 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond the Imitation Game: Quantifying and extrapolating the capabilities of language models
Jun 10, 2022Language models demonstrate both quantitative improvement and new qualitative capabilities with increasing scale. Despite their potentially transformative impact, these new capabilities are as yet poorly characterized. In order to inform future research, prepare for disruptive new model capabilities, and ameliorate socially harmful effects, it is vital that we understand the present and near-future capabilities and limitations of language models. To address this challenge, we introduce the Beyond the Imitation Game benchmark (BIG-bench). BIG-bench currently consists of 204 tasks, contributed by 442 authors across 132 institutions. Task topics are diverse, drawing problems from linguistics, childhood development, math, common-sense reasoning, biology, physics, social bias, software development, and beyond. BIG-bench focuses on tasks that are believed to be beyond the capabilities of current language models. We evaluate the behavior of OpenAI's GPT models, Google-internal dense transformer architectures, and Switch-style sparse transformers on BIG-bench, across model sizes spanning millions to hundreds of billions of parameters. In addition, a team of human expert raters performed all tasks in order to provide a strong baseline. Findings include: model performance and calibration both improve with scale, but are poor in absolute terms (and when compared with rater performance); performance is remarkably similar across model classes, though with benefits from sparsity; tasks that improve gradually and predictably commonly involve a large knowledge or memorization component, whereas tasks that exhibit "breakthrough" behavior at a critical scale often involve multiple steps or components, or brittle metrics; social bias typically increases with scale in settings with ambiguous context, but this can be improved with prompting.
Revisiting the Boundary between ASR and NLU in the Age of Conversational Dialog Systems
Dec 10, 2021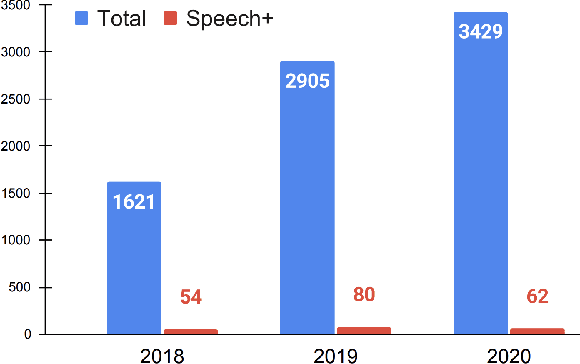

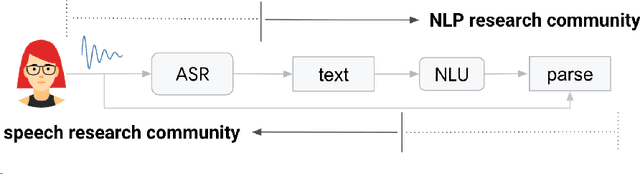
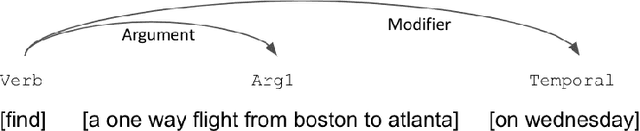
As more users across the world are interacting with dialog agents in their daily life, there is a need for better speech understanding that calls for renewed attention to the dynamics between research in automatic speech recognition (ASR) and natural language understanding (NLU). We briefly review these research areas and lay out the current relationship between them. In light of the observations we make in this paper, we argue that (1) NLU should be cognizant of the presence of ASR models being used upstream in a dialog system's pipeline, (2) ASR should be able to learn from errors found in NLU, (3) there is a need for end-to-end datasets that provide semantic annotations on spoken input, (4) there should be stronger collaboration between ASR and NLU research communities.
TIMEDIAL: Temporal Commonsense Reasoning in Dialog
Jun 08, 2021
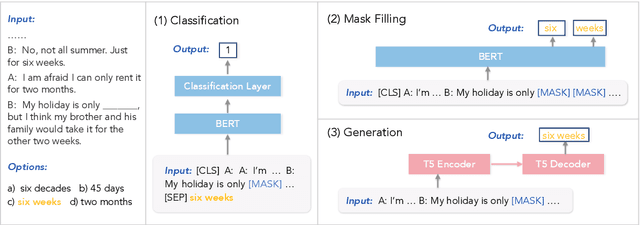

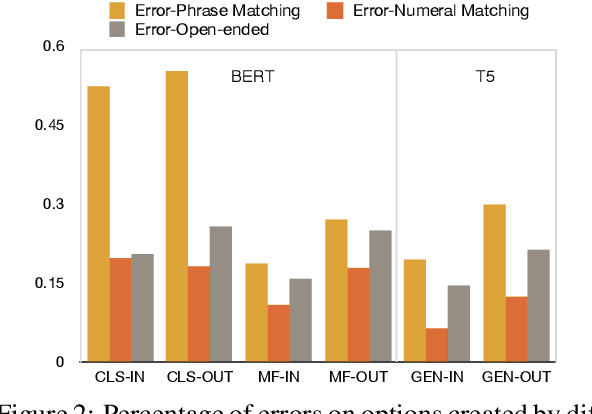
Everyday conversations require understanding everyday events, which in turn, requires understanding temporal commonsense concepts interwoven with those events. Despite recent progress with massive pre-trained language models (LMs) such as T5 and GPT-3, their capability of temporal reasoning in dialogs remains largely under-explored. In this paper, we present the first study to investigate pre-trained LMs for their temporal reasoning capabilities in dialogs by introducing a new task and a crowd-sourced English challenge set, TIMEDIAL. We formulate TIME-DIAL as a multiple-choice cloze task with over 1.1K carefully curated dialogs. Empirical results demonstrate that even the best performing models struggle on this task compared to humans, with 23 absolute points of gap in accuracy. Furthermore, our analysis reveals that the models fail to reason about dialog context correctly; instead, they rely on shallow cues based on existing temporal patterns in context, motivating future research for modeling temporal concepts in text and robust contextual reasoning about them. The dataset is publicly available at: https://github.com/google-research-datasets/timedial.
Disfl-QA: A Benchmark Dataset for Understanding Disfluencies in Question Answering
Jun 08, 2021
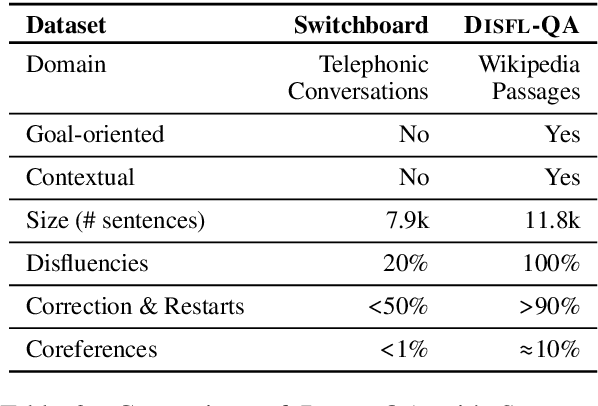


Disfluencies is an under-studied topic in NLP, even though it is ubiquitous in human conversation. This is largely due to the lack of datasets containing disfluencies. In this paper, we present a new challenge question answering dataset, Disfl-QA, a derivative of SQuAD, where humans introduce contextual disfluencies in previously fluent questions. Disfl-QA contains a variety of challenging disfluencies that require a more comprehensive understanding of the text than what was necessary in prior datasets. Experiments show that the performance of existing state-of-the-art question answering models degrades significantly when tested on Disfl-QA in a zero-shot setting.We show data augmentation methods partially recover the loss in performance and also demonstrate the efficacy of using gold data for fine-tuning. We argue that we need large-scale disfluency datasets in order for NLP models to be robust to them. The dataset is publicly available at: https://github.com/google-research-datasets/disfl-qa.
ToTTo: A Controlled Table-To-Text Generation Dataset
Apr 30, 2020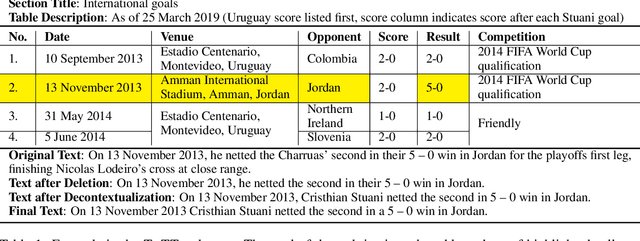

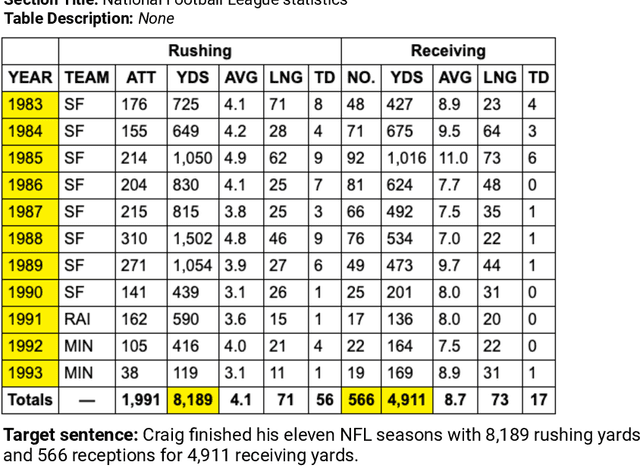
We present ToTTo, an open-domain English table-to-text dataset with over 120,000 training examples that proposes a controlled generation task: given a Wikipedia table and a set of highlighted table cells, produce a one-sentence description. To obtain generated targets that are natural but also faithful to the source table, we introduce a dataset construction process where annotators directly revise existing candidate sentences from Wikipedia. We present systematic analyses of our dataset and annotation process as well as results achieved by several state-of-the-art baselines. While usually fluent, existing methods often hallucinate phrases that are not supported by the table, suggesting that this dataset can serve as a useful research benchmark for high-precision conditional text generation.
How to Ask Better Questions? A Large-Scale Multi-Domain Dataset for Rewriting Ill-Formed Questions
Nov 21, 2019
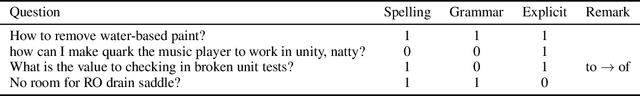


We present a large-scale dataset for the task of rewriting an ill-formed natural language question to a well-formed one. Our multi-domain question rewriting MQR dataset is constructed from human contributed Stack Exchange question edit histories. The dataset contains 427,719 question pairs which come from 303 domains. We provide human annotations for a subset of the dataset as a quality estimate. When moving from ill-formed to well-formed questions, the question quality improves by an average of 45 points across three aspects. We train sequence-to-sequence neural models on the constructed dataset and obtain an improvement of 13.2% in BLEU-4 over baseline methods built from other data resources. We release the MQR dataset to encourage research on the problem of question rewriting.
Attention Interpretability Across NLP Tasks
Sep 24, 2019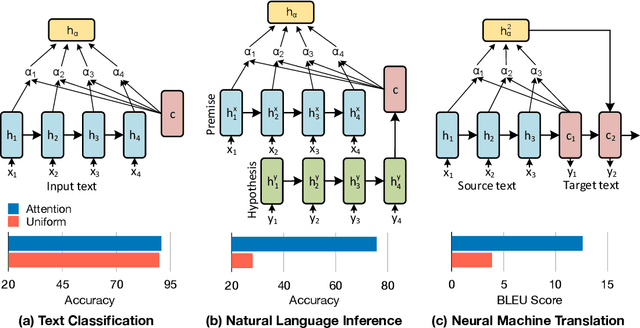
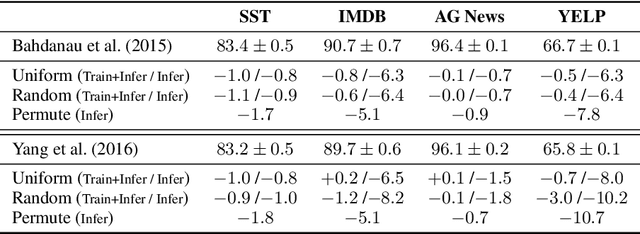
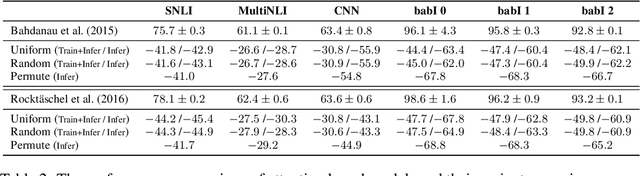
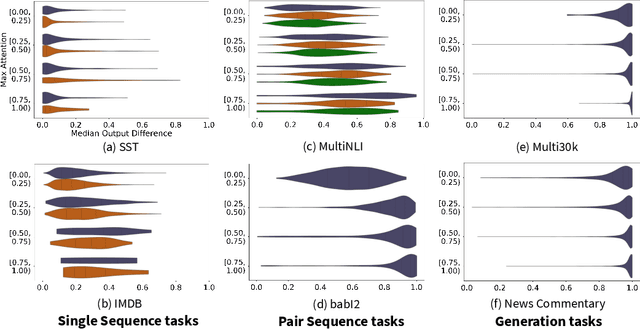
The attention layer in a neural network model provides insights into the model's reasoning behind its prediction, which are usually criticized for being opaque. Recently, seemingly contradictory viewpoints have emerged about the interpretability of attention weights (Jain & Wallace, 2019; Vig & Belinkov, 2019). Amid such confusion arises the need to understand attention mechanism more systematically. In this work, we attempt to fill this gap by giving a comprehensive explanation which justifies both kinds of observations (i.e., when is attention interpretable and when it is not). Through a series of experiments on diverse NLP tasks, we validate our observations and reinforce our claim of interpretability of attention through manual evaluation.
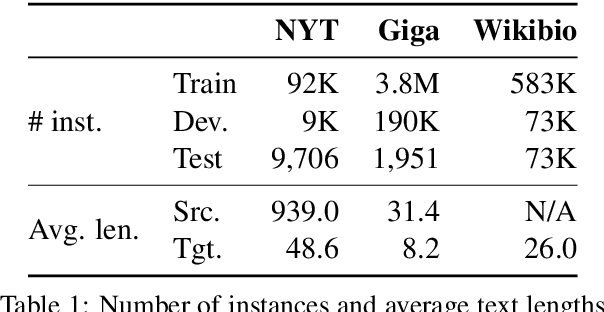
Handling Divergent Reference Texts when Evaluating Table-to-Text Generation
Jun 03, 2019


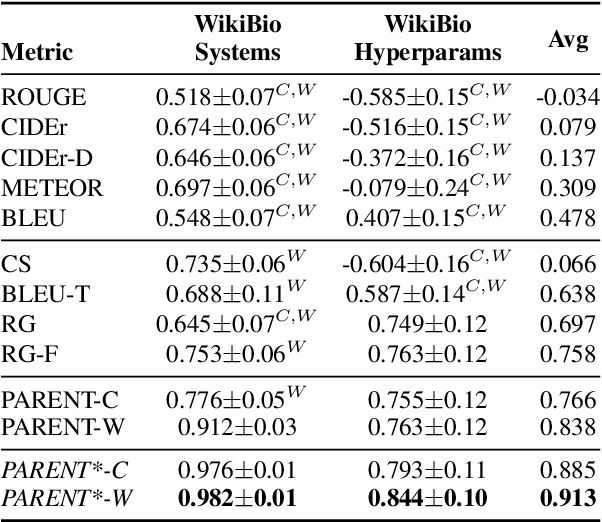
Automatically constructed datasets for generating text from semi-structured data (tables), such as WikiBio, often contain reference texts that diverge from the information in the corresponding semi-structured data. We show that metrics which rely solely on the reference texts, such as BLEU and ROUGE, show poor correlation with human judgments when those references diverge. We propose a new metric, PARENT, which aligns n-grams from the reference and generated texts to the semi-structured data before computing their precision and recall. Through a large scale human evaluation study of table-to-text models for WikiBio, we show that PARENT correlates with human judgments better than existing text generation metrics. We also adapt and evaluate the information extraction based evaluation proposed by Wiseman et al (2017), and show that PARENT has comparable correlation to it, while being easier to use. We show that PARENT is also applicable when the reference texts are elicited from humans using the data from the WebNLG challenge.
Text Generation with Exemplar-based Adaptive Decoding
Apr 10, 2019
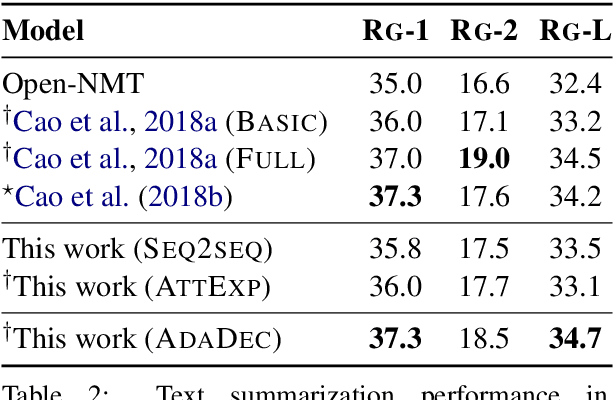
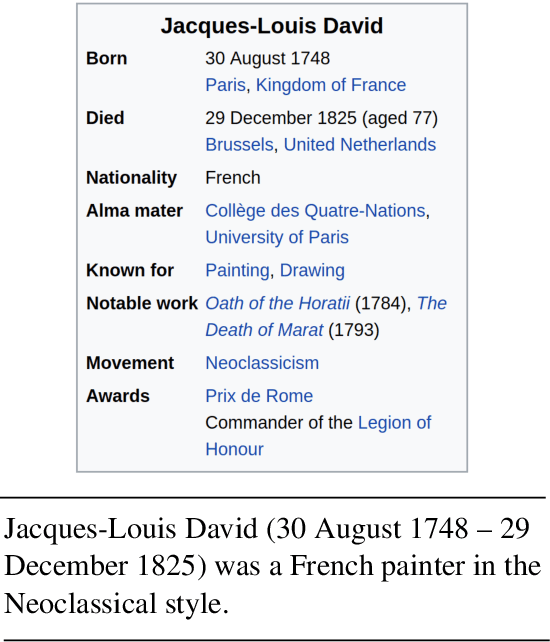
We propose a novel conditioned text generation model. It draws inspiration from traditional template-based text generation techniques, where the source provides the content (i.e., what to say), and the template influences how to say it. Building on the successful encoder-decoder paradigm, it first encodes the content representation from the given input text; to produce the output, it retrieves exemplar text from the training data as "soft templates," which are then used to construct an exemplar-specific decoder. We evaluate the proposed model on abstractive text summarization and data-to-text generation. Empirical results show that this model achieves strong performance and outperforms comparable baselines.
UniMorph 2.0: Universal Morphology
Oct 25, 2018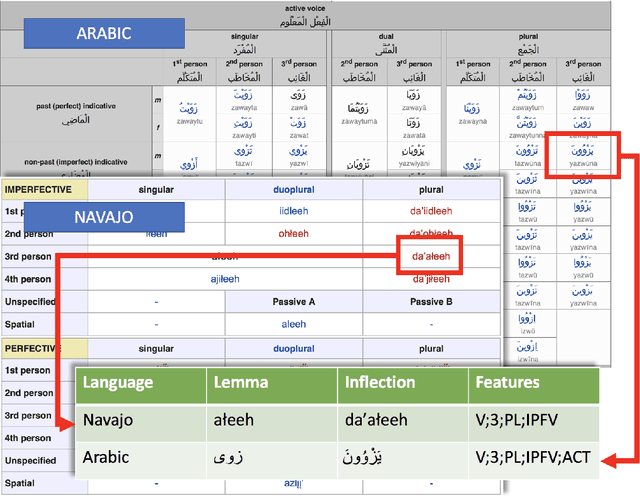
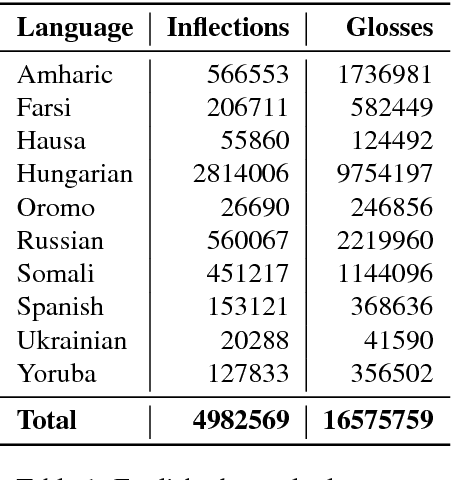

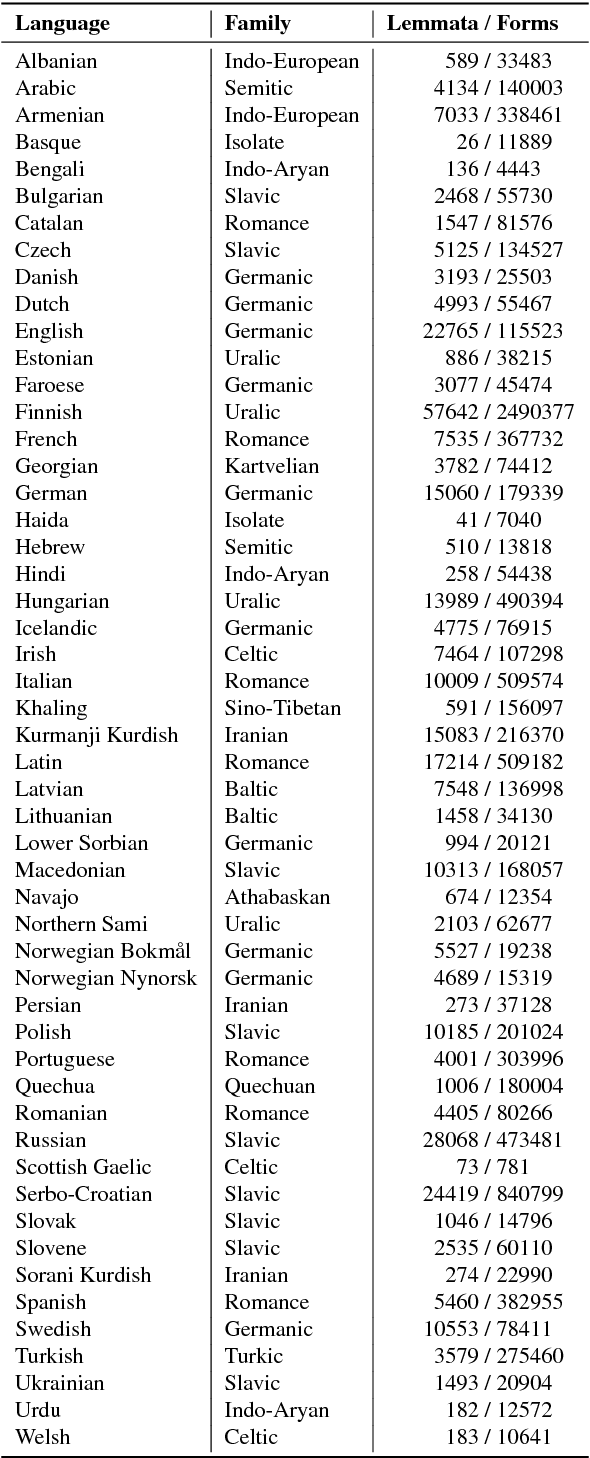
The Universal Morphology UniMorph project is a collaborative effort to improve how NLP handles complex morphology across the world's languages. The project releases annotated morphological data using a universal tagset, the UniMorph schema. Each inflected form is associated with a lemma, which typically carries its underlying lexical meaning, and a bundle of morphological features from our schema. Additional supporting data and tools are also released on a per-language basis when available. UniMorph is based at the Center for Language and Speech Processing (CLSP) at Johns Hopkins University in Baltimore, Maryland and is sponsored by the DARPA LORELEI program. This paper details advances made to the collection, annotation, and dissemination of project resources since the initial UniMorph release described at LREC 2016. lexical resources} }