 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerative-Evaluative Agreement: A Necessary Validity Criterion for LLM-Enabled Adaptive Assessment
May 19, 2026When the same LLM generates assessment items, simulates student responses, and scores them, the validation loop is self-referential. We introduce Generative-Evaluative Agreement (GEA), a validity criterion measuring whether an LLM's scoring function recovers the skill levels its generative function was instructed to produce. In the first direct measurement of GEA on a two-stage adaptive assessment, the model recovers roughly half the intended variance r = 0.698 with systematic positive bias. GEA is strong r > 0.7 for syntactically verifiable skills but near zero for design-level skills, and low-skill overestimation inflates scores near the routing threshold. We argue that granular, skill-decomposed rubrics are the principal proposed mechanism for strengthening GEA and outline complementary mitigations.
Decipherment-Aware Multilingual Learning in Jointly Trained Language Models
Jun 11, 2024The principle that governs unsupervised multilingual learning (UCL) in jointly trained language models (mBERT as a popular example) is still being debated. Many find it surprising that one can achieve UCL with multiple monolingual corpora. In this work, we anchor UCL in the context of language decipherment and show that the joint training methodology is a decipherment process pivotal for UCL. In a controlled setting, we investigate the effect of different decipherment settings on the multilingual learning performance and consolidate the existing opinions on the contributing factors to multilinguality. From an information-theoretic perspective we draw a limit to the UCL performance and demonstrate the importance of token alignment in challenging decipherment settings caused by differences in the data domain, language order and tokenization granularity. Lastly, we apply lexical alignment to mBERT and investigate the contribution of aligning different lexicon groups to downstream performance.
Beyond Single-Event Extraction: Towards Efficient Document-Level Multi-Event Argument Extraction
May 03, 2024



Recent mainstream event argument extraction methods process each event in isolation, resulting in inefficient inference and ignoring the correlations among multiple events. To address these limitations, here we propose a multiple-event argument extraction model DEEIA (Dependency-guided Encoding and Event-specific Information Aggregation), capable of extracting arguments from all events within a document simultaneouslyThe proposed DEEIA model employs a multi-event prompt mechanism, comprising DE and EIA modules. The DE module is designed to improve the correlation between prompts and their corresponding event contexts, whereas the EIA module provides event-specific information to improve contextual understanding. Extensive experiments show that our method achieves new state-of-the-art performance on four public datasets (RAMS, WikiEvents, MLEE, and ACE05), while significantly saving the inference time compared to the baselines. Further analyses demonstrate the effectiveness of the proposed modules.
Revisiting Self-Training for Few-Shot Learning of Language Model
Oct 04, 2021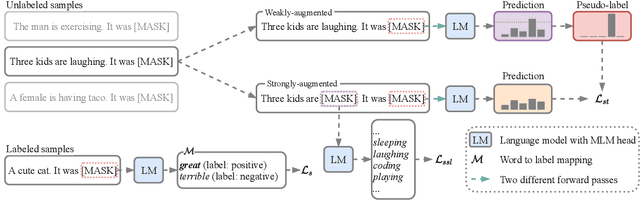
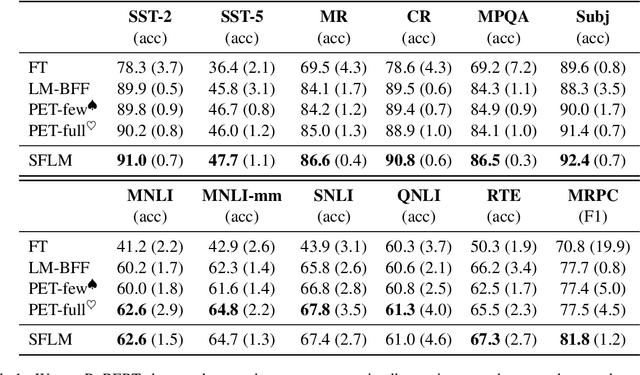
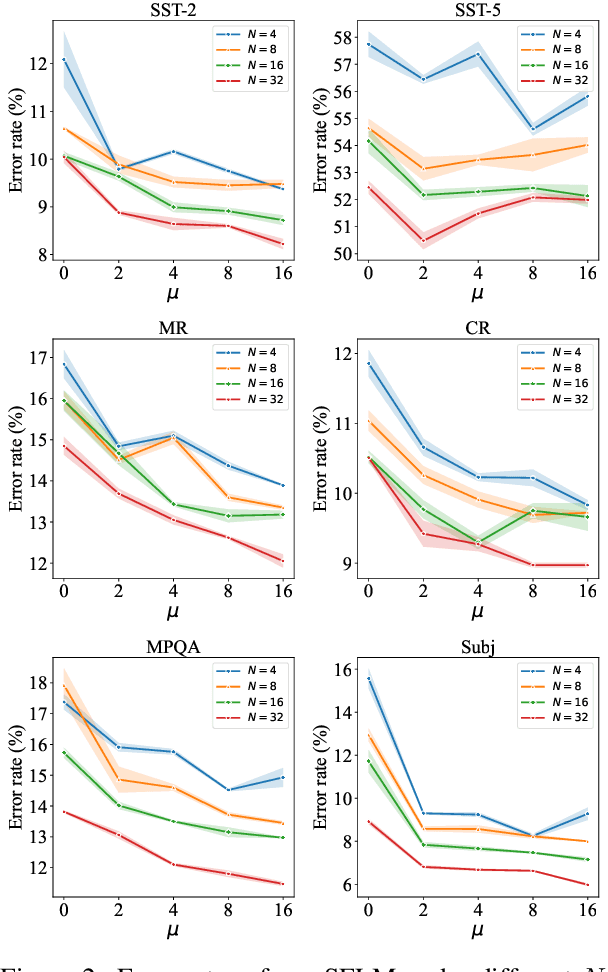
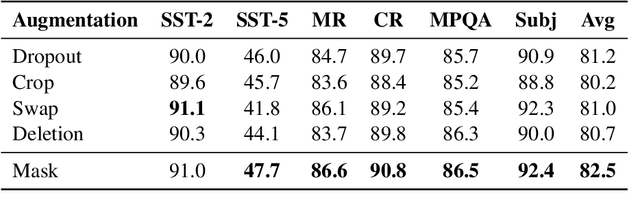
As unlabeled data carry rich task-relevant information, they are proven useful for few-shot learning of language model. The question is how to effectively make use of such data. In this work, we revisit the self-training technique for language model fine-tuning and present a state-of-the-art prompt-based few-shot learner, SFLM. Given two views of a text sample via weak and strong augmentation techniques, SFLM generates a pseudo label on the weakly augmented version. Then, the model predicts the same pseudo label when fine-tuned with the strongly augmented version. This simple approach is shown to outperform other state-of-the-art supervised and semi-supervised counterparts on six sentence classification and six sentence-pair classification benchmarking tasks. In addition, SFLM only relies on a few in-domain unlabeled data. We conduct a comprehensive analysis to demonstrate the robustness of our proposed approach under various settings, including augmentation techniques, model scale, and few-shot knowledge transfer across tasks.
DynaEval: Unifying Turn and Dialogue Level Evaluation
Jun 06, 2021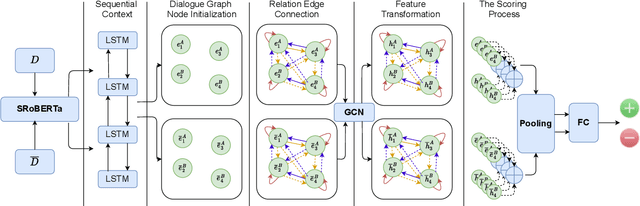
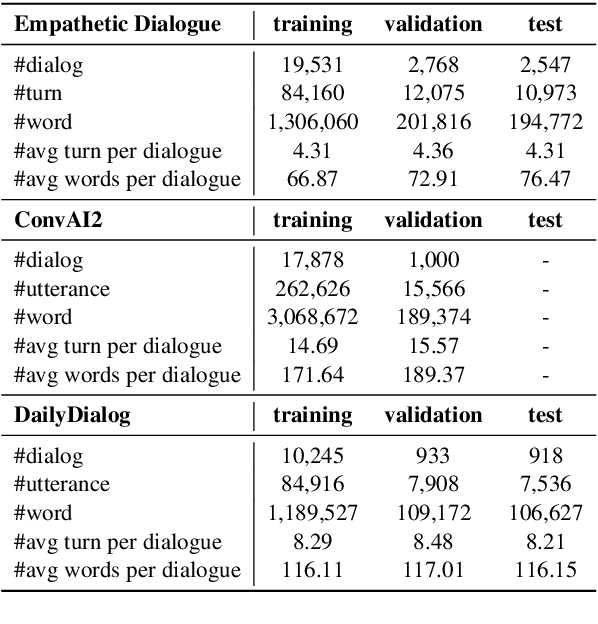
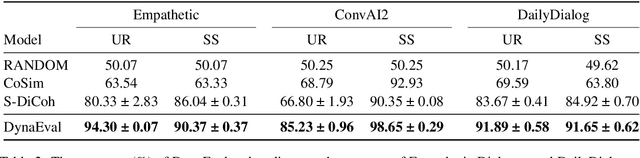
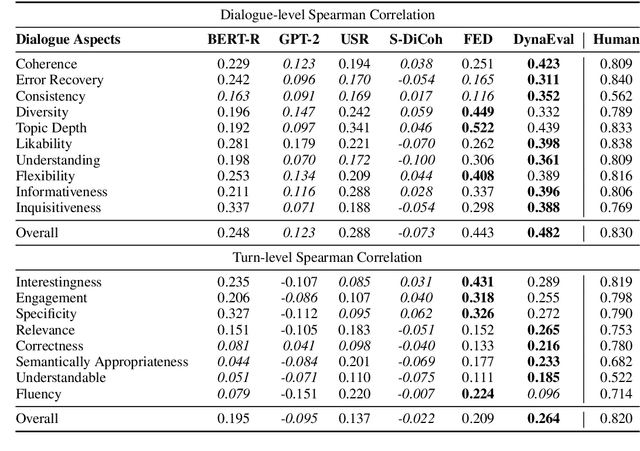
A dialogue is essentially a multi-turn interaction among interlocutors. Effective evaluation metrics should reflect the dynamics of such interaction. Existing automatic metrics are focused very much on the turn-level quality, while ignoring such dynamics. To this end, we propose DynaEval, a unified automatic evaluation framework which is not only capable of performing turn-level evaluation, but also holistically considers the quality of the entire dialogue. In DynaEval, the graph convolutional network (GCN) is adopted to model a dialogue in totality, where the graph nodes denote each individual utterance and the edges represent the dependency between pairs of utterances. A contrastive loss is then applied to distinguish well-formed dialogues from carefully constructed negative samples. Experiments show that DynaEval significantly outperforms the state-of-the-art dialogue coherence model, and correlates strongly with human judgements across multiple dialogue evaluation aspects at both turn and dialogue level.
End-to-End Code-Switching ASR for Low-Resourced Language Pairs
Sep 30, 2019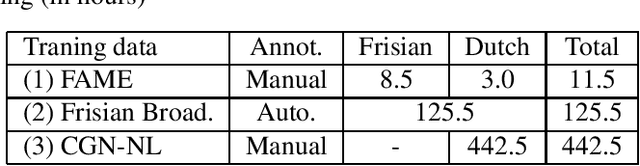
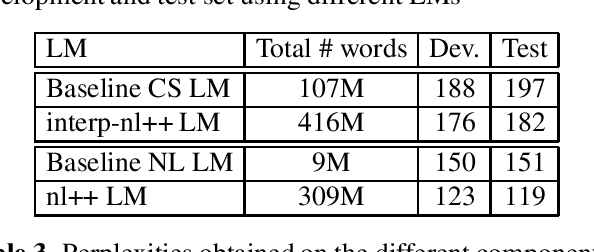
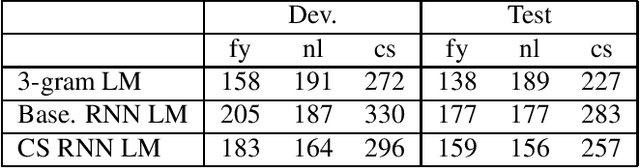
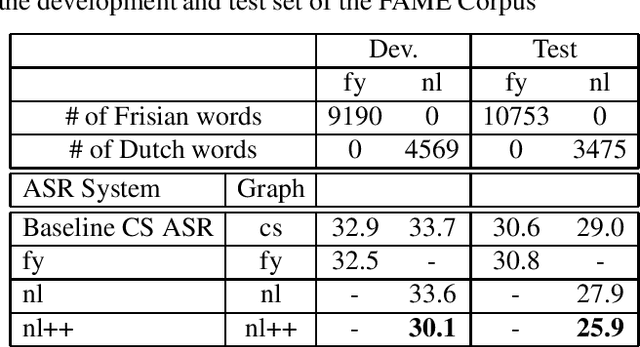
Despite the significant progress in end-to-end (E2E) automatic speech recognition (ASR), E2E ASR for low resourced code-switching (CS) speech has not been well studied. In this work, we describe an E2E ASR pipeline for the recognition of CS speech in which a low-resourced language is mixed with a high resourced language. Low-resourcedness in acoustic data hinders the performance of E2E ASR systems more severely than the conventional ASR systems.~To mitigate this problem in the transcription of archives with code-switching Frisian-Dutch speech, we integrate a designated decoding scheme and perform rescoring with neural network-based language models to enable better utilization of the available textual resources. We first incorporate a multi-graph decoding approach which creates parallel search spaces for each monolingual and mixed recognition tasks to maximize the utilization of the textual resources from each language. Further, language model rescoring is performed using a recurrent neural network pre-trained with cross-lingual embedding and further adapted with the limited amount of in-domain CS text. The ASR experiments demonstrate the effectiveness of the described techniques in improving the recognition performance of an E2E CS ASR system in a low-resourced scenario.