 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMVPbev: Multi-view Perspective Image Generation from BEV with Test-time Controllability and Generalizability
Jul 28, 2024



This work aims to address the multi-view perspective RGB generation from text prompts given Bird-Eye-View(BEV) semantics. Unlike prior methods that neglect layout consistency, lack the ability to handle detailed text prompts, or are incapable of generalizing to unseen view points, MVPbev simultaneously generates cross-view consistent images of different perspective views with a two-stage design, allowing object-level control and novel view generation at test-time. Specifically, MVPbev firstly projects given BEV semantics to perspective view with camera parameters, empowering the model to generalize to unseen view points. Then we introduce a multi-view attention module where special initialization and de-noising processes are introduced to explicitly enforce local consistency among overlapping views w.r.t. cross-view homography. Last but not least, MVPbev further allows test-time instance-level controllability by refining a pre-trained text-to-image diffusion model. Our extensive experiments on NuScenes demonstrate that our method is capable of generating high-resolution photorealistic images from text descriptions with thousands of training samples, surpassing the state-of-the-art methods under various evaluation metrics. We further demonstrate the advances of our method in terms of generalizability and controllability with the help of novel evaluation metrics and comprehensive human analysis. Our code, data, and model can be found in \url{https://github.com/kkaiwwana/MVPbev}.
LidaRF: Delving into Lidar for Neural Radiance Field on Street Scenes
May 04, 2024Photorealistic simulation plays a crucial role in applications such as autonomous driving, where advances in neural radiance fields (NeRFs) may allow better scalability through the automatic creation of digital 3D assets. However, reconstruction quality suffers on street scenes due to largely collinear camera motions and sparser samplings at higher speeds. On the other hand, the application often demands rendering from camera views that deviate from the inputs to accurately simulate behaviors like lane changes. In this paper, we propose several insights that allow a better utilization of Lidar data to improve NeRF quality on street scenes. First, our framework learns a geometric scene representation from Lidar, which is fused with the implicit grid-based representation for radiance decoding, thereby supplying stronger geometric information offered by explicit point cloud. Second, we put forth a robust occlusion-aware depth supervision scheme, which allows utilizing densified Lidar points by accumulation. Third, we generate augmented training views from Lidar points for further improvement. Our insights translate to largely improved novel view synthesis under real driving scenes.
DiL-NeRF: Delving into Lidar for Neural Radiance Field on Street Scenes
May 01, 2024Photorealistic simulation plays a crucial role in applications such as autonomous driving, where advances in neural radiance fields (NeRFs) may allow better scalability through the automatic creation of digital 3D assets. However, reconstruction quality suffers on street scenes due to largely collinear camera motions and sparser samplings at higher speeds. On the other hand, the application often demands rendering from camera views that deviate from the inputs to accurately simulate behaviors like lane changes. In this paper, we propose several insights that allow a better utilization of Lidar data to improve NeRF quality on street scenes. First, our framework learns a geometric scene representation from Lidar, which is fused with the implicit grid-based representation for radiance decoding, thereby supplying stronger geometric information offered by explicit point cloud. Second, we put forth a robust occlusion-aware depth supervision scheme, which allows utilizing densified Lidar points by accumulation. Third, we generate augmented training views from Lidar points for further improvement. Our insights translate to largely improved novel view synthesis under real driving scenes.
NeurOCS: Neural NOCS Supervision for Monocular 3D Object Localization
May 28, 2023Monocular 3D object localization in driving scenes is a crucial task, but challenging due to its ill-posed nature. Estimating 3D coordinates for each pixel on the object surface holds great potential as it provides dense 2D-3D geometric constraints for the underlying PnP problem. However, high-quality ground truth supervision is not available in driving scenes due to sparsity and various artifacts of Lidar data, as well as the practical infeasibility of collecting per-instance CAD models. In this work, we present NeurOCS, a framework that uses instance masks and 3D boxes as input to learn 3D object shapes by means of differentiable rendering, which further serves as supervision for learning dense object coordinates. Our approach rests on insights in learning a category-level shape prior directly from real driving scenes, while properly handling single-view ambiguities. Furthermore, we study and make critical design choices to learn object coordinates more effectively from an object-centric view. Altogether, our framework leads to new state-of-the-art in monocular 3D localization that ranks 1st on the KITTI-Object benchmark among published monocular methods.
GLOW: Global Layout Aware Attacks on Object Detection
Mar 08, 2023



Adversarial attacks aim to perturb images such that a predictor outputs incorrect results. Due to the limited research in structured attacks, imposing consistency checks on natural multi-object scenes is a promising yet practical defense against conventional adversarial attacks. More desired attacks, to this end, should be able to fool defenses with such consistency checks. Therefore, we present the first approach GLOW that copes with various attack requests by generating global layout-aware adversarial attacks, in which both categorical and geometric layout constraints are explicitly established. Specifically, we focus on object detection task and given a victim image, GLOW first localizes victim objects according to target labels. And then it generates multiple attack plans, together with their context-consistency scores. Our proposed GLOW, on the one hand, is capable of handling various types of requests, including single or multiple victim objects, with or without specified victim objects. On the other hand, it produces a consistency score for each attack plan, reflecting the overall contextual consistency that both semantic category and global scene layout are considered. In experiment, we design multiple types of attack requests and validate our ideas on MS COCO and Pascal. Extensive experimental results demonstrate that we can achieve about 30$\%$ average relative improvement compared to state-of-the-art methods in conventional single object attack request; Moreover, our method outperforms SOTAs significantly on more generic attack requests by about 20$\%$ in average; Finally, our method produces superior performance under challenging zero-query black-box setting, or 20$\%$ better than SOTAs. Our code, model and attack requests would be made available.
MM-TTA: Multi-Modal Test-Time Adaptation for 3D Semantic Segmentation
Apr 27, 2022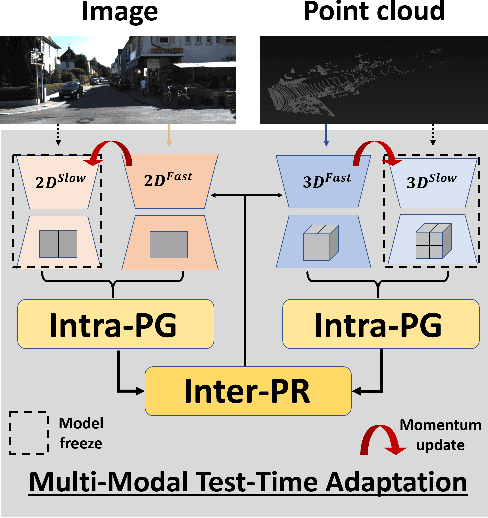
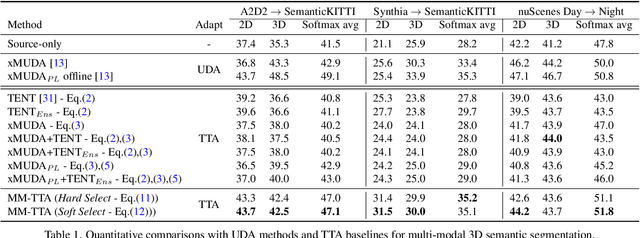
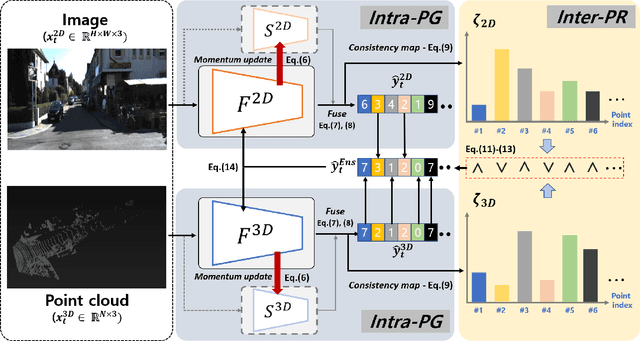
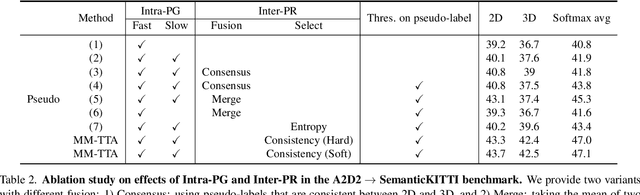
Test-time adaptation approaches have recently emerged as a practical solution for handling domain shift without access to the source domain data. In this paper, we propose and explore a new multi-modal extension of test-time adaptation for 3D semantic segmentation. We find that directly applying existing methods usually results in performance instability at test time because multi-modal input is not considered jointly. To design a framework that can take full advantage of multi-modality, where each modality provides regularized self-supervisory signals to other modalities, we propose two complementary modules within and across the modalities. First, Intra-modal Pseudolabel Generation (Intra-PG) is introduced to obtain reliable pseudo labels within each modality by aggregating information from two models that are both pre-trained on source data but updated with target data at different paces. Second, Inter-modal Pseudo-label Refinement (Inter-PR) adaptively selects more reliable pseudo labels from different modalities based on a proposed consistency scheme. Experiments demonstrate that our regularized pseudo labels produce stable self-learning signals in numerous multi-modal test-time adaptation scenarios for 3D semantic segmentation. Visit our project website at https://www.nec-labs.com/~mas/MM-TTA.
The Story in Your Eyes: An Individual-difference-aware Model for Cross-person Gaze Estimation
Jun 27, 2021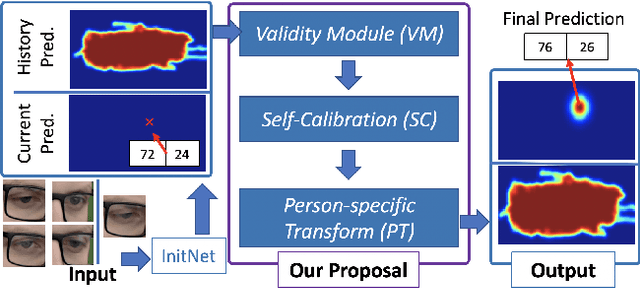

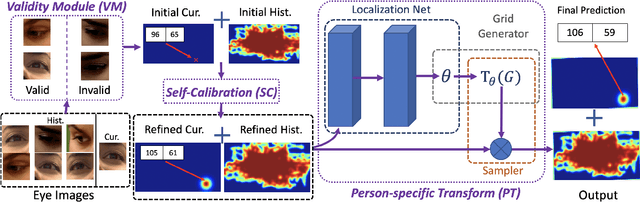
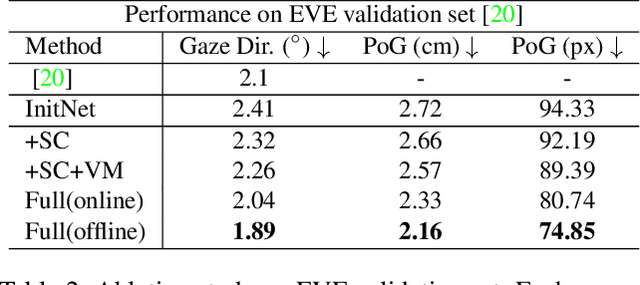
We propose a novel method on refining cross-person gaze prediction task with eye/face images only by explicitly modelling the person-specific differences. Specifically, we first assume that we can obtain some initial gaze prediction results with existing method, which we refer to as InitNet, and then introduce three modules, the Validity Module (VM), Self-Calibration (SC) and Person-specific Transform (PT)) Module. By predicting the reliability of current eye/face images, our VM is able to identify invalid samples, e.g. eye blinking images, and reduce their effects in our modelling process. Our SC and PT module then learn to compensate for the differences on valid samples only. The former models the translation offsets by bridging the gap between initial predictions and dataset-wise distribution. And the later learns more general person-specific transformation by incorporating the information from existing initial predictions of the same person. We validate our ideas on three publicly available datasets, EVE, XGaze and MPIIGaze and demonstrate that our proposed method outperforms the SOTA methods significantly on all of them, e.g. respectively 21.7%, 36.0% and 32.9% relative performance improvements. We won the GAZE 2021 Competition on the EVE dataset. Our code can be found here https://github.com/bjj9/EVE_SCPT.
Divide-and-Conquer for Lane-Aware Diverse Trajectory Prediction
Apr 16, 2021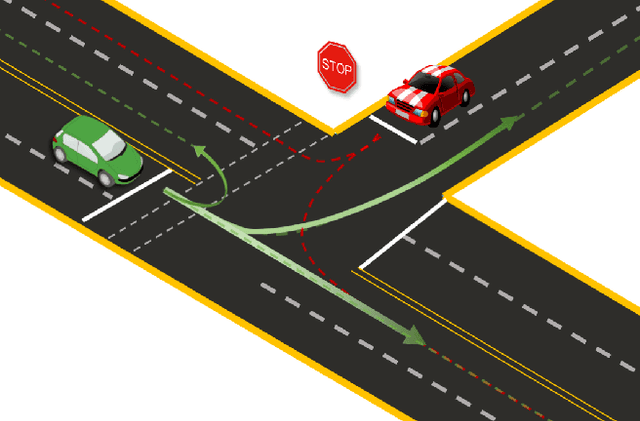
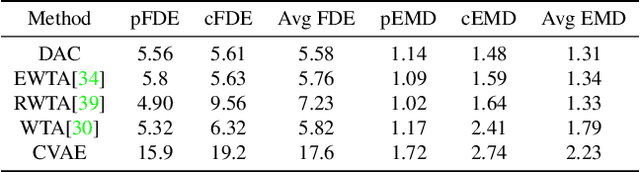

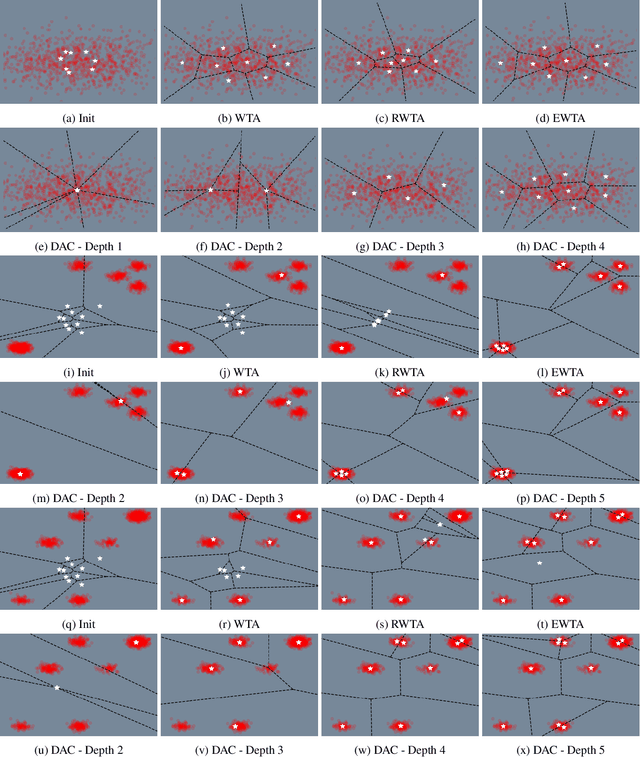
Trajectory prediction is a safety-critical tool for autonomous vehicles to plan and execute actions. Our work addresses two key challenges in trajectory prediction, learning multimodal outputs, and better predictions by imposing constraints using driving knowledge. Recent methods have achieved strong performances using Multi-Choice Learning objectives like winner-takes-all (WTA) or best-of-many. But the impact of those methods in learning diverse hypotheses is under-studied as such objectives highly depend on their initialization for diversity. As our first contribution, we propose a novel Divide-And-Conquer (DAC) approach that acts as a better initialization technique to WTA objective, resulting in diverse outputs without any spurious modes. Our second contribution is a novel trajectory prediction framework called ALAN that uses existing lane centerlines as anchors to provide trajectories constrained to the input lanes. Our framework provides multi-agent trajectory outputs in a forward pass by capturing interactions through hypercolumn descriptors and incorporating scene information in the form of rasterized images and per-agent lane anchors. Experiments on synthetic and real data show that the proposed DAC captures the data distribution better compare to other WTA family of objectives. Further, we show that our ALAN approach provides on par or better performance with SOTA methods evaluated on Nuscenes urban driving benchmark.
Weakly But Deeply Supervised Occlusion-Reasoned Parametric Layouts
Apr 14, 2021



We propose an end-to-end network that takes a single perspective RGB image of a complex road scene as input, to produce occlusion-reasoned layouts in perspective space as well as a top-view parametric space. In contrast to prior works that require dense supervision such as semantic labels in perspective view, the only human annotations required by our method are for parametric attributes that are cheaper and less ambiguous to obtain. To solve this challenging task, our design is comprised of modules that incorporate inductive biases to learn occlusion-reasoning, geometric transformation and semantic abstraction, where each module may be supervised by appropriately transforming the parametric annotations. We demonstrate how our design choices and proposed deep supervision help achieve accurate predictions and meaningful representations. We validate our approach on two public datasets, KITTI and NuScenes, to achieve state-of-the-art results with considerably lower human supervision.
Uncertainty-Aware Physically-Guided Proxy Tasks for Unseen Domain Face Anti-spoofing
Nov 28, 2020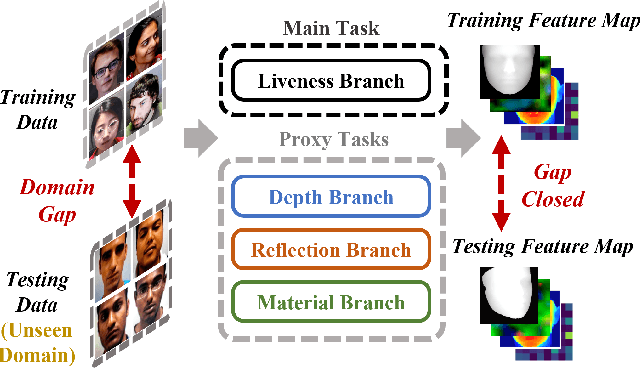



Face anti-spoofing (FAS) seeks to discriminate genuine faces from fake ones arising from any type of spoofing attack. Due to the wide varieties of attacks, it is implausible to obtain training data that spans all attack types. We propose to leverage physical cues to attain better generalization on unseen domains. As a specific demonstration, we use physically guided proxy cues such as depth, reflection, and material to complement our main anti-spoofing (a.k.a liveness detection) task, with the intuition that genuine faces across domains have consistent face-like geometry, minimal reflection, and skin material. We introduce a novel uncertainty-aware attention scheme that independently learns to weigh the relative contributions of the main and proxy tasks, preventing the over-confident issue with traditional attention modules. Further, we propose attribute-assisted hard negative mining to disentangle liveness-irrelevant features with liveness features during learning. We evaluate extensively on public benchmarks with intra-dataset and inter-dataset protocols. Our method achieves the superior performance especially in unseen domain generalization for FAS.