 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBinding Language Models in Symbolic Languages
Oct 06, 2022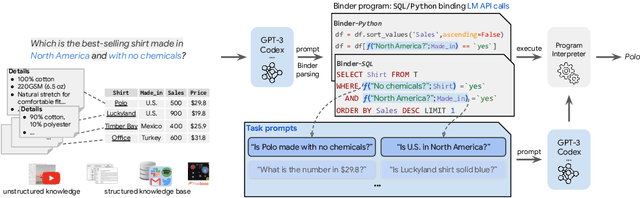
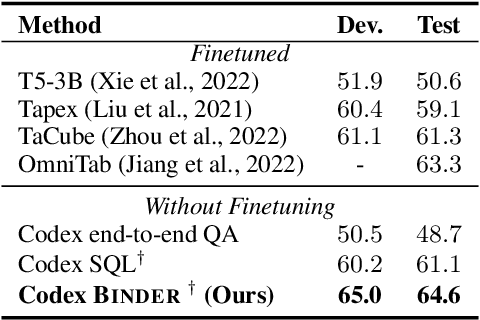

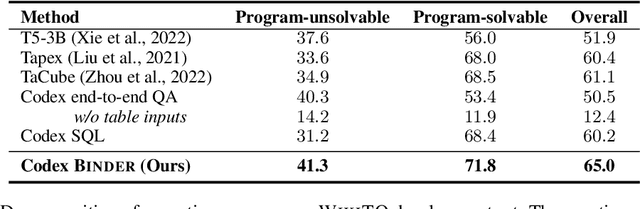
Though end-to-end neural approaches have recently been dominating NLP tasks in both performance and ease-of-use, they lack interpretability and robustness. We propose Binder, a training-free neural-symbolic framework that maps the task input to a program, which (1) allows binding a unified API of language model (LM) functionalities to a programming language (e.g., SQL, Python) to extend its grammar coverage and thus tackle more diverse questions, (2) adopts an LM as both the program parser and the underlying model called by the API during execution, and (3) requires only a few in-context exemplar annotations. Specifically, we employ GPT-3 Codex as the LM. In the parsing stage, with only a few in-context exemplars, Codex is able to identify the part of the task input that cannot be answerable by the original programming language, correctly generate API calls to prompt Codex to solve the unanswerable part, and identify where to place the API calls while being compatible with the original grammar. In the execution stage, Codex can perform versatile functionalities (e.g., commonsense QA, information extraction) given proper prompts in the API calls. Binder achieves state-of-the-art results on WikiTableQuestions and TabFact datasets, with explicit output programs that benefit human debugging. Note that previous best systems are all finetuned on tens of thousands of task-specific samples, while Binder only uses dozens of annotations as in-context exemplars without any training. Our code is available at https://github.com/HKUNLP/Binder .
Selective Annotation Makes Language Models Better Few-Shot Learners
Sep 05, 2022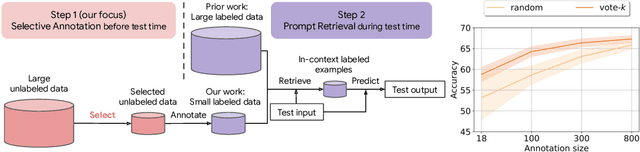
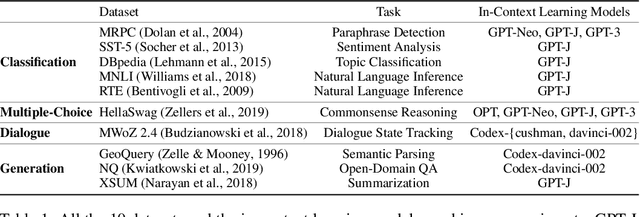
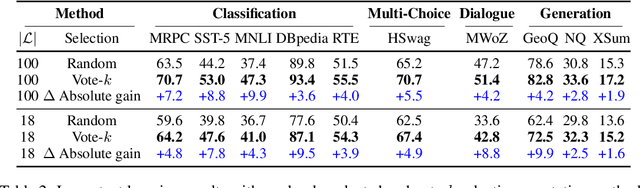
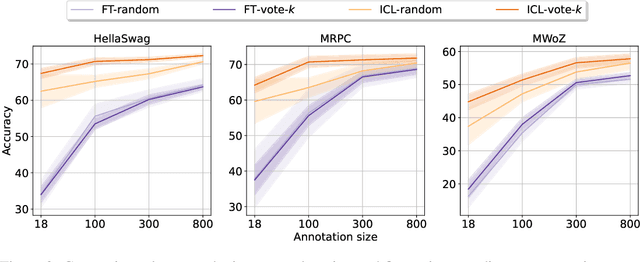
Many recent approaches to natural language tasks are built on the remarkable abilities of large language models. Large language models can perform in-context learning, where they learn a new task from a few task demonstrations, without any parameter updates. This work examines the implications of in-context learning for the creation of datasets for new natural language tasks. Departing from recent in-context learning methods, we formulate an annotation-efficient, two-step framework: selective annotation that chooses a pool of examples to annotate from unlabeled data in advance, followed by prompt retrieval that retrieves task examples from the annotated pool at test time. Based on this framework, we propose an unsupervised, graph-based selective annotation method, voke-k, to select diverse, representative examples to annotate. Extensive experiments on 10 datasets (covering classification, commonsense reasoning, dialogue, and text/code generation) demonstrate that our selective annotation method improves the task performance by a large margin. On average, vote-k achieves a 12.9%/11.4% relative gain under an annotation budget of 18/100, as compared to randomly selecting examples to annotate. Compared to state-of-the-art supervised finetuning approaches, it yields similar performance with 10-100x less annotation cost across 10 tasks. We further analyze the effectiveness of our framework in various scenarios: language models with varying sizes, alternative selective annotation methods, and cases where there is a test data domain shift. We hope that our studies will serve as a basis for data annotations as large language models are increasingly applied to new tasks. Our code is available at https://github.com/HKUNLP/icl-selective-annotation.
INSCIT: Information-Seeking Conversations with Mixed-Initiative Interactions
Jul 02, 2022

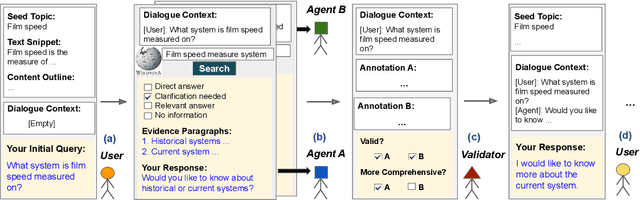
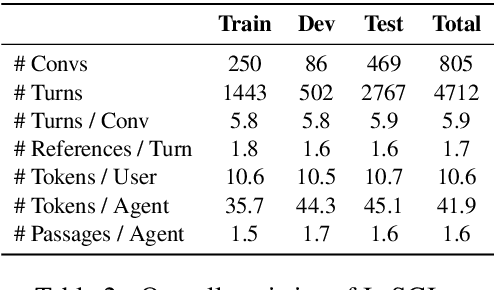
In an information-seeking conversation, a user converses with an agent to ask a series of questions that can often be under- or over-specified. An ideal agent would first identify that they were in such a situation by searching through their underlying knowledge source and then appropriately interacting with a user to resolve it. However, most existing studies either fail to or artificially incorporate such agent-side initiatives. In this work, we present INSCIT (pronounced Insight), a dataset for information-seeking conversations with mixed-initiative interactions. It contains a total of 4.7K user-agent turns from 805 human-human conversations where the agent searches over Wikipedia and either asks for clarification or provides relevant information to address user queries. We define two subtasks, namely evidence passage identification and response generation, as well as a new human evaluation protocol to assess the model performance. We report results of two strong baselines based on state-of-the-art models of conversational knowledge identification and open-domain question answering. Both models significantly underperform humans and fail to generate coherent and informative responses, suggesting ample room for improvement in future studies.
Unsupervised Learning of Hierarchical Conversation Structure
May 24, 2022



Human conversations can evolve in many different ways, creating challenges for automatic understanding and summarization. Goal-oriented conversations often have meaningful sub-dialogue structure, but it can be highly domain-dependent. This work introduces an unsupervised approach to learning hierarchical conversation structure, including turn and sub-dialogue segment labels, corresponding roughly to dialogue acts and sub-tasks, respectively. The decoded structure is shown to be useful in enhancing neural models of language for three conversation-level understanding tasks. Further, the learned finite-state sub-dialogue network is made interpretable through automatic summarization. Our code and trained models are available at \url{https://github.com/boru-roylu/THETA}.
Automatic Dialect Density Estimation for African American English
Apr 03, 2022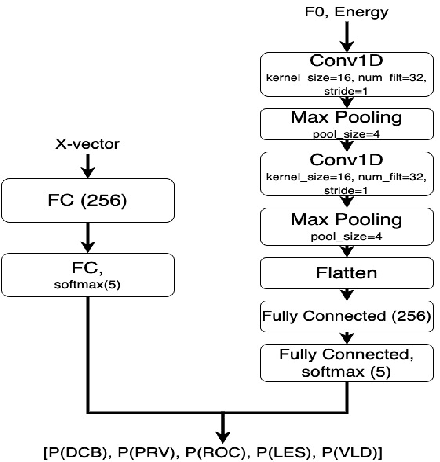
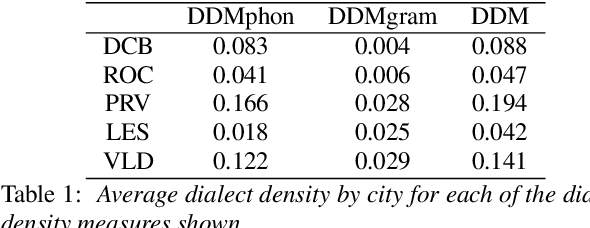
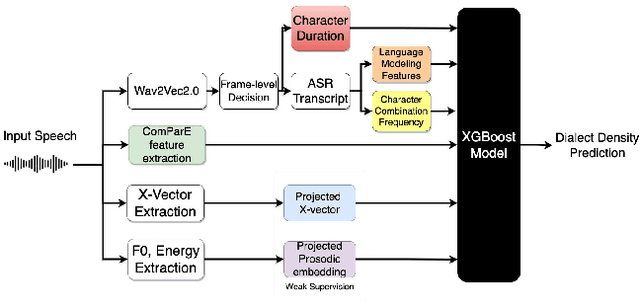
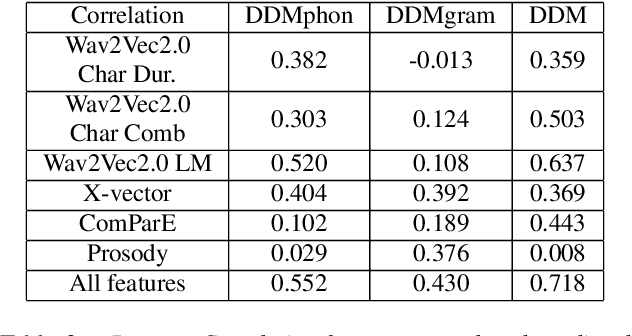
In this paper, we explore automatic prediction of dialect density of the African American English (AAE) dialect, where dialect density is defined as the percentage of words in an utterance that contain characteristics of the non-standard dialect. We investigate several acoustic and language modeling features, including the commonly used X-vector representation and ComParE feature set, in addition to information extracted from ASR transcripts of the audio files and prosodic information. To address issues of limited labeled data, we use a weakly supervised model to project prosodic and X-vector features into low-dimensional task-relevant representations. An XGBoost model is then used to predict the speaker's dialect density from these features and show which are most significant during inference. We evaluate the utility of these features both alone and in combination for the given task. This work, which does not rely on hand-labeled transcripts, is performed on audio segments from the CORAAL database. We show a significant correlation between our predicted and ground truth dialect density measures for AAE speech in this database and propose this work as a tool for explaining and mitigating bias in speech technology.
* 5 pages, 2 figures
In-Context Learning for Few-Shot Dialogue State Tracking
Mar 16, 2022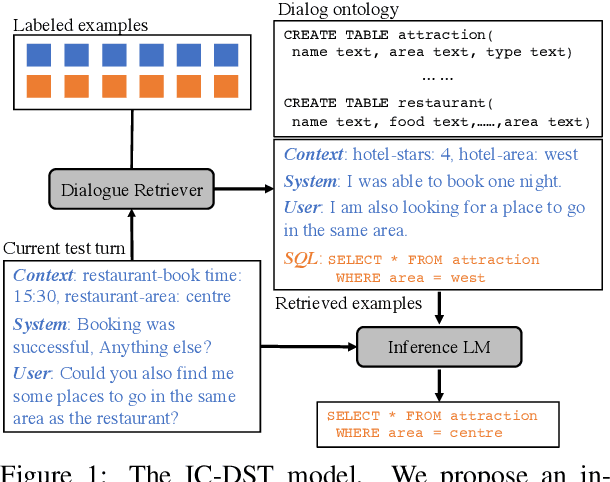
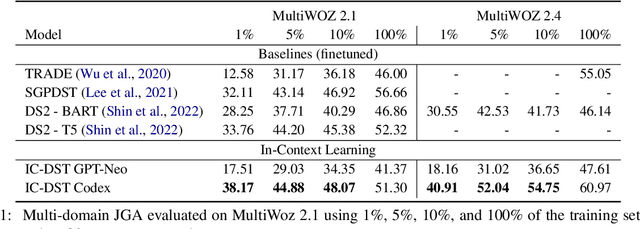
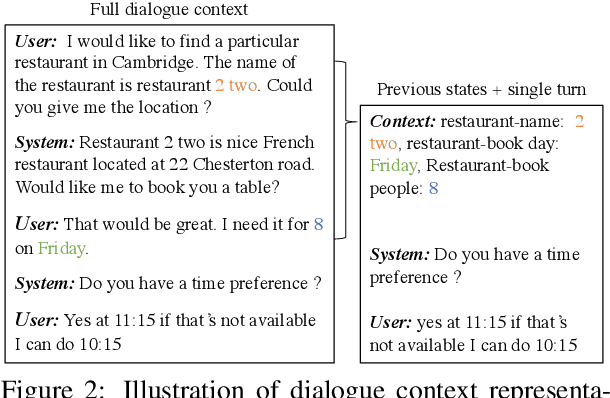
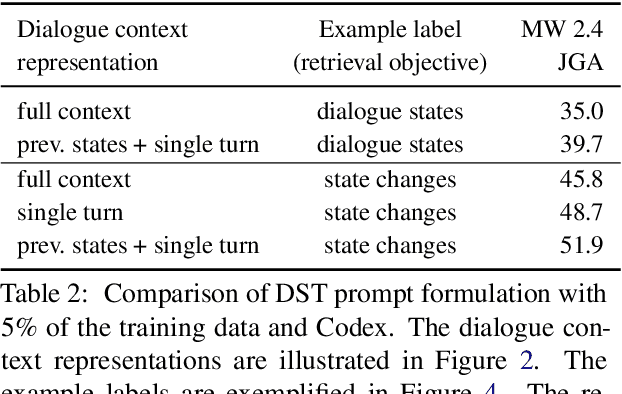
Collecting and annotating task-oriented dialogues is time-consuming and costly. Thus, few-shot learning for dialogue tasks presents an exciting opportunity. In this work, we propose an in-context (IC) learning framework for few-shot dialogue state tracking (DST), where a large pre-trained language model (LM) takes a test instance and a few annotated examples as input, and directly decodes the dialogue states without any parameter updates. This makes the LM more flexible and scalable compared to prior few-shot DST work when adapting to new domains and scenarios. We study ways to formulate dialogue context into prompts for LMs and propose an efficient approach to retrieve dialogues as exemplars given a test instance and a selection pool of few-shot examples. To better leverage the pre-trained LMs, we also reformulate DST into a text-to-SQL problem. Empirical results on MultiWOZ 2.1 and 2.4 show that our method IC-DST outperforms previous fine-tuned state-of-the-art models in few-shot settings.
Dialogue State Tracking with a Language Model using Schema-Driven Prompting
Sep 15, 2021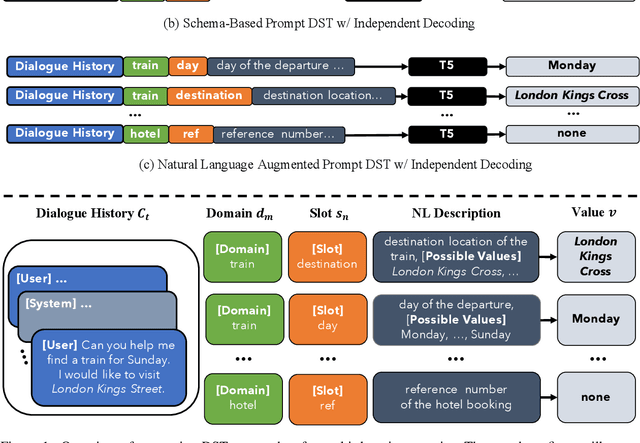
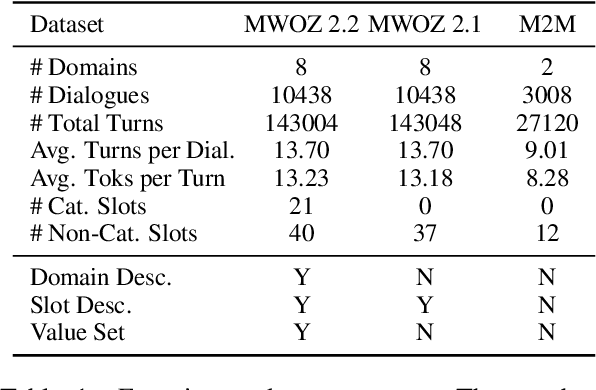
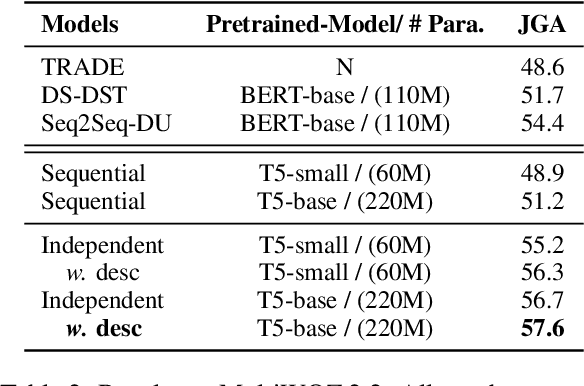
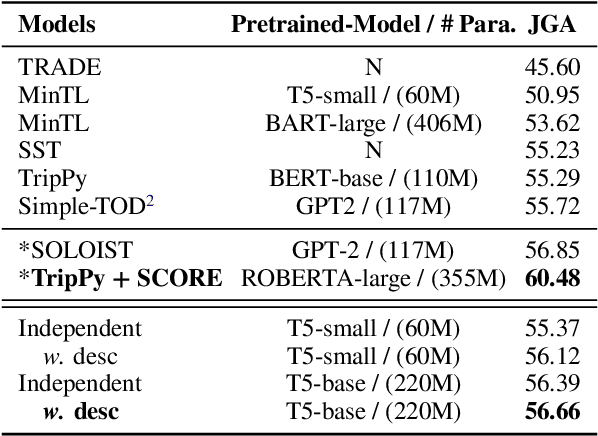
Task-oriented conversational systems often use dialogue state tracking to represent the user's intentions, which involves filling in values of pre-defined slots. Many approaches have been proposed, often using task-specific architectures with special-purpose classifiers. Recently, good results have been obtained using more general architectures based on pretrained language models. Here, we introduce a new variation of the language modeling approach that uses schema-driven prompting to provide task-aware history encoding that is used for both categorical and non-categorical slots. We further improve performance by augmenting the prompting with schema descriptions, a naturally occurring source of in-domain knowledge. Our purely generative system achieves state-of-the-art performance on MultiWOZ 2.2 and achieves competitive performance on two other benchmarks: MultiWOZ 2.1 and M2M. The data and code will be available at https://github.com/chiahsuan156/DST-as-Prompting.
DIALKI: Knowledge Identification in Conversational Systems through Dialogue-Document Contextualization
Sep 10, 2021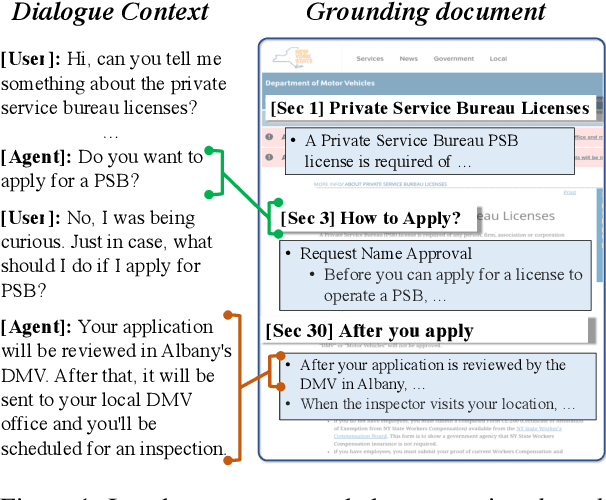

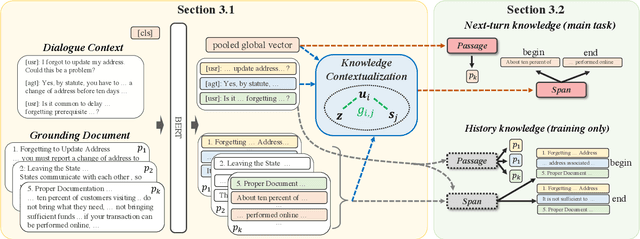
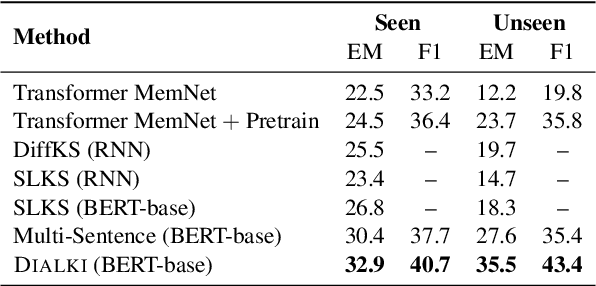
Identifying relevant knowledge to be used in conversational systems that are grounded in long documents is critical to effective response generation. We introduce a knowledge identification model that leverages the document structure to provide dialogue-contextualized passage encodings and better locate knowledge relevant to the conversation. An auxiliary loss captures the history of dialogue-document connections. We demonstrate the effectiveness of our model on two document-grounded conversational datasets and provide analyses showing generalization to unseen documents and long dialogue contexts.
Assessing the Use of Prosody in Constituency Parsing of Imperfect Transcripts
Jun 14, 2021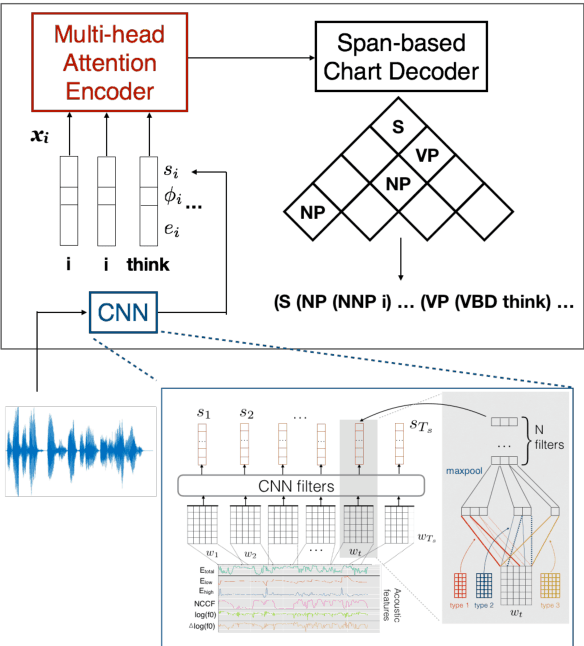
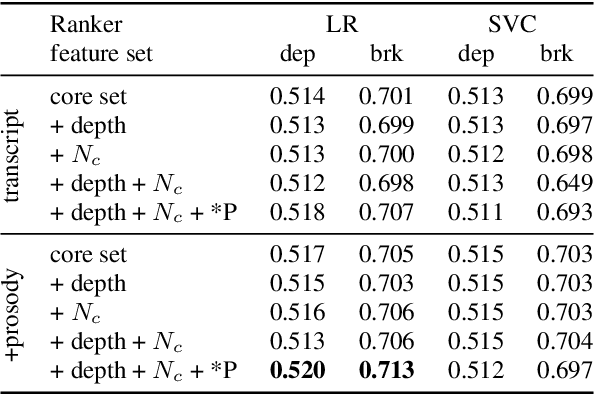
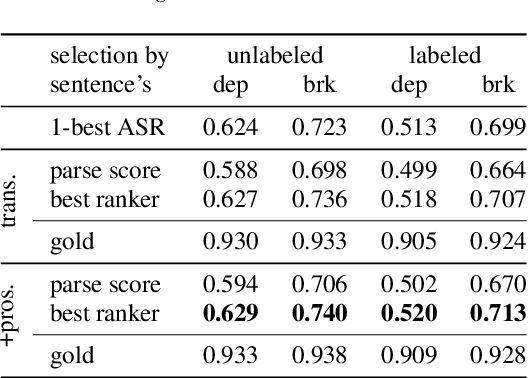
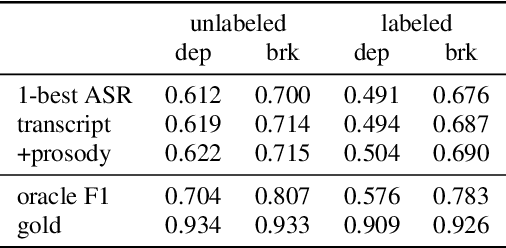
This work explores constituency parsing on automatically recognized transcripts of conversational speech. The neural parser is based on a sentence encoder that leverages word vectors contextualized with prosodic features, jointly learning prosodic feature extraction with parsing. We assess the utility of the prosody in parsing on imperfect transcripts, i.e. transcripts with automatic speech recognition (ASR) errors, by applying the parser in an N-best reranking framework. In experiments on Switchboard, we obtain 13-15% of the oracle N-best gain relative to parsing the 1-best ASR output, with insignificant impact on word recognition error rate. Prosody provides a significant part of the gain, and analyses suggest that it leads to more grammatical utterances via recovering function words.
Representations for Question Answering from Documents with Tables and Text
Jan 26, 2021
Tables in Web documents are pervasive and can be directly used to answer many of the queries searched on the Web, motivating their integration in question answering. Very often information presented in tables is succinct and hard to interpret with standard language representations. On the other hand, tables often appear within textual context, such as an article describing the table. Using the information from an article as additional context can potentially enrich table representations. In this work we aim to improve question answering from tables by refining table representations based on information from surrounding text. We also present an effective method to combine text and table-based predictions for question answering from full documents, obtaining significant improvements on the Natural Questions dataset.