 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFlowObject: Flow Steering for Bridging Generative Priors and Reconstruction Fidelity
Jun 17, 2026Recovering complete 3D representations of objects from few casual image captures remains a significant challenge. Recent 3D generative models, particularly those based on Flow-Matching (FM), can synthesize high-quality textured assets; however, they often suffer from ''synthetic bias'' where learned priors override observational evidence, alongside a lack of alignment with the observed instance. Conversely, optimization-based methods like 3D Gaussian Splatting (3DGS) provide high fidelity on visible surfaces but fail to reason about unobserved geometry. In this paper, we present FlowObject, a framework that reformulates sparse-view 3D reconstruction as a training-free, guided inverse problem. Our approach applies a dual-space guidance strategy to steer the Ordinary Differential Equation (ODE) trajectory of a flow-matching model, enabling the completion of unseen regions through learned generative priors while enforcing strict consistency with real-world observations. By integrating a 3DGS refinement stage, FlowObject further bridges the gap between ''synthetic-looking'' generative outputs and photorealistic reconstructions. Comprehensive benchmarks on synthetic and real-world datasets demonstrate that current state-of-the-art methods often struggle to achieve geometric completeness and observational consistency simultaneously, especially under severe occlusions. In contrast, our method significantly outperforms state-of-the-art generative models and optimization-based frameworks in both geometric completeness and view-dependent appearance fidelity.
CoPE-VideoLM: Codec Primitives For Efficient Video Language Models
Feb 13, 2026Video Language Models (VideoLMs) empower AI systems to understand temporal dynamics in videos. To fit to the maximum context window constraint, current methods use keyframe sampling which can miss both macro-level events and micro-level details due to the sparse temporal coverage. Furthermore, processing full images and their tokens for each frame incurs substantial computational overhead. To address these limitations, we propose to leverage video codec primitives (specifically motion vectors and residuals) which natively encode video redundancy and sparsity without requiring expensive full-image encoding for most frames. To this end, we introduce lightweight transformer-based encoders that aggregate codec primitives and align their representations with image encoder embeddings through a pre-training strategy that accelerates convergence during end-to-end fine-tuning. Our approach reduces the time-to-first-token by up to $86\%$ and token usage by up to $93\%$ compared to standard VideoLMs. Moreover, by varying the keyframe and codec primitive densities we are able to maintain or exceed performance on $14$ diverse video understanding benchmarks spanning general question answering, temporal reasoning, long-form understanding, and spatial scene understanding.
CrossOver: 3D Scene Cross-Modal Alignment
Feb 20, 2025



Multi-modal 3D object understanding has gained significant attention, yet current approaches often assume complete data availability and rigid alignment across all modalities. We present CrossOver, a novel framework for cross-modal 3D scene understanding via flexible, scene-level modality alignment. Unlike traditional methods that require aligned modality data for every object instance, CrossOver learns a unified, modality-agnostic embedding space for scenes by aligning modalities - RGB images, point clouds, CAD models, floorplans, and text descriptions - with relaxed constraints and without explicit object semantics. Leveraging dimensionality-specific encoders, a multi-stage training pipeline, and emergent cross-modal behaviors, CrossOver supports robust scene retrieval and object localization, even with missing modalities. Evaluations on ScanNet and 3RScan datasets show its superior performance across diverse metrics, highlighting adaptability for real-world applications in 3D scene understanding.
HaVQA: A Dataset for Visual Question Answering and Multimodal Research in Hausa Language
May 28, 2023



This paper presents HaVQA, the first multimodal dataset for visual question-answering (VQA) tasks in the Hausa language. The dataset was created by manually translating 6,022 English question-answer pairs, which are associated with 1,555 unique images from the Visual Genome dataset. As a result, the dataset provides 12,044 gold standard English-Hausa parallel sentences that were translated in a fashion that guarantees their semantic match with the corresponding visual information. We conducted several baseline experiments on the dataset, including visual question answering, visual question elicitation, text-only and multimodal machine translation.
SGAligner : 3D Scene Alignment with Scene Graphs
Apr 28, 2023



Building 3D scene graphs has recently emerged as a topic in scene representation for several embodied AI applications to represent the world in a structured and rich manner. With their increased use in solving downstream tasks (eg, navigation and room rearrangement), can we leverage and recycle them for creating 3D maps of environments, a pivotal step in agent operation? We focus on the fundamental problem of aligning pairs of 3D scene graphs whose overlap can range from zero to partial and can contain arbitrary changes. We propose SGAligner, the first method for aligning pairs of 3D scene graphs that is robust to in-the-wild scenarios (ie, unknown overlap -- if any -- and changes in the environment). We get inspired by multi-modality knowledge graphs and use contrastive learning to learn a joint, multi-modal embedding space. We evaluate on the 3RScan dataset and further showcase that our method can be used for estimating the transformation between pairs of 3D scenes. Since benchmarks for these tasks are missing, we create them on this dataset. The code, benchmark, and trained models are available on the project website.
HO-3D_v3: Improving the Accuracy of Hand-Object Annotations of the HO-3D Dataset
Jul 02, 2021

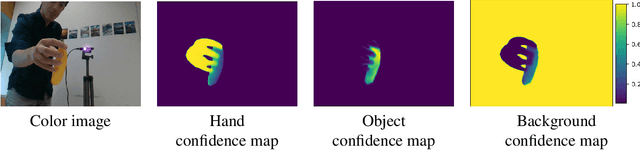
HO-3D is a dataset providing image sequences of various hand-object interaction scenarios annotated with the 3D pose of the hand and the object and was originally introduced as HO-3D_v2. The annotations were obtained automatically using an optimization method, 'HOnnotate', introduced in the original paper. HO-3D_v3 provides more accurate annotations for both the hand and object poses thus resulting in better estimates of contact regions between the hand and the object. In this report, we elaborate on the improvements to the HOnnotate method and provide evaluations to compare the accuracy of HO-3D_v2 and HO-3D_v3. HO-3D_v3 results in 4mm higher accuracy compared to HO-3D_v2 for hand poses while exhibiting higher contact regions with the object surface.
HandsFormer: Keypoint Transformer for Monocular 3D Pose Estimation ofHands and Object in Interaction
Apr 29, 2021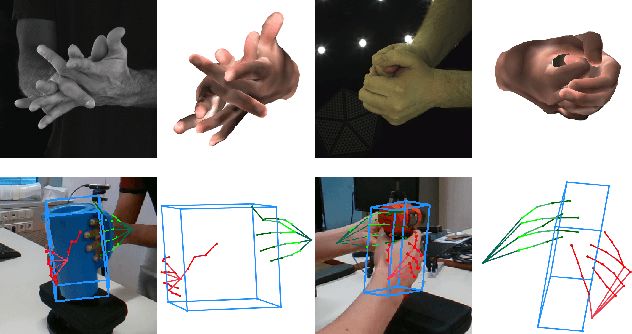
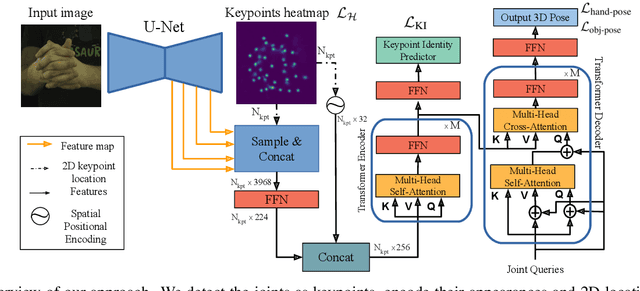

We propose a robust and accurate method for estimating the 3D poses of two hands in close interaction from a single color image. This is a very challenging problem, as large occlusions and many confusions between the joints may happen. Our method starts by extracting a set of potential 2D locations for the joints of both hands as extrema of a heatmap. We do not require that all locations correctly correspond to a joint, not that all the joints are detected. We use appearance and spatial encodings of these locations as input to a transformer, and leverage the attention mechanisms to sort out the correct configuration of the joints and output the 3D poses of both hands. Our approach thus allies the recognition power of a Transformer to the accuracy of heatmap-based methods. We also show it can be extended to estimate the 3D pose of an object manipulated by one or two hands. We evaluate our approach on the recent and challenging InterHand2.6M and HO-3D datasets. We obtain 17% improvement over the baseline. Moreover, we introduce the first dataset made of action sequences of two hands manipulating an object fully annotated in 3D and will make it publicly available.
Monte Carlo Scene Search for 3D Scene Understanding
Mar 30, 2021

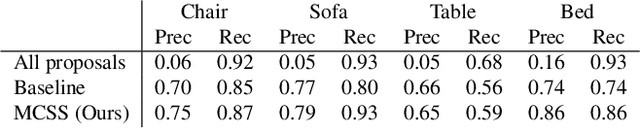
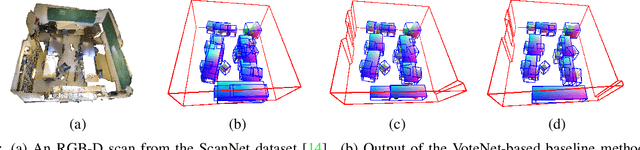
We explore how a general AI algorithm can be used for 3D scene understanding to reduce the need for training data. More exactly, we propose a modification of the Monte Carlo Tree Search (MCTS) algorithm to retrieve objects and room layouts from noisy RGB-D scans. While MCTS was developed as a game-playing algorithm, we show it can also be used for complex perception problems. Our adapted MCTS algorithm has few easy-to-tune hyperparameters and can optimise general losses. We use it to optimise the posterior probability of objects and room layout hypotheses given the RGB-D data. This results in an analysis-by-synthesis approach that explores the solution space by rendering the current solution and comparing it to the RGB-D observations. To perform this exploration even more efficiently, we propose simple changes to the standard MCTS' tree construction and exploration policy. We demonstrate our approach on the ScanNet dataset. Our method often retrieves configurations that are better than some manual annotations, especially on layouts.