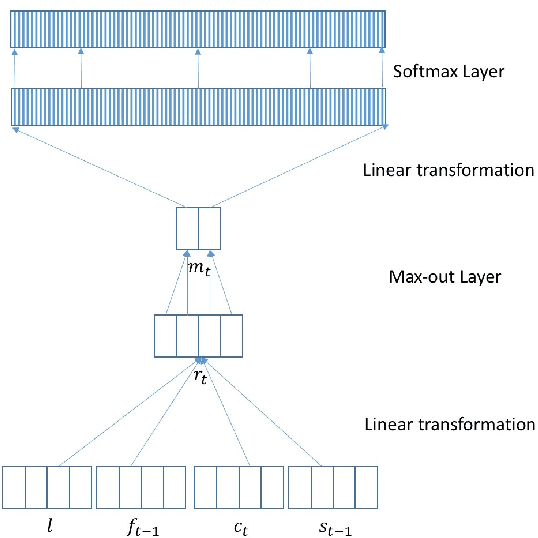
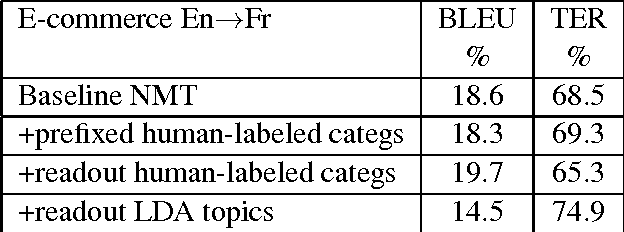
In this paper, we propose an effective way for biasing the attention mechanism of a sequence-to-sequence neural machine translation (NMT) model towards the well-studied statistical word alignment models. We show that our novel guided alignment training approach improves translation quality on real-life e-commerce texts consisting of product titles and descriptions, overcoming the problems posed by many unknown words and a large type/token ratio. We also show that meta-data associated with input texts such as topic or category information can significantly improve translation quality when used as an additional signal to the decoder part of the network. With both novel features, the BLEU score of the NMT system on a product title set improves from 18.6 to 21.3%. Even larger MT quality gains are obtained through domain adaptation of a general domain NMT system to e-commerce data. The developed NMT system also performs well on the IWSLT speech translation task, where an ensemble of four variant systems outperforms the phrase-based baseline by 2.1% BLEU absolute.