 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReport from the NSF Future Directions Workshop on Automatic Evaluation of Dialog: Research Directions and Challenges
Mar 18, 2022

This is a report on the NSF Future Directions Workshop on Automatic Evaluation of Dialog. The workshop explored the current state of the art along with its limitations and suggested promising directions for future work in this important and very rapidly changing area of research.
MDD-Eval: Self-Training on Augmented Data for Multi-Domain Dialogue Evaluation
Dec 14, 2021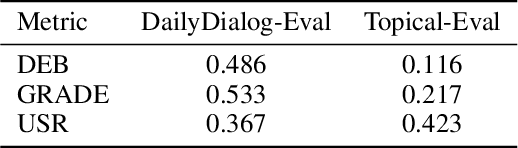
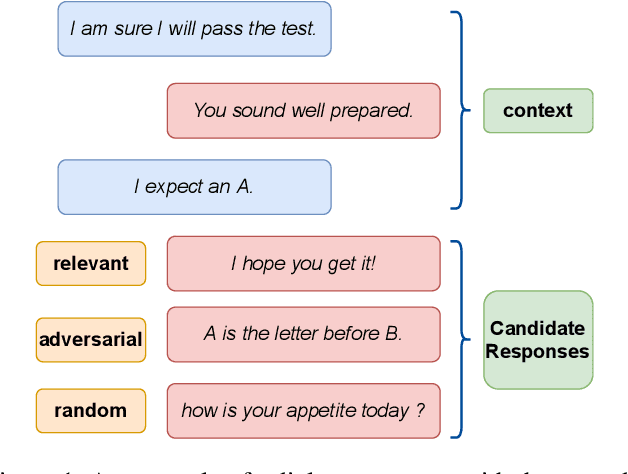
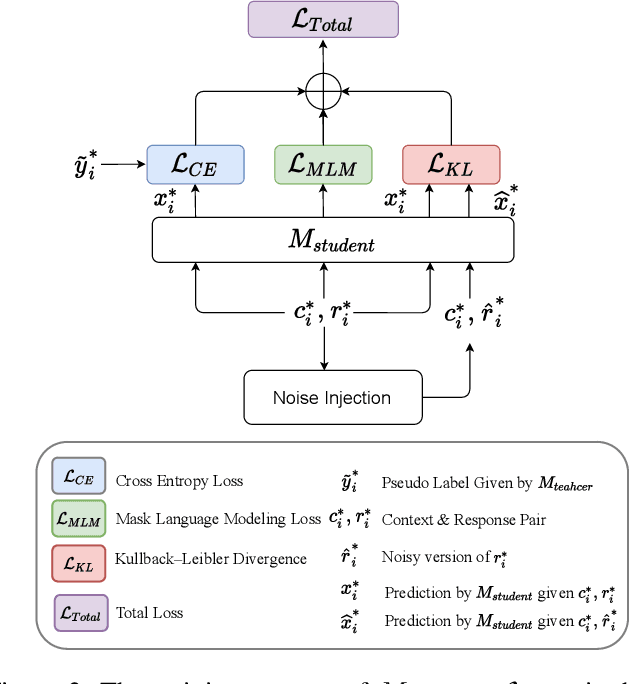
Chatbots are designed to carry out human-like conversations across different domains, such as general chit-chat, knowledge exchange, and persona-grounded conversations. To measure the quality of such conversational agents, a dialogue evaluator is expected to conduct assessment across domains as well. However, most of the state-of-the-art automatic dialogue evaluation metrics (ADMs) are not designed for multi-domain evaluation. We are motivated to design a general and robust framework, MDD-Eval, to address the problem. Specifically, we first train a teacher evaluator with human-annotated data to acquire a rating skill to tell good dialogue responses from bad ones in a particular domain and then, adopt a self-training strategy to train a new evaluator with teacher-annotated multi-domain data, that helps the new evaluator to generalize across multiple domains. MDD-Eval is extensively assessed on six dialogue evaluation benchmarks. Empirical results show that the MDD-Eval framework achieves a strong performance with an absolute improvement of 7% over the state-of-the-art ADMs in terms of mean Spearman correlation scores across all the evaluation benchmarks.
Automatic Evaluation and Moderation of Open-domain Dialogue Systems
Nov 20, 2021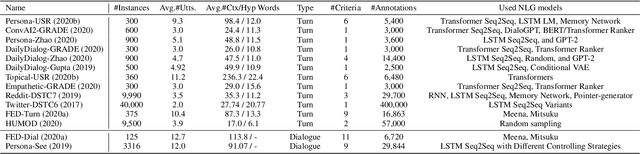


The development of Open-Domain Dialogue Systems (ODS)is a trending topic due to the large number of research challenges, large societal and business impact, and advances in the underlying technology. However, the development of these kinds of systems requires two important characteristics:1) automatic evaluation mechanisms that show high correlations with human judgements across multiple dialogue evaluation aspects (with explainable features for providing constructive and explicit feedback on the quality of generative models' responses for quick development and deployment)and 2) mechanisms that can help to control chatbot responses,while avoiding toxicity and employing intelligent ways to handle toxic user comments and keeping interaction flow and engagement. This track at the 10th Dialogue System Technology Challenge (DSTC10) is part of the ongoing effort to promote scalable and toxic-free ODS. This paper describes the datasets and baselines provided to participants, as well as submission evaluation results for each of the two proposed subtasks
Investigating the Impact of Pre-trained Language Models on Dialog Evaluation
Oct 05, 2021

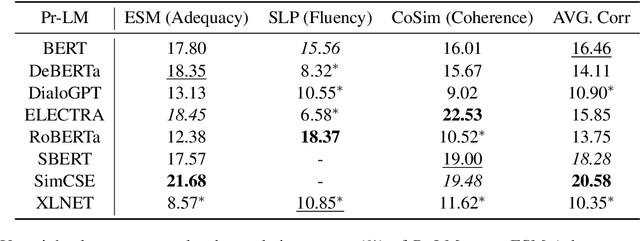
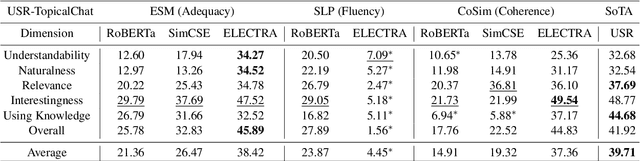
Recently, there is a surge of interest in applying pre-trained language models (Pr-LM) in automatic open-domain dialog evaluation. Pr-LMs offer a promising direction for addressing the multi-domain evaluation challenge. Yet, the impact of different Pr-LMs on the performance of automatic metrics is not well-understood. This paper examines 8 different Pr-LMs and studies their impact on three typical automatic dialog evaluation metrics across three different dialog evaluation benchmarks. Specifically, we analyze how the choice of Pr-LMs affects the performance of automatic metrics. Extensive correlation analyses on each of the metrics are performed to assess the effects of different Pr-LMs along various axes, including pre-training objectives, dialog evaluation criteria, model size, and cross-dataset robustness. This study serves as the first comprehensive assessment of the effects of different Pr-LMs on automatic dialog evaluation.
DynaEval: Unifying Turn and Dialogue Level Evaluation
Jun 06, 2021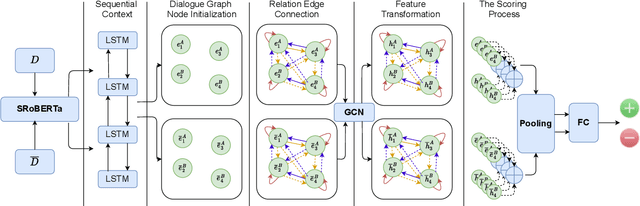
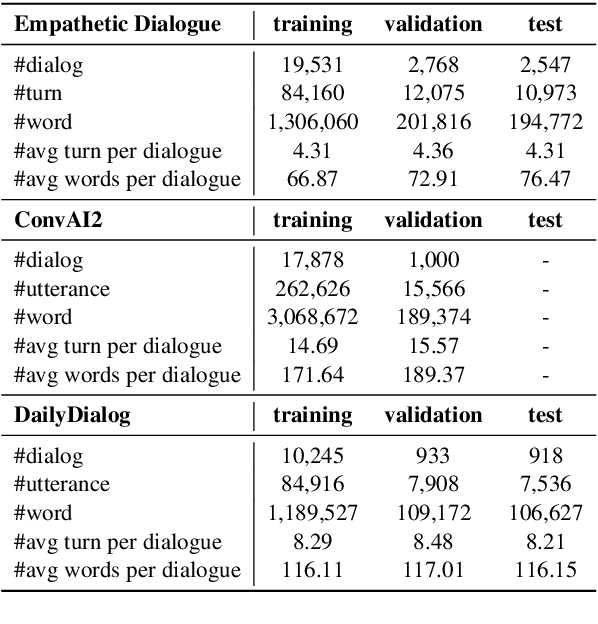
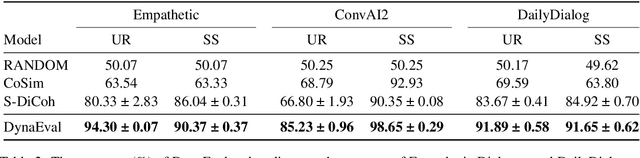
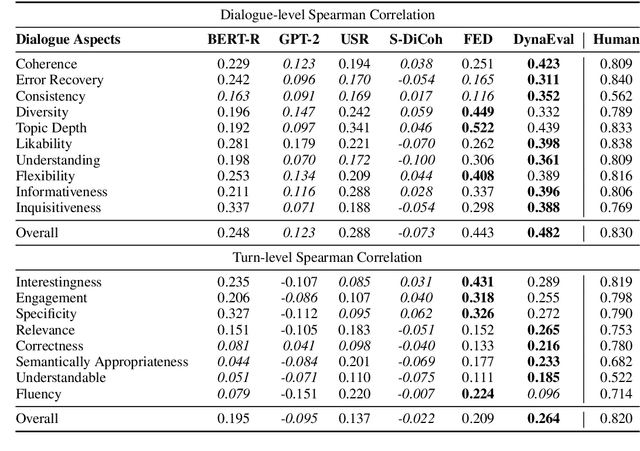
A dialogue is essentially a multi-turn interaction among interlocutors. Effective evaluation metrics should reflect the dynamics of such interaction. Existing automatic metrics are focused very much on the turn-level quality, while ignoring such dynamics. To this end, we propose DynaEval, a unified automatic evaluation framework which is not only capable of performing turn-level evaluation, but also holistically considers the quality of the entire dialogue. In DynaEval, the graph convolutional network (GCN) is adopted to model a dialogue in totality, where the graph nodes denote each individual utterance and the edges represent the dependency between pairs of utterances. A contrastive loss is then applied to distinguish well-formed dialogues from carefully constructed negative samples. Experiments show that DynaEval significantly outperforms the state-of-the-art dialogue coherence model, and correlates strongly with human judgements across multiple dialogue evaluation aspects at both turn and dialogue level.
Overview of the Ninth Dialog System Technology Challenge: DSTC9
Nov 12, 2020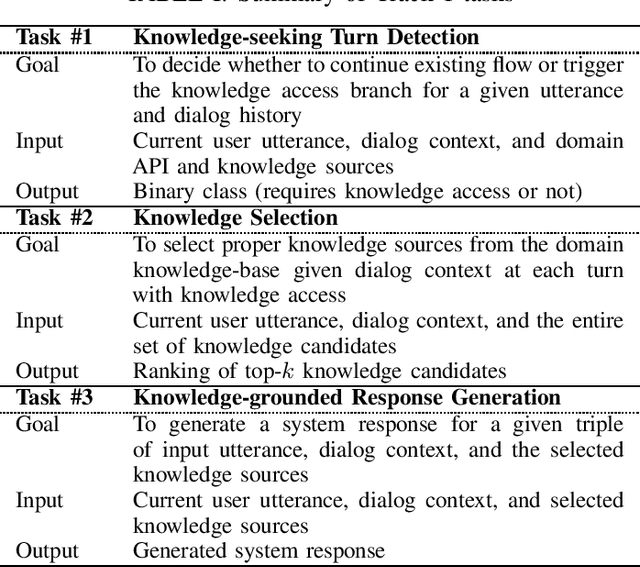
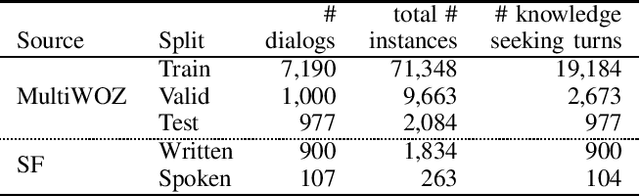

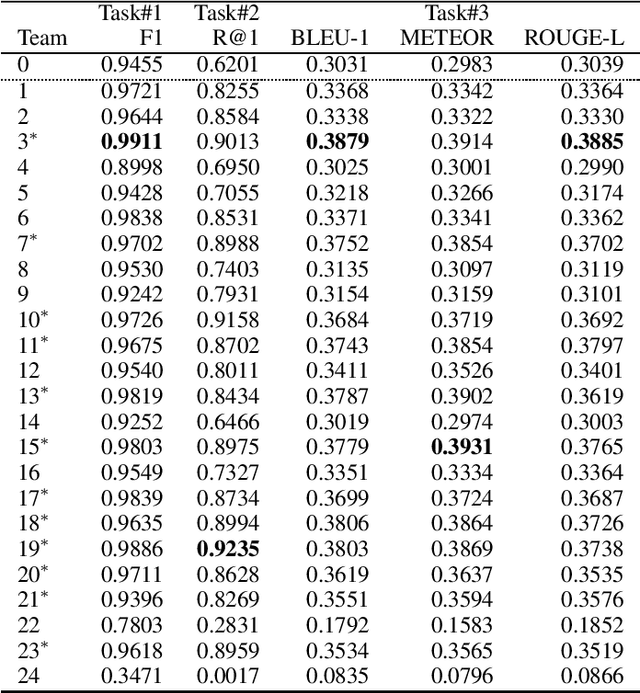
This paper introduces the Ninth Dialog System Technology Challenge (DSTC-9). This edition of the DSTC focuses on applying end-to-end dialog technologies for four distinct tasks in dialog systems, namely, 1. Task-oriented dialog Modeling with unstructured knowledge access, 2. Multi-domain task-oriented dialog, 3. Interactive evaluation of dialog, and 4. Situated interactive multi-modal dialog. This paper describes the task definition, provided datasets, baselines and evaluation set-up for each track. We also summarize the results of the submitted systems to highlight the overall trends of the state-of-the-art technologies for the tasks.
Joint Learning of Word and Label Embeddings for Sequence Labelling in Spoken Language Understanding
Oct 16, 2019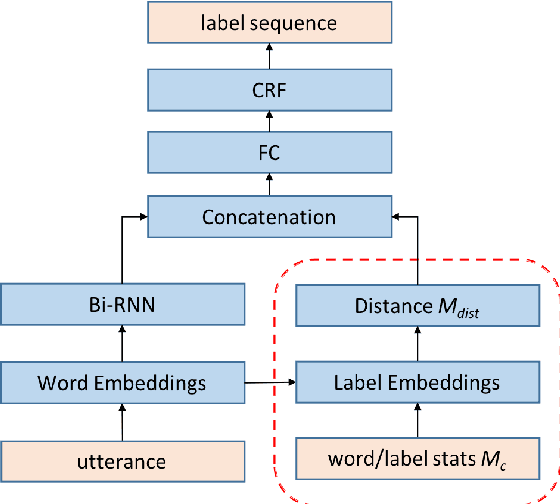
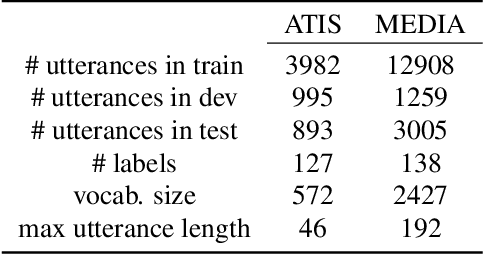
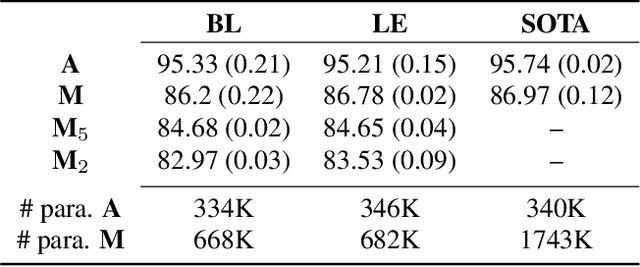

We propose an architecture to jointly learn word and label embeddings for slot filling in spoken language understanding. The proposed approach encodes labels using a combination of word embeddings and straightforward word-label association from the training data. Compared to the state-of-the-art methods, our approach does not require label embeddings as part of the input and therefore lends itself nicely to a wide range of model architectures. In addition, our architecture computes contextual distances between words and labels to avoid adding contextual windows, thus reducing memory footprint. We validate the approach on established spoken dialogue datasets and show that it can achieve state-of-the-art performance with much fewer trainable parameters.
Dialog System Technology Challenge 7
Jan 11, 2019

This paper introduces the Seventh Dialog System Technology Challenges (DSTC), which use shared datasets to explore the problem of building dialog systems. Recently, end-to-end dialog modeling approaches have been applied to various dialog tasks. The seventh DSTC (DSTC7) focuses on developing technologies related to end-to-end dialog systems for (1) sentence selection, (2) sentence generation and (3) audio visual scene aware dialog. This paper summarizes the overall setup and results of DSTC7, including detailed descriptions of the different tracks and provided datasets. We also describe overall trends in the submitted systems and the key results. Each track introduced new datasets and participants achieved impressive results using state-of-the-art end-to-end technologies.
End-to-End Video Classification with Knowledge Graphs
Nov 06, 2017

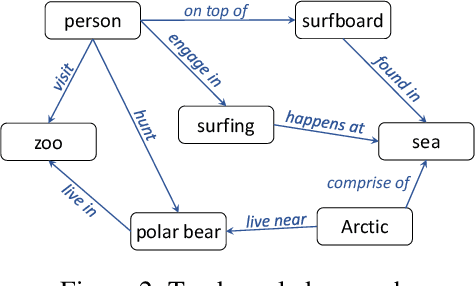

Video understanding has attracted much research attention especially since the recent availability of large-scale video benchmarks. In this paper, we address the problem of multi-label video classification. We first observe that there exists a significant knowledge gap between how machines and humans learn. That is, while current machine learning approaches including deep neural networks largely focus on the representations of the given data, humans often look beyond the data at hand and leverage external knowledge to make better decisions. Towards narrowing the gap, we propose to incorporate external knowledge graphs into video classification. In particular, we unify traditional "knowledgeless" machine learning models and knowledge graphs in a novel end-to-end framework. The framework is flexible to work with most existing video classification algorithms including state-of-the-art deep models. Finally, we conduct extensive experiments on the largest public video dataset YouTube-8M. The results are promising across the board, improving mean average precision by up to 2.9%.
Truly Multi-modal YouTube-8M Video Classification with Video, Audio, and Text
Jul 10, 2017
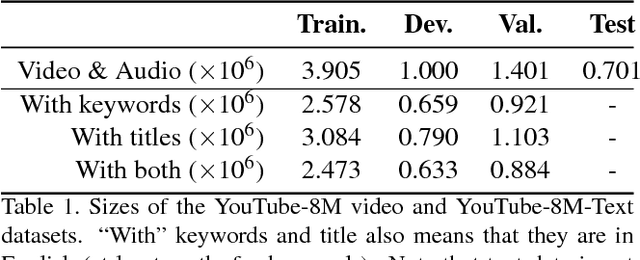

The YouTube-8M video classification challenge requires teams to classify 0.7 million videos into one or more of 4,716 classes. In this Kaggle competition, we placed in the top 3% out of 650 participants using released video and audio features. Beyond that, we extend the original competition by including text information in the classification, making this a truly multi-modal approach with vision, audio and text. The newly introduced text data is termed as YouTube-8M-Text. We present a classification framework for the joint use of text, visual and audio features, and conduct an extensive set of experiments to quantify the benefit that this additional mode brings. The inclusion of text yields state-of-the-art results, e.g. 86.7% GAP on the YouTube-8M-Text validation dataset.